A Benchmark Study of Machine Learning Models for Online Fake News Detection¶
Authors: Junaed Younus Khan, Md. Tawkat Islam Khondaker, Sadia Afroz, Gias Uddin, Anindya Iqbal
Venue: arXiv:1905.04749, March 29, 2021
URL: https://arxiv.org/abs/1905.04749
TL;DR¶
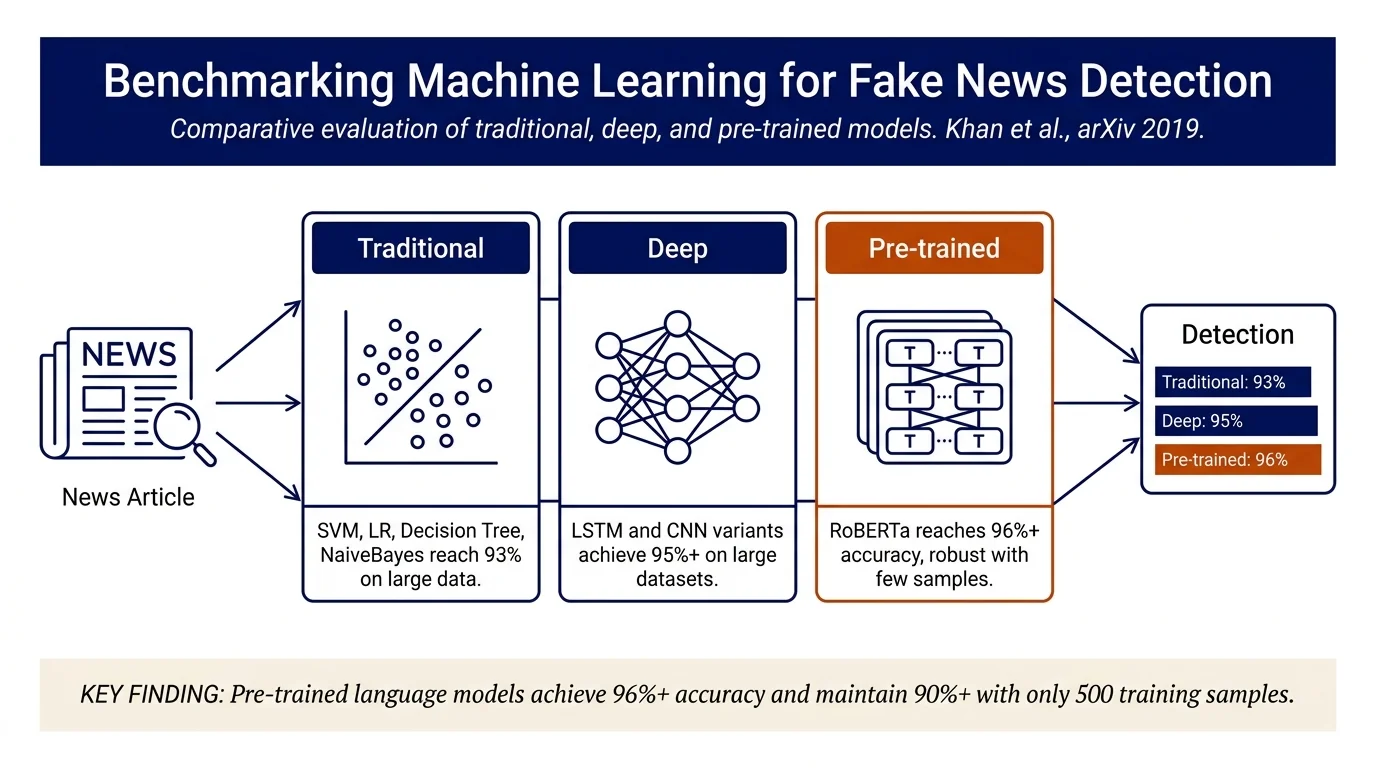
Comprehensive benchmark of 19 machine learning approaches across three fake news datasets (LIAR, Fake or Real News, and an 80k-news combined corpus spanning politics, health, sports, and other topics). Key finding: BERT-based pre-trained models (especially RoBERTa) substantially outperform traditional and deep learning approaches, achieving 96%+ accuracy on large datasets and 90%+ even with only 500 training samples, making them the recommended choice for practical fake news detection.
Contributions¶
- Evaluation of 8 traditional machine learning models (SVM, LR, Decision Tree, AdaBoost, Naive Bayes, k-NN) with lexical and sentiment features
- Evaluation of 6 deep learning architectures (CNN, LSTM, Bi-LSTM, C-LSTM, HAN, Convolutional HAN) with GloVe embeddings
- Evaluation of 5 pre-trained language models (BERT, RoBERTa, DistilBERT, ELECTRA, ELMo) for transfer learning
- Creation of a combined corpus of 80k news articles covering diverse topics beyond politics
- Analysis of model performance under limited training data constraints
- Investigation of feature importance and error patterns across model types
Method¶
Datasets: - LIAR: 12,791 political statements (5,657 false, 7,134 true) with binary classification - Fake or Real News: 6,335 news articles (3,164 fake, 3,171 real) from 2016 US election coverage - Combined Corpus: 79,548 articles (38,859 fake, 40,689 real) from 2015–2017, manually labeled across 10 topic clusters (US election 2016, politics, economy, health & research, terrorism, justice, sports, entertainment, urban, miscellaneous)
Feature engineering: - Lexical features: word count, average word length, character count, parts-of-speech counts, exclamation marks - Sentiment features: positive and negative polarity per article - n-gram features: unigrams and bigrams (TF-IDF) - Empath-generated features: emotion and social categories (violence, crime, pride, sympathy, etc.) - Pre-trained embeddings: 100-dimensional GloVe for neural models
Model architectures: Traditional ML: trained with lexical + sentiment + n-gram features Deep learning: CNN (128 filters, pool size 2); LSTM/Bi-LSTM/C-LSTM with 100-dimensional word embeddings and 300 timesteps; HAN (hierarchical word and sentence encoding); Conv-HAN (combining 1D convolution with attention) Pre-trained models: fine-tuned with a single linear classification head (300 max sequence length, early stopping to prevent overfitting)
Evaluation: 80/20 train-test split; metrics include accuracy, precision, recall, F1-score (macro-averaged for both classes). For the balanced dataset (Combined Corpus), stratified sampling ensured proportional topic distribution in train and test sets.
Results¶
RQ1—Traditional vs. Deep Learning: Deep learning outperforms traditional ML, especially on large datasets. Naive Bayes with n-grams achieves 93% on the combined corpus but only 60% on LIAR (small dataset). Deep models (Bi-LSTM, C-LSTM) reach 95%+ accuracy on combined corpus.
RQ2—Pre-trained Language Models: Pre-trained models substantially outperform both baselines: - RoBERTa: 96% accuracy on combined corpus, 98% on Fake or Real News, 62% on LIAR - BERT (base): 95% combined, 96% fake-or-real, 62% LIAR - DistilBERT: 93% combined, 95% fake-or-real, 60% LIAR (more efficient, suitable for production) - ELECTRA: 95% combined, 96% fake-or-real, 61% LIAR - ELMo: 91% combined, 93% fake-or-real, 61% LIAR
RQ3—Small Data Regime: Pre-trained BERT models achieve over 90% accuracy on the Fake or Real News dataset with only 500 training samples; RoBERTa reaches 84% with 300 samples. In contrast, Naive Bayes plateaus at ~65% and Bi-LSTM at ~75% in the same small-sample setting. This advantage persists across datasets of different lengths and topics.
Key observations: - Sentiment and n-gram features do not improve fake news detection; classification depends on content semantics - Article length correlates strongly with model performance (18 words for LIAR vs. 644 words for combined corpus) - Topic-dependent false positive rates: 49.6% for health & research, 27.6% for politics, 22.8% miscellaneous topics - LSTM variants show high overfitting on small datasets; pre-trained models mitigate this via transfer learning - DistilBERT provides 93% combined accuracy with fewer parameters (66M) and lower training time than full BERT/RoBERTa, making it practical for resource-constrained deployments
Connections¶
- Extends the empirical comparison framework in A Survey on Natural Language Processing for Fake News Detection with transformer-based models
- Uses the LIAR dataset introduced in Liar, Liar Pants on Fire: A New Benchmark Dataset for Fake News Detection
- Builds on deep learning methods from EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection and MVAE: Multimodal Variational Autoencoder for Fake News Detection
- Informs the pre-trained language model landscape surveyed in A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities
- Complements dataset-focused work like FakeNewsNet: A Data Repository with News Content, Social Context and Spatiotemporal Information for Studying Fake News on Social Media and r/Fakeddit: A New Multimodal Benchmark Dataset for Fine-grained Fake News Detection
Notes¶
Strengths: Comprehensive empirical evaluation across multiple model families (traditional, deep, pre-trained) on three diverse datasets of different sizes and topics. The combined corpus (80k articles from multiple sources and topics) is notably larger and more diverse than prior benchmarks, reducing dataset bias concerns. Small-sample analysis (RQ3) is practically valuable for low-resource settings. Clear ablation (sentiment features don't help) and direct comparison of resource requirements (DistilBERT vs. BERT).
Limitations: ArXiv preprint (not peer-reviewed). LIAR's small articles (18 words) may not reflect realistic news for downstream applications. Focuses narrowly on text content; doesn't explore metadata (speaker credibility, social signals, source reputation) which are known to matter. No analysis of cross-dataset generalization (train on LIAR, test on Fake or Real News) to assess transfer learning beyond pre-trained weights. No error analysis beyond topic-wise false positive rates. Code published on GitHub but reproducibility concerns for older systems.
Relevance to the field: Timely (2021) comparison of transformer models for fake news, settling the practical question of which approach to use when. Pre-trained BERT results support the broader trend in NLP toward transfer learning. The small-sample finding is crucial for practitioners in low-resource languages or emerging regions, where pre-trained models are particularly valuable.