A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities¶
Authors: Xinyi Zhou, Reza Zafarani Venue: ACM Computing Surveys, Vol. 1, Article 1, January 2020 arXiv: 1812.00315
TL;DR¶
This comprehensive survey defines fake news across both broad and narrow framings, systematizes detection methods across four perspectives (knowledge, style, propagation, source), connects detection strategies to interdisciplinary theories from psychology and social sciences, and identifies six open research challenges including early detection, cross-domain analysis, and explainability.
Contributions¶
- Definitional framework distinguishing fake news from related concepts (deceptive news, satire, misinformation, disinformation, clickbait, rumor) using three properties: authenticity, intention, and whether content is news
- Fundamental theories catalog from psychology, economics, and social sciences explaining how fake news is created and spreads
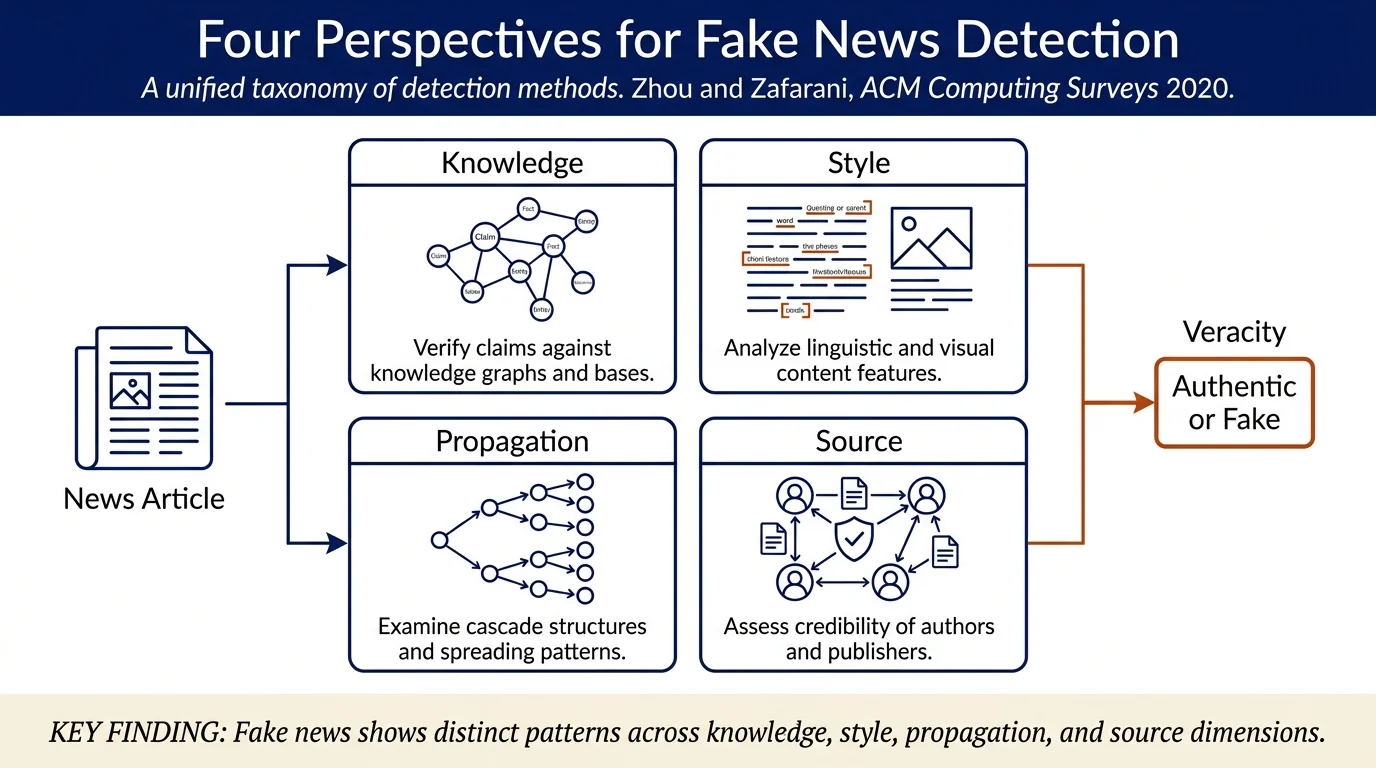
- Four-perspective taxonomy for detection methods:
- Knowledge-based: fact-checking via knowledge graphs and knowledge base construction
- Style-based: linguistic and visual features distinguishing fake from true news
- Propagation-based: cascade structures and network patterns in news dissemination
- Source-based: author/publisher/user credibility assessment
- Open research challenges including detection of non-traditional fake news, early detection, identifying check-worthy content, cross-domain analysis, explainability, and intervention strategies
Method¶
The survey is organized around four detection perspectives, each examining how fake news differs from truth:
Knowledge-based detection (Section 2) verifies news claims against ground-truth facts. Manual fact-checking relies on expert or crowd-sourced annotators. Automatic fact-checking uses knowledge graphs (KGs) constructed from open web sources or closed knowledge bases. The process involves (i) fact extraction from the news article as SPO triples, (ii) knowledge base construction addressing redundancy, invalidity, conflicts, and unreliability, and (iii) fact-checking through entity resolution and link prediction.
Style-based detection (Section 3) analyzes linguistic and visual characteristics of news content. Textual features span general features (lexicon, syntax, discourse) and latent features (word/sentence embeddings). Visual features include clarity, coherence, diversity, and clustering scores. Models range from traditional machine learning (SVMs, random forests) on hand-crafted features to deep learning (CNNs, RNNs, Transformers) on learned representations.
Propagation-based detection (Section 4) analyzes how news spreads. News cascades are tree-like structures capturing retweet/sharing chains; time-based and hop-based cascades enable feature engineering on depth, breadth, spread speed, etc. Self-defined propagation graphs model heterogeneous networks of publishers, users, and articles, capturing relationships like following, credibility scoring, and political bias. Features from both are used with traditional ML or RNNs to classify news veracity.
Source-based detection (Section 5) assesses credibility of news sources. Author/publisher patterns reveal homogeneity in collaboration networks of true vs. fake news publishers. Web spam detection uses PageRank, HITS, and content-based algorithms to identify unreliable publishers. User-level assessment identifies malicious social bots and vulnerable normal users who spread fake news more readily than others.
Results¶
Key findings across detection perspectives:
-
Knowledge-based: Manual fact-checking is accurate but slow and expensive; automatic approaches scale but depend on knowledge base completeness. Existing websites (PolitiFact, FactCheck, Snopes) provide ground truth for dataset construction.
-
Style-based: Non-latent features (lexicon, rewrite rules, frequencies) often outperform latent ones in traditional ML settings; combining features across levels improves performance. Fake news text shows higher informality, diversity, subjectivity, and emotional word usage. Fake news images show higher clarity and coherence, lower diversity.
-
Propagation-based: Fake news cascades spread faster, wider, more popular, and reach greater depth than true news cascades. Fake news spreads further among normal users; structural patterns differ significantly (farther distance, more spreaders, stronger engagement).
-
Source-based: True news authors/publishers form denser collaboration networks with clearer community structure than fake news authors. Publisher networks reveal five distinct communities (Russian/conspiracy, right-wing/conspiracy, U.S. mainstream, left-wing blog, U.K. mainstream). Social bots spread unreliable news at higher rates; vulnerable normal users are susceptible to social influence and confirmation bias.
Connections¶
- Related to Network-based Fake News Detection which applies graph-based cascade analysis to propagation patterns
- Extends style-based work in Linguistic-style-aware Neural Networks for Fake News Detection
- Cited by Fake News Early Detection: An Interdisciplinary Study which builds on the theoretical framework
- Shares datasets with The Role of User Profiles for Fake News Detection and Credibility-based Fake News Detection
Notes¶
Strengths: - Uniquely comprehensive across four detection perspectives rather than limiting to one approach - Grounded in interdisciplinary theories from psychology, economics, and social sciences rather than purely computational - Clear problem formulations (Problems 1–7) with notation for fact-checking, cascade classification, etc. - Extensive tables and figures (17 figures, multiple comparison tables) documenting datasets, features, and detection website examples - Accessible definitions and visual lifecycle diagram showing how fake news creation, publication, propagation, and source stages map to detection methods
Weaknesses: - Published in early 2020; misses rapid recent advances in multimodal detection and transformer-based models (though acknowledged that deep learning coverage was developing) - Some design trade-offs not deeply discussed (e.g., why broad vs. narrow fake news definition affects practical deployment) - Detection methods evaluated on different datasets, making cross-method comparison difficult - Early detection challenge identified but not solved; temporal dynamics of fake news style evolution underexplored
Follow-up opportunities: - Integration of multiple perspectives (knowledge + style + propagation) for robust detection - Development of dynamic knowledge graphs supporting real-time updates and early detection - Explainability: connecting detection model decisions back to fundamental theories or domain expertise - Cross-domain and cross-language fake news analysis beyond English-language political news - User intervention strategies tailored to vulnerable vs. malicious users