A Survey on Natural Language Processing for Fake News Detection¶
Authors: Ray Oshikawa, Jing Qian, William Yang Wang
Venue: arXiv:1811.00770v2, March 5, 2020
URL: https://arxiv.org/abs/1811.00770
TL;DR¶
This survey comprehensively reviews NLP methods for fake news detection, systematically comparing task formulations (classification vs. regression), nine benchmark datasets (LIAR, FEVER, FakeNewsNet, Twitter/SNS datasets), and five methodological approaches (preprocessing, machine learning models, rhetorical structure, evidence collection, and meta-data exploitation). Key finding: attention-based LSTM models achieve highest accuracy; neural approaches outperform hand-crafted linguistic features, but meta-data (speaker credibility, social engagement) remains critical for robust detection.
Contributions¶
- First comprehensive NLP-focused survey of automated fake news detection with systematic comparison of task definitions, datasets, and solutions
- Nine benchmark datasets categorized by input type: short claims (LIAR, FEVER, EMERGENT), entire articles (FakeNewsNet, BS Detector), and SNS data (BuzzFeedNews, PHEME, CredBank)
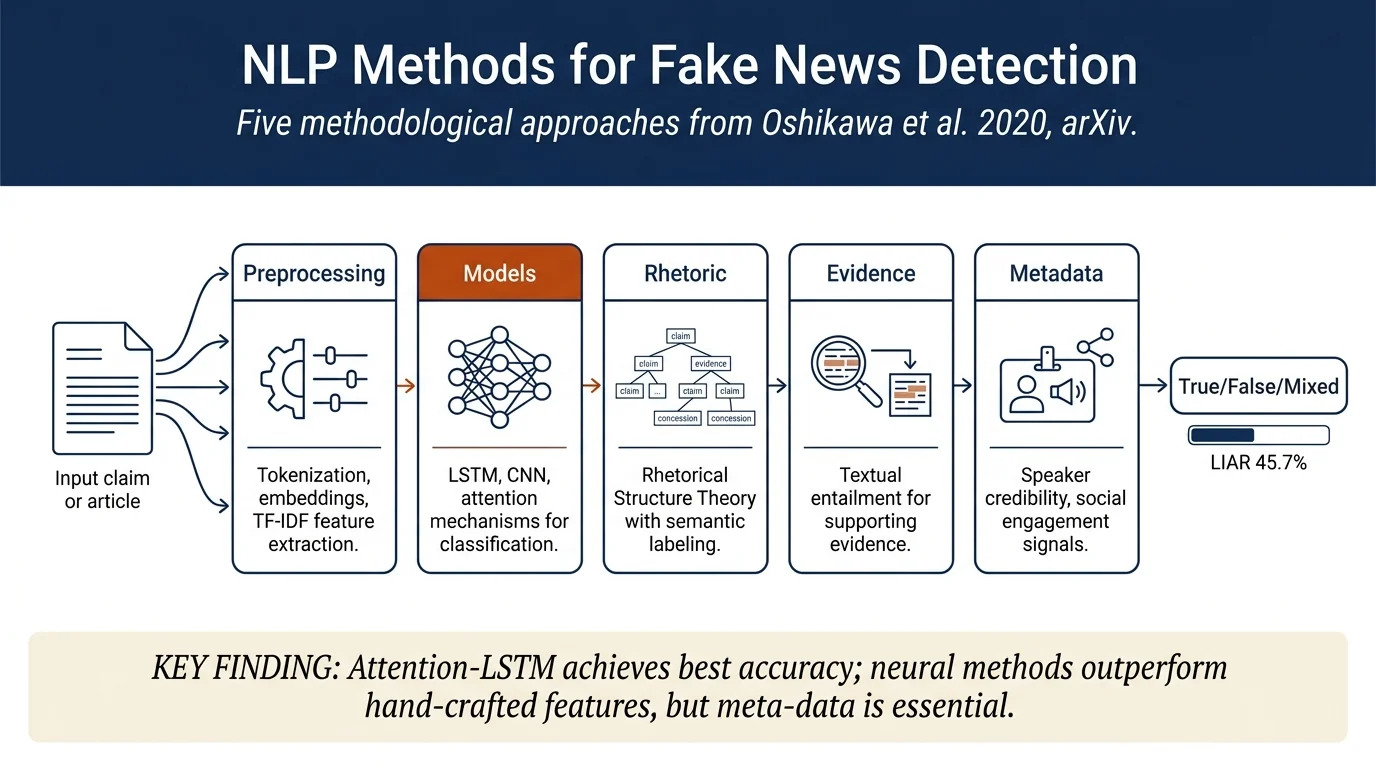
- Five methodological categories: preprocessing (TF-IDF, word embeddings), non-neural classifiers (SVM, NBC, logistic regression), neural networks (LSTM, CNN, attention mechanisms), rhetorical approaches (RST), and evidence collection (RTE-based methods)
- Performance benchmarking showing LSTM+attention achieves 41.5–45.7% on LIAR; attention-LSTM reaches 68–76% on FEVER; social engagement + graph convolutional networks achieve 94.4% on FakeNewsNet
- Critical recommendations for future datasets and detection models: fine-grained truthfulness labels, diverse speaker/publisher sampling, validation of entire articles, and investigation of hand-crafted features with neural networks
Method¶
The survey organizes NLP solutions across five dimensions:
Preprocessing (§5.1) standardizes input texts via tokenization, stemming, and feature conversion using TF-IDF and Linguistic Inquiry and Word Count (LIWC). For word sequences, pre-trained embeddings (word2vec, GloVe) are standard. For entire-article inputs, central claims are identified using TF-IDF ranking and DrQA systems.
Machine learning models (§5.2) include classical approaches and neural networks. Non-neural baselines use Support Vector Machines (SVM), Naive Bayes, Logistic Regression, and Random Forests on hand-crafted features. Neural networks employ Recurrent Neural Networks (especially LSTM) for capturing long-term dependencies; Convolutional Neural Networks (CNN) for local pattern extraction; and Attention mechanisms (e.g., speaker name and topic attention) which consistently improve accuracy by ~3%.
Rhetorical Structure Theory (§5.3) applies RST combined with Vector Space Model to identify discourse coherence patterns. Sentences are semantically labeled (Circumstance, Evidence, Purpose), converting news into high-dimensional RST vectors compared to true/fake centroids.
Evidence collection (§5.4) uses Recognizing Textual Entailment (RTE) to gather supporting or refuting sentences from external sources (Wikipedia in FEVER, general news in EMERGENT). This approach requires evidence-annotated datasets.
Meta-data exploitation integrates speaker credibility, political party affiliation, historical credibility counts (LIAR), and social engagement (retweets, comments, user features) — improvements in models using all meta-data range from +4% (LIAR) to +21% (improvements on speaker credibility sources).
Results¶
LIAR dataset (binary/six-way classification on short claims): - SVM baseline: 25.5%; CNN: 27.0% - LSTM with all meta-data: 39.9%; LSTM+Attention with all meta-data: 41.5% - Best reported (Kirilin & Strube, 2018): 45.7% using speaker credit replacement - Binary (2-class) conversion: CNN deep learning reaches 96.2%
FEVER dataset (claim verification with evidence retrieval): - Decomposable Attention baseline: 31.9%–50.9% (verification + evidence) - TWOWINGOS: 54.3%–76.0% - LSTM (ESIM-Att): 64.7%–68.4% - Best reported: 68.0%–68.4% (verification accuracy using semantic matching or LSTM)
FakeNewsNet dataset (entire-article classification): - RST + LIWC baseline: 57.1%–61.0% - Deep learning (TriFN, HC-CB-3): 85.6%–87.8% - Graph Convolutional Networks (GCN) on publisher-article relationships: 94.4% (BuzzFeed), 93.8% (PolitiFact)
Connections¶
- Related to Fake News Detection on Social Media: A Data Mining Perspective via shared focus on machine learning taxonomies; Shu et al. (2017) covers broader data-mining perspective including propagation and source credibility, while Oshikawa focuses narrowly on NLP text-based methods
- Related to Combating Fake News: A Survey on Identification and Mitigation Techniques via overlapping datasets and methods; Sharma et al. (2018) includes mitigation techniques and feedback-based approaches, whereas Oshikawa emphasizes content-based NLP
- Cited in A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities for dataset summaries and NLP method comparisons within the broader taxonomy of knowledge, style, propagation, and source-based detection
- Complements Truth of Varying Shades: Analyzing Language in Fake News and Political Fact-Checking on linguistic features; Oshikawa systematizes where linguistic approaches fit (content-based, style-based) within the broader NLP ecosystem
- Related to A Stylometric Inquiry into Hyperpartisan and Fake News on stylometric fake news detection; both emphasize limitations of shallow linguistic features vs. neural approaches
Notes¶
Strengths: - Systematic, comprehensive treatment of NLP methods specific to fake news detection—fills a gap between general NLP/ML surveys and fake news domain knowledge - Detailed dataset inventory with sizes, annotations, and characteristics (Table 1); useful reference for practitioners - Clear performance benchmarking across three major datasets (LIAR, FEVER, FakeNewsNet) showing empirical trade-offs - Valuable critique of hand-crafted features (Section 7.2): empirical evidence that LIWC/rhetorical features don't combine well with neural networks despite helping classical ML
Weaknesses: - Focus on English-language datasets and English text; generalizability to other languages unclear - Limited discussion of cross-domain performance; all results are within-dataset evaluation - Attention-mechanism improvements are modest (~3%) on LIAR; unclear if statistical significance testing was done - FEVER results are for 2-stage task (claim + evidence); end-to-end (claim-only) results would be more comparable to LIAR - Limited treatment of dataset biases (e.g., publisher-level labeling in Some-Like-It-Hoax confounds content with source credibility)
Future directions: Authors recommend (§7.1–7.2) moving beyond binary true/false classification toward ordinal truthfulness scales; sampling quotes/articles from diverse speakers/publishers to avoid spurious website-level correlations; manually validating entire articles (most datasets label claims, not full articles); and investigating whether hand-crafted features can be integrated with neural networks without diminishing returns.