EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection¶
Authors: Yaqing Wang, Fenglong Ma, Zhiwei Jin, Ye Yuan, Guangxu Xun, Kishlay Jha, Lu Su, Jing Gao
Venue: KDD '18, August 19–23, 2018, London — DOI
TL;DR¶
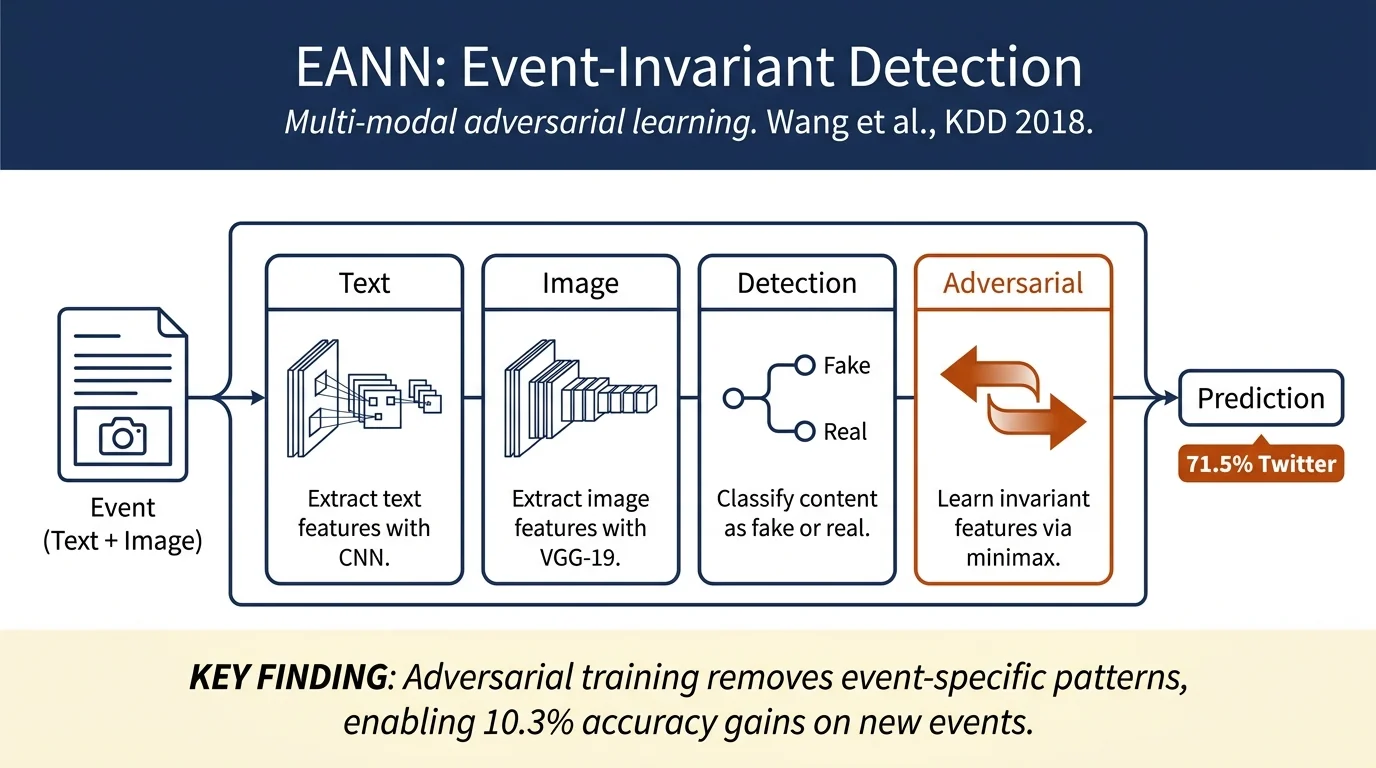
The paper proposes EANN, an adversarial neural network that detects fake news on newly emerged events by learning event-invariant features. An event discriminator forces the multi-modal feature extractor to remove event-specific features while preserving shared patterns across events. On Twitter and Weibo datasets, EANN achieves 71.5% accuracy (10.3% improvement over prior art) and demonstrates strong transfer to unseen events.
Contributions¶
- First to formulate fake news detection on newly emerged, time-critical events as a transfer learning problem, addressing the limitation that event-specific features learned on known events don't generalize.
- Novel EANN framework with three components: multi-modal feature extractor (text + image), fake news detector, and event discriminator to measure and remove event-specific information.
- Use of adversarial learning (minimax game) to learn event-invariant representations: the feature extractor tries to fool the discriminator into recognizing no event, while the discriminator tries to classify the event.
- Empirical validation on two large real-world datasets (Twitter MediaEval, Weibo) with multimodal content, showing substantial improvements in accuracy, precision, and F1 score.
Method¶
Multi-modal Feature Extractor: - Text: Text-CNN with multiple filter widths (1–4) on pre-trained word embeddings, followed by max-pooling and fully connected layer to produce text features R_T. - Image: Pre-trained VGG-19 (frozen weights) followed by fully connected layer to match text feature dimension p, producing visual features R_V. - Features concatenated: R_F = R_T ⊕ R_V ∈ ℝ^(2p).
Fake News Detector: Fully connected layer with softmax on top of R_F, minimizes cross-entropy loss L_d for binary classification (fake/real).
Event Discriminator: Two fully connected layers that classify the event label (K possible events), minimizing cross-entropy loss L_e. During training, the feature extractor tries to maximize L_e (fool the discriminator by removing event-specific information), while the discriminator minimizes it.
Minimax Game: - Final loss: L_final = L_d - λ L_e (λ = 1) - Feature extractor updated via gradient reversal layer (GRL): θ_f ← θ_f − η(∂L_d/∂θ_f − λ ∂L_e/∂θ_f) - Learning rate decayed during training to stabilize convergence.
Results¶
Twitter (MediaEval): - EANN: 71.5% accuracy, 0.822 precision, 0.638 recall, 0.719 F1 - Best baseline (att-RNN): 66.4% accuracy, 0.749 precision, 0.615 recall, 0.676 F1 - Improvement: +5.1% accuracy, +6.5% F1
Weibo: - EANN: 82.7% accuracy, 0.847 precision, 0.812 recall, 0.829 F1 - Best baseline (att-RNN): 77.9% accuracy, 0.778 precision, 0.799 recall, 0.789 F1 - Improvement: +4.8% accuracy, +4.0% F1
Ablation (EANN−, without event discriminator): 64.8% accuracy (Twitter), 79.5% (Weibo)—shows event discriminator is essential.
Qualitative: t-SNE visualization shows EANN learns more separated fake/real clusters than EANN−, especially across event boundaries.
Connections¶
- Related to MVAE via shared use of multi-modal feature fusion (text + image); EANN adds adversarial event-invariance, MVAE uses VAE reconstruction.
- Extends Adversarial learning for fake news detection ideas (gradient reversal layer from Ganin & Lempitsky) to the detection domain.
- Contrasts with SAFE and network-based detection by focusing on content-based multi-modal features rather than similarity or propagation.
- Foundational for later transfer-based detection methods on new events.
Notes¶
Strengths: - Well-motivated problem: existing models fail on new events because they learn event-specific features. The adversarial framing is elegant and technically sound. - Clear experimental design: separate training/test sets with no event overlap; shows true generalization to unseen events. - Strong empirical results on two real-world datasets with substantial improvements. - Comprehensive ablations: comparison w/ and w/o event discriminator, analysis of single vs. multi-modal baselines. - Case studies (Figures 5–6) effectively illustrate why multi-modal features matter beyond single modality.
Limitations: - Event discriminator assumes K event labels are available during training; unclear how to handle truly novel events at test time without retraining. - Frozen VGG-19 weights—joint fine-tuning might improve visual feature quality. - λ = 1 (trade-off parameter) not tuned; sensitivity to this hyperparameter not explored. - Text and visual features simply concatenated; no learned interaction between modalities (unlike attention-based fusion in att-RNN). - Evaluation limited to microblogs (Twitter, Weibo); generalization to longer-form news or other platforms unknown.
Follow-ups: - Extend to truly zero-shot settings where new events are not seen during training. - Explore learned fusion mechanisms (e.g., attention or gating) between text and image features. - Apply to other detection tasks (rumor detection, disinformation) or platforms. - Investigate why visual features transfer better than text (as observed on Twitter).