FakeNewsNet: A Data Repository with News Content, Social Context and Spatiotemporal Information for Studying Fake News on Social Media¶
Authors: Kai Shu, Deepak Mahudeswaran, Suhang Wang, Dongwon Lee, Huan Liu Venue: arXiv:1809.01286 [cs.CY], September 2018
TL;DR¶
FakeNewsNet is a multi-dimensional repository for fake news research on social media, integrating news content (linguistic and visual features), social context (user engagement, network structure, response patterns), and spatiotemporal information (location, timestamps). The dataset contains both fake and real news from PolitiFact and GossipCop, enabling comprehensive studies of fake news detection, evolution, and mitigation that leverage characteristics beyond textual content alone.
Contributions¶
- Constructs and publicizes a comprehensive multi-dimensional data repository containing news content, social context, and spatiotemporal features — the first publicly available dataset combining all three dimensions at scale.
- Provides extensive dataset comparison against existing fake news detection datasets (BuzzFeedNews, LIAR, BS Detector, CREDBANK, BuzzFace, FacebookHoax), demonstrating FakeNewsNet's breadth and completeness.
- Performs exploratory data analysis across multiple perspectives, characterizing differences between fake and real news in sentiment distribution, user engagement patterns, network structures, and temporal dynamics.
- Demonstrates potential downstream applications: fake news detection, fake news evolution modeling, fake news mitigation, and malicious account detection.
Dataset Overview¶
FakeNewsNet integrates data from two fact-checking sources:
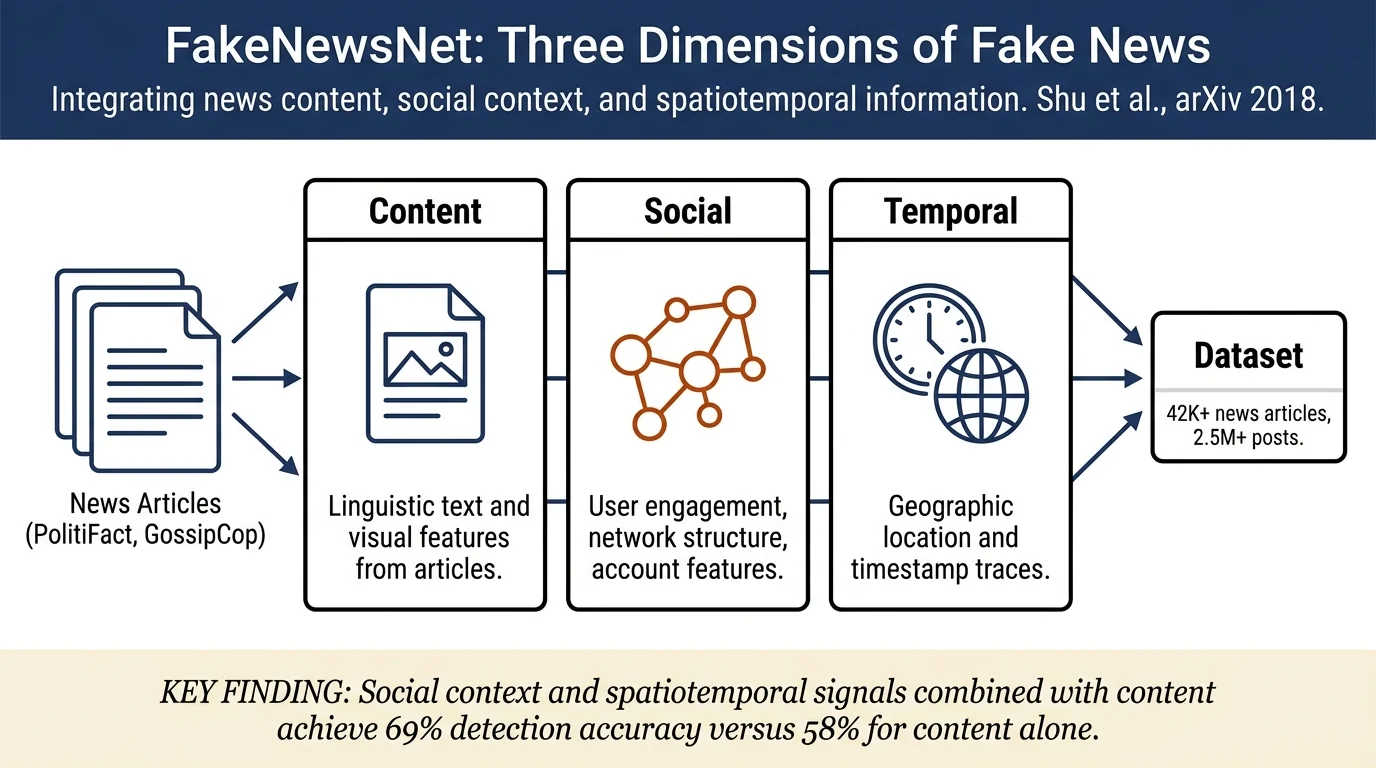
PolitiFact: Political news fact-checked by PolitiFact journalists. Contains 12,911 news articles (4,115 fake, 8,796 real), 3,323 associated fake news pieces from GossipCop dataset, 430 news articles with images, and 163,227 relevant tweets with 905,509 total user engagements.
GossipCop: Entertainment news collected from GossipCop. Contains 5,323 fake and 16,817 real news pieces, 4,947 news articles with images, and 2,265,153 associated social media posts.
Data Dimensions¶
News Content: Linguistic (text body, headlines, quoted strings) and visual features (images from news articles). Extracted from trusted fact-checking websites (PolitiFact, GossipCop) and entertainment sources (E! Online).
Social Context: Includes five aspects: - User engagements: posts, replies, retweets, likes - User profiles: creation date, follower/following counts, verified status, profile metadata - Network structure: follower counts, following counts, average followers, social network topology - Post and response features: timestamps, engagement metrics - User behavior: bot/human classification via Botometer
Spatiotemporal Information: Location data from user profiles (city and country levels) and timestamps for all tweets, enabling tracking of how fake news pieces propagate geographically and temporally.
Key Findings¶
Sentiment and Engagement: Fake news articles show more negative sentiment in user replies, while real news exhibits more neutral sentiment. On PolitiFact, fake news pieces have fewer replies but more retweets than real news. The distribution of likes, retweets, and replies differs significantly between fake and real news.
User Characteristics: Approximately 22% of users involved in fake news are bots (versus ~9% for real news). Users who post fake news tend to have older account registration times, fewer followers, and post less frequently than real-news sharers.
Temporal Dynamics: Fake news pieces exhibit different temporal engagement patterns — sudden spikes followed by decline, versus steady increase for real news. User profile creation time distributions differ between fake-news and real-news posters.
Network Structure: Fake news diffusion tends to form echo chambers with distinct network patterns compared to real news propagation. Follower/following distributions follow power-law patterns but with different slopes.
Spatial Distribution: Explicit location data from user profiles reveals geographic concentration differences between users sharing fake versus real news.
Classification Performance¶
Social Article Fusion (SAF) models combining news content with social context outperform content-only baselines:
| Model | PolitiFact Accuracy | GossipCop Accuracy |
|---|---|---|
| SVM (news content only) | 0.580 | 0.397 |
| Logistic regression | 0.642 | 0.648 |
| CNN | 0.629 | 0.723 |
| Social Article Fusion /S | 0.667 | 0.635 |
| Social Article Fusion /A | 0.654 | 0.689 |
| Social Article Fusion (combined) | 0.691 | 0.689 |
Data Structure and Accessibility¶
The repository is organized hierarchically with JSON metadata files:
- news_content.json: News article metadata (text, images, publish date, source URL)
- tweets folder: Tweet objects with full metadata from Twitter API
- retweets folder: Retweet information and cascades
- user_profiles folder: User metadata from Twitter API
- user_timeline_tweets folder: Historical tweets from each user
An API interface provides flexible data access with options to download linguistic features, visual content, tweets, user engagement data, network information, and temporal engagements by custom filters.
Connections¶
- Foundational dataset paper enabling Shu et al. (2019) on user profiles for fake news detection, which systematically analyzes FakeNewsNet's user data.
- Extended by Zhou et al. (2020) — SAFE, which applies multimodal learning to FakeNewsNet.
- Related to propagation-based detection approaches that leverage the spatiotemporal and network dimensions.
- Connects to social context for detection, which uses user engagement and network features from this dataset.
- Cited in surveys like Sharma et al. (2018) as a key benchmark for fake news research.
Notes¶
FakeNewsNet represents a significant methodological advance by integrating three complementary feature families (content, social, spatiotemporal) in a single public resource. The dataset's comprehensiveness enables exploration of the hypothesis that social signals and propagation patterns carry stronger discriminative power than textual features alone — a finding validated in downstream work.
The data collection methodology (leveraging fact-checking websites as ground truth, Twitter API crawling) is sound, but the dataset reflects platform-specific dynamics of Twitter and may not generalize to other social platforms with different network structures, engagement mechanisms, or user demographics.
The dataset creation time (2018–2019 collection window) predates recent shifts in bot sophistication, misinformation tactics, and platform moderation policies. Temporal relevance for reproducing real-world deployment performance warrants consideration for contemporary applications.
The paper's exploratory analysis is extensive but lacks formal statistical hypothesis testing on several key observations (e.g., network topology, sentiment distribution differences). Some findings appear dataset-artifact dependent (e.g., political bias correlations) and may not transfer to international contexts or non-political domains.