MVAE: Multimodal Variational Autoencoder for Fake News Detection¶
Authors: Dhruv Khattar, Jaipal Singh Goud, Manish Gupta, Vasudeva Varma
Venue: World Wide Web Conference (WWW), May 2019, San Francisco — DOI
TL;DR¶
The paper proposes MVAE, a variational autoencoder that learns shared representations of text and images in social media posts to detect fake news. The model jointly trains an encoder-decoder (to discover correlations across modalities) with a binary classifier. On Twitter and Weibo datasets, MVAE outperforms prior multimodal detection methods by ~6% accuracy and ~5% F1 score.
Contributions¶
- A novel multimodal variational autoencoder (MVAE) that learns joint text-image representations for fake news detection.
- Joint training of the VAE (encoder-decoder) with a fake news classifier, enabling the model to discover correlations across modalities while performing detection.
- Extensive evaluation on two real-world social media datasets (Twitter, Weibo) with multimodal content, showing substantial improvements over state-of-the-art baselines.
Method¶
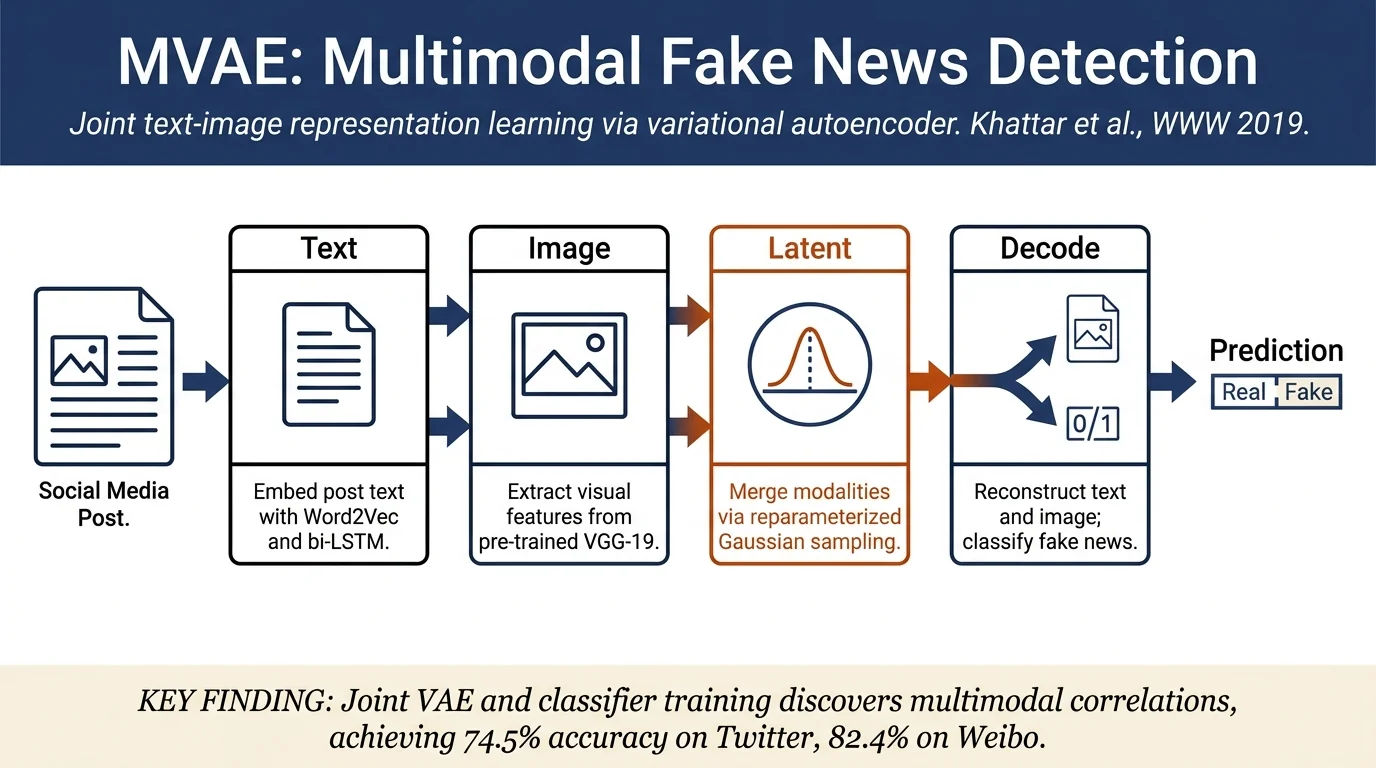
Encoder: Encodes text and image into a shared latent representation: - Textual encoder: Stacked bi-directional LSTMs with pre-trained Word2Vec embeddings, followed by a fully connected layer. - Visual encoder: Pre-trained VGG-19 (frozen weights) followed by fully connected layers, producing feature representations of same dimensionality as text. - Both modalities are concatenated, passed through a fully connected layer, and reparameterized using Gaussian sampling to produce the latent vector.
Decoder: Reconstructs both text and image from the latent vector: - Textual decoder: Bi-directional LSTMs with softmax outputs to reconstruct word probabilities. - Visual decoder: Fully connected layers to reconstruct VGG-19 features.
Fake news detector: Binary classifier with fully connected layers that operates on the learned latent representation.
Joint loss: Final training objective combines VAE reconstruction loss (cross-entropy for text, MSE for image features), KL divergence loss, and binary classification loss.
Results¶
On Twitter (MediaEval dataset): MVAE achieves 74.5% accuracy and 0.73 F1, compared to 66.4% and 0.66 for the best prior method (att-RNN).
On Weibo (from [8]): MVAE achieves 82.4% accuracy and 0.82 F1, compared to 78.2% and 0.80 for the best baseline (EANN).
The improvement reflects the model's ability to discover correlations across modalities, something prior attention-based and event-discriminator approaches did not explicitly optimize for.
Connections¶
- Related to SAFE via joint treatment of text and image for fake news detection, though SAFE uses similarity-aware fusion rather than VAE-based reconstruction.
- Extends multimodal fusion methods to the detection domain, building on VAE foundations from generative modeling.
- Differs from network-based detection by focusing on post content rather than propagation structure.
Notes¶
Strengths: - Clear motivation: using shared representation learning (VAE) rather than just fusion or attention to exploit multimodal correlations. - Well-executed experiments with appropriate baselines (unimodal, multimodal prior art). - Substantial empirical gains on two datasets, suggesting the approach generalizes.
Limitations: - Evaluation limited to microblogs (Twitter, Weibo); generalization to news articles or other platforms unclear. - No ablation isolating the contribution of VAE reconstruction loss vs. classification loss; unclear if reconstruction is essential or just regularization. - Frozen VGG-19 weights—joint fine-tuning might improve performance but was avoided for "parameter explosion." - No analysis of failure modes or learned latent representations (e.g., interpretability of what correlations are discovered).
Follow-ups: - Explore whether reconstruction loss is necessary or if a simpler joint embedding would suffice. - Extend to more modalities (e.g., user metadata, temporal context, multi-image posts). - Analyze the latent space to understand what multimodal correlations the VAE learns.