How Do Large Language Models Capture the Ever-changing World Knowledge? A Review of Recent Advances¶
Authors: Zihan Zhang, Meng Fang, Ling Chen, Mohammad-Reza Namazi-Rad, Jun Wang
Venue: arXiv, 2023 — arXiv:2310.07343
TL;DR¶
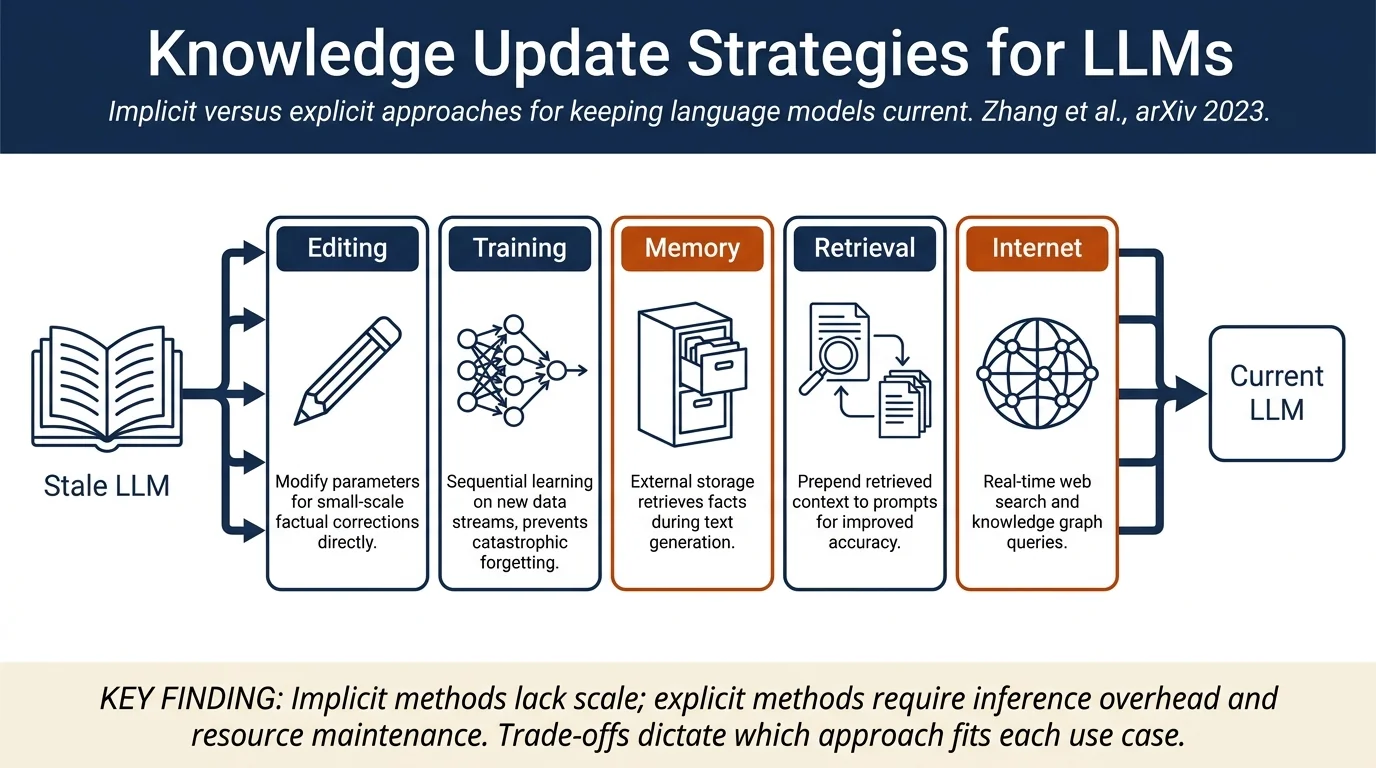
This survey reviews methods for aligning large language models with ever-changing world knowledge without retraining from scratch. The authors systematically categorize approaches as either implicit (modifying LLM parameters directly via knowledge editing or continual learning) or explicit (augmenting LLMs with external resources via memory, retrieval, or internet access), compare their scalability and efficiency trade-offs, and identify open challenges in robust knowledge updates and comprehensive evaluation benchmarks.
Contributions¶
- Systematic taxonomy of recent advances in keeping LLMs up-to-date, covering cutting-edge literature from 2022–2023
- Categorization of approaches into two main strategies: implicit methods (knowledge editing, continual learning) and explicit methods (memory-augmented, retrieval-augmented, internet-enhanced)
- Detailed comparison of representative methods across dimensions of scalability, parameter modification, training requirements, and architectural constraints (Table 1)
- Analysis of key challenges: robust/efficient knowledge editing, knowledge conflicts, and lack of unified evaluation frameworks
- Identification of future research directions for the field
Method¶
Implicit Methods: Direct Knowledge Modification¶
Knowledge Editing (KE) modifies LLM parameters to correct specific factual errors without full retraining. Approaches include: - Meta-learning methods (Sinitsin et al., 2020) that train neural networks to output weight updates - Hypernetwork editors that learn extrinsic editing functions mapping fact pairs to parameter shifts - Locate-and-edit methods identifying specific neurons (e.g., knowledge neurons) and modifying their activations - Multi-layer approaches like MEND and Meng et al. (2023) that decompose edits into low-rank updates on feed-forward network weights
KE provides fine-grained control but scales poorly—editing hundreds of facts requires thousands of updates (Meng et al., 2023b).
Continual Learning (CL) trains an already-deployed LLM on new data streams to acquire knowledge while mitigating catastrophic forgetting. Methods include: - Regularization-based approaches (Chen et al., 2020; Ke et al., 2023) that penalize changes to previously learned knowledge - Replay methods (He et al., 2021) mixing old and new data during sequential training - Architectural methods (Wang et al., 2021; DEMix-DAPT) that dedicate separate parameters or layers to new domains while freezing others
CL enables larger-scale knowledge acquisition but remains computationally expensive compared to inference-only methods.
Explicit Methods: External Knowledge Resources¶
Memory-Enhanced Methods pair LLMs with external memory systems storing new information. The retriever fetches relevant context during generation: - \(k\)NN-LM (Khandelwal et al., 2020) stores key-value pairs from a corpus in memory and retrieves nearest neighbors during token generation - MEmPrompt (Madaan et al., 2022) and SERAC (Mitchell et al., 2022) use auxiliary models to retrieve feedback for fact correction - Internet-enhanced methods (Lazaridou et al., 2022; Liu et al., 2023a) dynamically query the web during generation for real-time knowledge
Retrieval-Augmented Methods augment LLM prompts with retrieved documents: - Single-stage retrieval (Ram et al., 2023; Si et al., 2023) prepends retrieved documents directly to inputs for zero-shot/few-shot learning - Multi-stage retrieval (Trivedi et al., 2022; Press et al., 2023) iteratively retrieves and refines context across multiple reasoning steps - Retrieval can reduce inference cost and mitigate hallucinations (Li et al., 2023a) but introduces retrieval latency and potential noise
Internet-Enhanced Methods connect LLMs to real-time information via search engines and knowledge graphs: - Tools like LangChain (Chase, 2022) and ChatGPT Plugins enable LLM-driven web search - Methods treat LLMs as central planners composing multi-step web queries (Yao et al., 2023a; Yang et al., 2023) - Enable real-time knowledge but suffer from noisy retrieval and high inference overhead
Results and Comparison¶
Table 1 compares implicit and explicit methods across key dimensions:
| Category | Scale | Requires Training | Architectural Constraints | Inference Cost |
|---|---|---|---|---|
| Knowledge Editing | Small (fact pairs) | No | None | None |
| Continual Learning | Medium (data streams) | Yes | Potentially large | None |
| Memory-Enhanced | Large | No | Auxiliary memory/retriever | Moderate (retrieval + generation) |
| Retrieval-Augmented | Large | No | External retriever | High (retrieval) |
| Internet-Enhanced | Unlimited | No | External tools | Very High (web access) |
Key Trade-offs:
-
Implicit vs. Explicit: Implicit methods offer fine-grained control and no inference overhead but struggle to scale beyond 100s of facts. Explicit methods scale but require periodic maintenance of external resources and add inference cost.
-
Updating Implicitly vs. Explicitly: Compared to naive retraining or fine-tuning, implicit methods like KE are orders of magnitude more efficient for small updates. Continual learning scales better than KE but remains computationally expensive (Hartvig sen et al., 2023). Explicit methods leverage fixed LLMs and avoid the need for training.
-
Generalization: Knowledge edits may fail to generalize (Zheng et al., 2023); continual learning suffers from catastrophic forgetting on older knowledge (Jang et al., 2022b); retrieval quality depends on the external resource quality.
Challenges and Future Directions¶
Robust and Efficient Knowledge Editing: Existing KE methods focus on updating small-scale, localized knowledge (e.g., single fact pairs on synthetic datasets). Open questions: Does edited knowledge propagate to related facts? How do KE methods perform on realistic, multi-fact updates? Do edits transfer across model architectures?
Catastrophic Forgetting in Continual Learning: CL methods remain vulnerable to forgetting previously acquired knowledge. More principled approaches to balancing old and new knowledge (beyond regularization and replay) are needed. Meta-continual-learning (Jang et al., 2022a) and parameter isolation strategies show promise but lack large-scale evaluation.
Knowledge Conflict: Updating old knowledge with new information can introduce conflicts in the model's behavior. Huang et al. (2023) and Hartvig sen et al. (2023) argue that naive KE and CL may propagate edits inconsistently across model outputs, requiring more explicit conflict resolution mechanisms.
Comprehensive Evaluation and Benchmarks: Existing work evaluates KE and CL methods on synthetic or narrow datasets in isolation. A unified benchmark comparing implicit and explicit approaches across consistent metrics and diverse knowledge types (textual, temporal, numerical) is needed.
Connections¶
- Chang et al. (2023) — comprehensive survey on LLM evaluation methodologies; provides context for assessing knowledge update effectiveness
- Ji et al. (2022) — survey on hallucination in language generation; motivates the need for knowledge updates to reduce outdated/false generations
- Asai et al. (2023) — self-retrieval-augmented generation demonstrates adaptive retrieval for mitigating hallucinations
- Zhao et al. (2023) — complementary survey on LLM advances covering broader capabilities beyond knowledge updates
- Wang et al. (2023) — survey on factuality challenges in LLMs; relevant to understanding why knowledge updates are necessary
Notes¶
Scope and Limitations: The survey focuses on already-deployed models and methods that do not require full retraining. It does not cover knowledge-enhanced LM training (where knowledge is injected during pretraining) or structural knowledge bases (KGs, databases), deferring to prior surveys by Zhu et al. (2021) and others. Evaluation is primarily on synthetic or domain-specific datasets; real-world effectiveness remains understudied.
Relevance to Misinformation/Fact-Checking: LLMs' tendency to become outdated is a critical failure mode in fact-checking and misinformation detection systems. When deployed systems rely on frozen knowledge, they fail on emerging claims, recent events, and evolving falsehoods. This survey catalogs solutions for keeping detection systems up-to-date—essential for practitioners building real-world systems.
Strength: Comprehensive, well-organized taxonomy with clear visual explanations (Figures 2–3) and detailed comparison tables. Covers cutting-edge work (mostly 2022–2023) with careful distinction between implicit and explicit trade-offs.
Weakness: Limited discussion of hybrid approaches or real-world deployment challenges (e.g., computational overhead in production, integration with existing systems). Evaluation is primarily on synthetic/narrow datasets; larger-scale empirical comparisons across categories would strengthen conclusions.