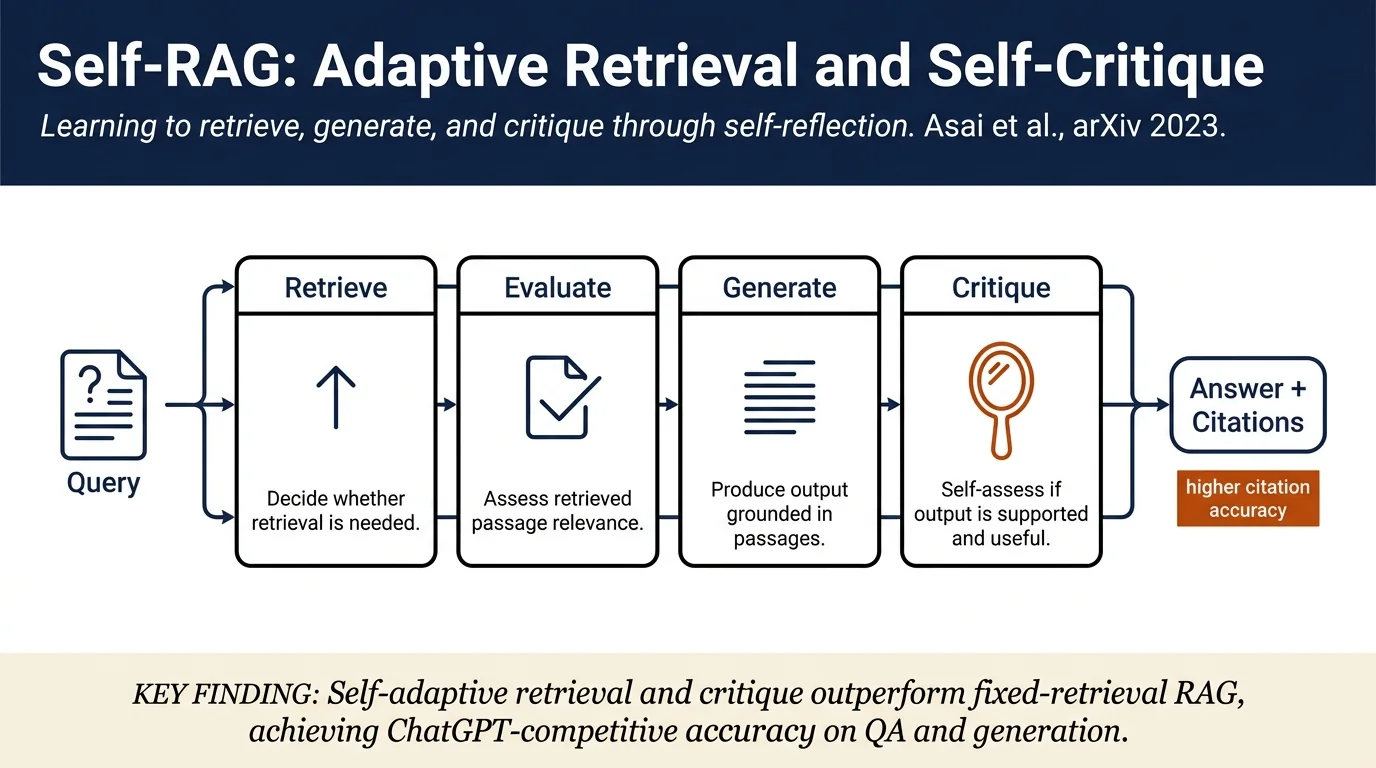
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection¶
Authors: Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi
Affiliation: University of Washington, Allen Institute for AI, IBM Research AI
Venue: arXiv preprint, October 2023 — arXiv:2310.11511
TL;DR¶
This paper introduces SELF-RAG (Self-Reflective Retrieval-Augmented Generation), a framework that teaches language models to adaptively decide when to retrieve external passages, generate factually grounded responses, and critique their own outputs. Using special "reflection tokens," the model learns to self-evaluate at inference time without sacrificing versatility or creativity, significantly outperforming prior retrieval-augmented and instruction-tuned models on diverse knowledge-intensive and reasoning tasks.
Contributions¶
-
SELF-RAG framework: A unified approach enabling LLMs to retrieve on-demand, generate conditioned on passages, and reflect on output quality through special reflection tokens.
-
Reflection tokens: Four token types (retrieval, relevant, supported, useful) that allow models to self-assess whether retrieval is needed, whether retrieved passages are relevant, whether outputs are factually supported, and whether outputs are useful/informative.
-
Training methodology: Joint training of a critic model (C) that predicts reflection tokens and a generator model (M) that produces outputs interleaved with reflection tokens, enabling diverse instruction-following tasks without sacrificing model versatility.
-
Inference-time customization: Reflection token probabilities can be adjusted at test time to control model behavior—prioritizing citation accuracy, retrieval frequency, or overall utility without retraining.
-
Empirical validation: SELF-RAG-7B and SELF-RAG-13B substantially outperform ChatGPT and retrieval-augmented Llama2-chat on PubHealth, PopQA, ASQA (reasoning), and fact verification tasks, while achieving superior citation accuracy.
Method¶
Problem formulation and motivation¶
Traditional retrieval-augmented generation (RAG) systems either indiscriminately retrieve a fixed number of documents for every query regardless of necessity, or never revisit retrieval quality. Both approaches hurt generation quality and create unnecessary computational overhead. SELF-RAG addresses this by training models to decide when retrieval helps and whether their outputs are grounded.
Reflection tokens and inference algorithm¶
The model generates reflection tokens alongside content:
- Retrieval token ([Retrieve]): answers "is factual grounding needed?" (Yes/No/Continue)
- Relevant token ([IsRelevant]): evaluates whether a retrieved passage is relevant for the task
- Support token ([IsSupport]): determines if retrieved passages fully support, partially support, or contradict the model output
- Utility token ([IsUtil]): judges whether the output is genuinely helpful and informative
At inference time, the model uses a retriever (R) to fetch top-k passages when [Retrieve]=Yes is predicted, then scores candidate outputs using a weighted sum of reflection token probabilities. A segment-level beam search selects outputs with the highest combined score.
Training approach¶
Critic model (C): Trained on ~145K curated instances from diverse instruction-following datasets (Open-Instruct, KILT, OpenAssistant, FLAN) with reflection token annotations. Labels are collected by prompting GPT-4 and validated via manual assessment. C learns to predict the four reflection token types as a sequence-to-sequence task.
Generator model (M): Trained on the same curated data augmented with retrieved passages. For each input-output pair, C predicts whether retrieval is beneficial and, if so, retrieves top passages. The generator then learns to output text interleaved with reflection tokens using standard next-token prediction. This allows flexible instruction-following—the model can condition on retrieval when available without requiring it for every task.
Inference and customization¶
The framework allows practitioners to adjust reflection token weights at test time (e.g., prioritize [IsSupport] tokens for high citation accuracy, or [IsRelevant] tokens for frequent retrieval), enabling task-specific behavior tuning without retraining.
Results¶
Main findings¶
On six diverse downstream tasks, SELF-RAG significantly outperforms strong baselines:
-
PopQA, PubHealth, ASQA (short-form, closed-set, and long-form QA): SELF-RAG-7B and -13B outperform ChatGPT (PubHealth: 73.5 vs. 65.7 accuracy), retrieval-augmented Llama2-chat, and instruction-tuned Alpaca on all metrics. SELF-RAG achieves superior citation precision and recall.
-
BiographyGen (long-form generation): SELF-RAG-13B achieves 80.2 F1 vs. ChatGPT's 71.2 on biography generation with superior factuality.
-
Reasoning and fact-checking: On ASQA, SELF-RAG outperforms ChatGPT with citations (67.3 F1 vs. 57.3), demonstrating better ability to cite supporting evidence.
Ablation studies¶
- Necessity of all components: Removing retrieval, critic training, or reflection tokens reduces performance. Using the top retrieved document without reflection loses substantial gains.
- Adaptive retrieval: SELF-RAG retrieves less frequently on tasks where retrieval is unnecessary (e.g., PopQA: ~56% of examples) yet maintains high accuracy, unlike fixed-retrieval RAG baselines.
- Customization effectiveness: Adjusting reflection token weights at inference time successfully modulates accuracy-citation tradeoffs without retraining.
Human evaluation¶
Manual assessment of 50 samples from PopQA and BiographyGen shows that SELF-RAG outputs are often plausible and supported by retrieved passages, with high inter-annotator agreement on reflection token predictions.
Connections¶
- Retrieval-Augmented Generation — SELF-RAG extends RAG with adaptive retrieval and self-reflection rather than static retrieval.
- Factuality in large language models — addresses factuality through grounding in retrieved passages and explicit support prediction.
- Hallucination in language models — reduces hallucinations by teaching models when and how to retrieve grounding.
- Fact-checking and corrections — integrates fact-checking mechanisms via support tokens.
- Wang et al. 2023 — surveys factuality in LLMs; SELF-RAG is a practical approach to the enhanced factuality problem.
- Lewis et al. 2020 — foundational RAG work; SELF-RAG improves on it by making retrieval adaptive and adding critique.
- Izacard et al. 2022 — joint training of retriever and generator; SELF-RAG uses similar principles with added reflection.
Notes¶
Strengths:
- Novel and well-motivated framework: reflection tokens are an elegant way to teach self-evaluation without requiring external fact-checking systems.
- Comprehensive evaluation across six diverse tasks, including long-form generation and reasoning, shows broad applicability.
- Empirical results are strong—SELF-RAG-7B compares favorably to ChatGPT and larger models despite being 7-13B parameters.
- Inference-time customization is practical and avoids retraining for different task requirements.
- Transparent methodology: training data and detailed ablations strengthen reproducibility.
Weaknesses:
- Critic model training depends on GPT-4 annotations, which may introduce biases or limit diversity in reflection token definitions.
- Computational cost of inference is higher than base models due to retrieval and beam search, though still tractable.
- Evaluation relies partly on automatic metrics (e.g., accuracy, citation metrics) that may not fully capture nuanced factuality or citation quality; human evaluation is limited to 50 samples.
- The framework assumes access to a reliable retriever and corpus; performance is sensitive to retrieval quality, which is acknowledged but not deeply explored.
Significance:
SELF-RAG offers a principled way to enhance LLM factuality and trustworthiness in knowledge-intensive tasks. The introduction of reflection tokens as trainable self-evaluation mechanisms is a valuable contribution with potential applications beyond QA and generation tasks. For misinformation detection and fact-checking systems, this work is relevant as it demonstrates how LLMs can be trained to justify and critique their own outputs—a key requirement for trustworthy AI in sensitive domains.