Survey of Hallucination in Natural Language Generation¶
Authors: Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Delong Chen, Wenliang Dai, Ho Shu Chan, Andrea Madotto, Pascale Fung
Venue: ACM Computing Surveys, 2022
TL;DR¶
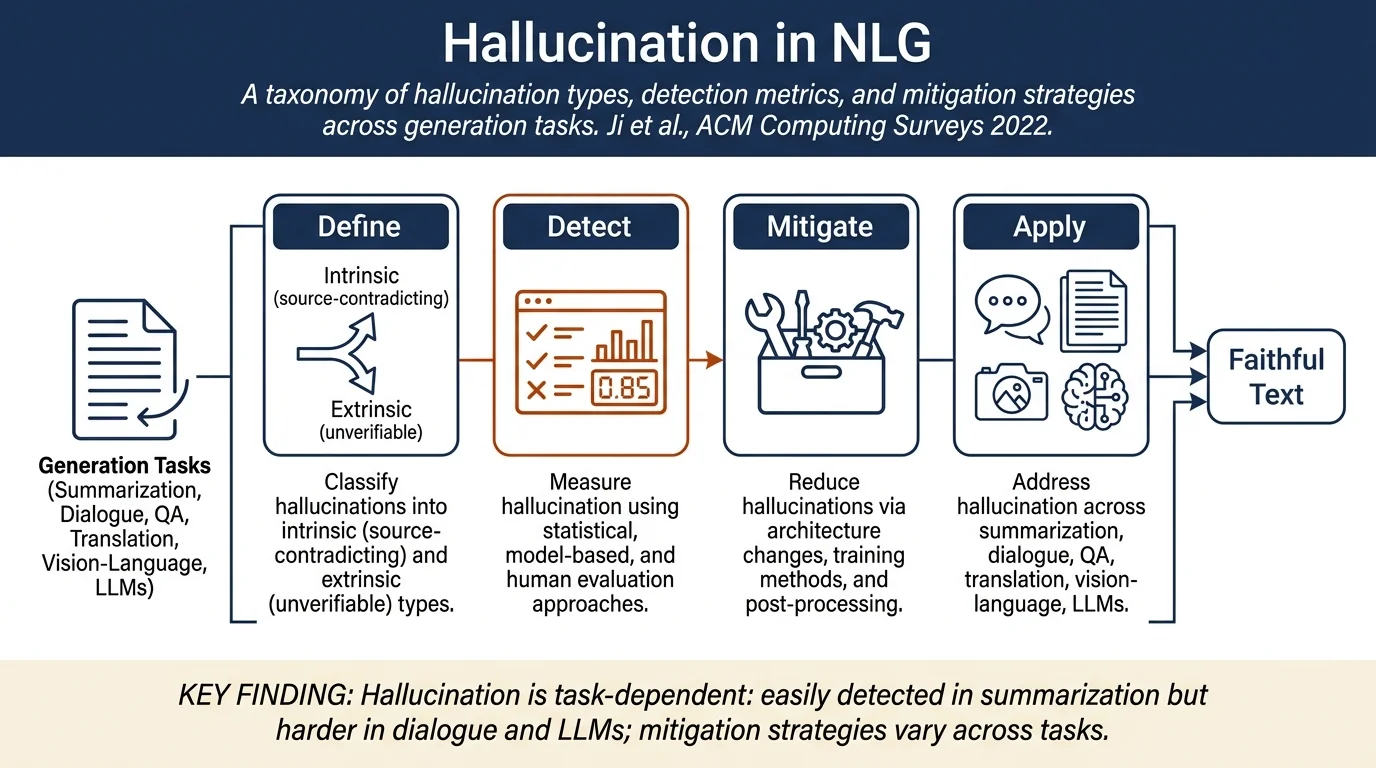
This comprehensive survey examines hallucination in natural language generation—when NLG models generate text that is nonsensical, contradicts source material, or cannot be verified. The authors define two categories of hallucination (intrinsic vs. extrinsic), review metrics and mitigation methods across multiple tasks (summarization, dialogue, QA, machine translation, vision-language generation, LLMs), and identify open challenges in detection and prevention.
Contributions¶
- Comprehensive taxonomy of hallucination across multiple NLG tasks and domains
- Classification of hallucinations into intrinsic (contradicting source) and extrinsic (unverifiable) types
- Overview of evaluation metrics: statistical, model-based, and human evaluation approaches
- Systematic review of mitigation strategies: architecture modifications, training methods, post-processing, and controllable generation
- Task-specific analysis of hallucination in abstractive summarization, dialogue generation, QA, data-to-text generation, machine translation, and multimodal generation
- Discussion of unique challenges in large language models (LLMs)
Method¶
The survey is organized across two dimensions:
General framework (Sections 2–6): The authors provide definitions distinguishing hallucination from related concepts (faithfulness, factuality), categorize hallucinations into intrinsic vs. extrinsic types, and discuss contributors to hallucination (data quality, training methods, inference procedures). They review metrics for measuring hallucination (statistical metrics, model-based metrics leveraging information extraction or NLI models, human evaluation) and mitigation methods (reinforcement learning, multi-task learning, controllable generation, post-processing).
Task-specific analysis (Sections 7–13): Deep dives into hallucination phenomena and solutions across six major NLG tasks:
-
Abstractive Summarization (Section 7): Covers hallucination definitions in abstractive settings, both supervised (IE, NLI-based) and semi-supervised metrics, and mitigation via architecture modifications (graph neural networks, attention mechanisms), training methods (contrastive learning), and post-processing (factual error correction).
-
Dialogue Generation (Section 8): Addresses both task-oriented dialogue (focused on task success) and open-domain dialogue (requiring both informativeness and consistency). Notes that dialogue systems tolerate hallucination differently than summarization.
-
Generative QA (Section 9): Discusses hallucination detection via QA models, showing that hallucinations appear in both factually correct and incorrect generations.
-
Data-to-Text Generation (Section 10): Covers numeric hallucinations and factual consistency when generating text from structured data.
-
Neural Machine Translation (Section 11): Reviews hallucinations in translation and alignment failures.
-
Vision-Language Generation (Section 12): Discusses object hallucination in image captioning and visual grounding failures in multimodal models.
-
Large Language Models (Section 13): Analyzes emerging hallucination challenges in LLMs, including object existence hallucinations, multimodal misalignment, and the difficulty of expressing knowledge boundaries.
Results¶
Key findings include:
- Hallucination is relatively easy to detect in abstractive summarization against source evidence but much harder in open-domain dialogue and LLM outputs.
- Most mitigation methods in NMT focus on reducing dataset noise or alleviating exposure bias.
- Dialogue systems research predominantly addresses intrinsic hallucination; extrinsic hallucination remains understudied.
- LLMs present novel challenges: they generate fluent, superficially plausible text while having limited ability to model knowledge boundaries.
Connections¶
- Related to Faithfulness NLG and Factual Consistency as complementary evaluation concerns.
- Cited by subsequent work on Reasoning Language Models, Fact Verification, and Retrieval-Augmented Generation.
- Methods like Reinforcement Learning NLG and Post Processing Neural Text are core mitigation approaches.
- Overlaps with Information Extraction and Natural Language Inference used as metric components.
Notes¶
This is the first comprehensive cross-task survey of hallucination in NLG, filling a significant gap in the literature. The survey's scope is ambitious—13 tasks and multiple mitigation dimensions—which makes it a reference point for subsequent work. The observation that hallucination tolerances vary dramatically across tasks (abstractive summarization vs. open-domain dialogue) is important for research design. The treatment of LLMs is timely given their emergence as dominant generation systems, though the authors note that our theoretical understanding of hallucination in LLMs remains limited.