A Survey of Large Language Models¶
Authors: Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yuansheng Du, Chen Yang, Yushuo Chen, Zhiyuan Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, Ji-Rong Wen
Venue: arXiv preprint, 2023 — arXiv:2303.18223
TL;DR¶
This comprehensive survey reviews the evolution of large language models (LLMs) from statistical language models through pre-trained models to contemporary transformer-based LLMs. The authors examine four major dimensions: pre-training strategies, parameter-efficient adaptation methods, utilization approaches (prompting and in-context learning), and alignment techniques for safety and human preference alignment. The survey synthesizes emerging capabilities of LLMs and practical methods for developing and deploying these models across diverse downstream applications.
Contributions¶
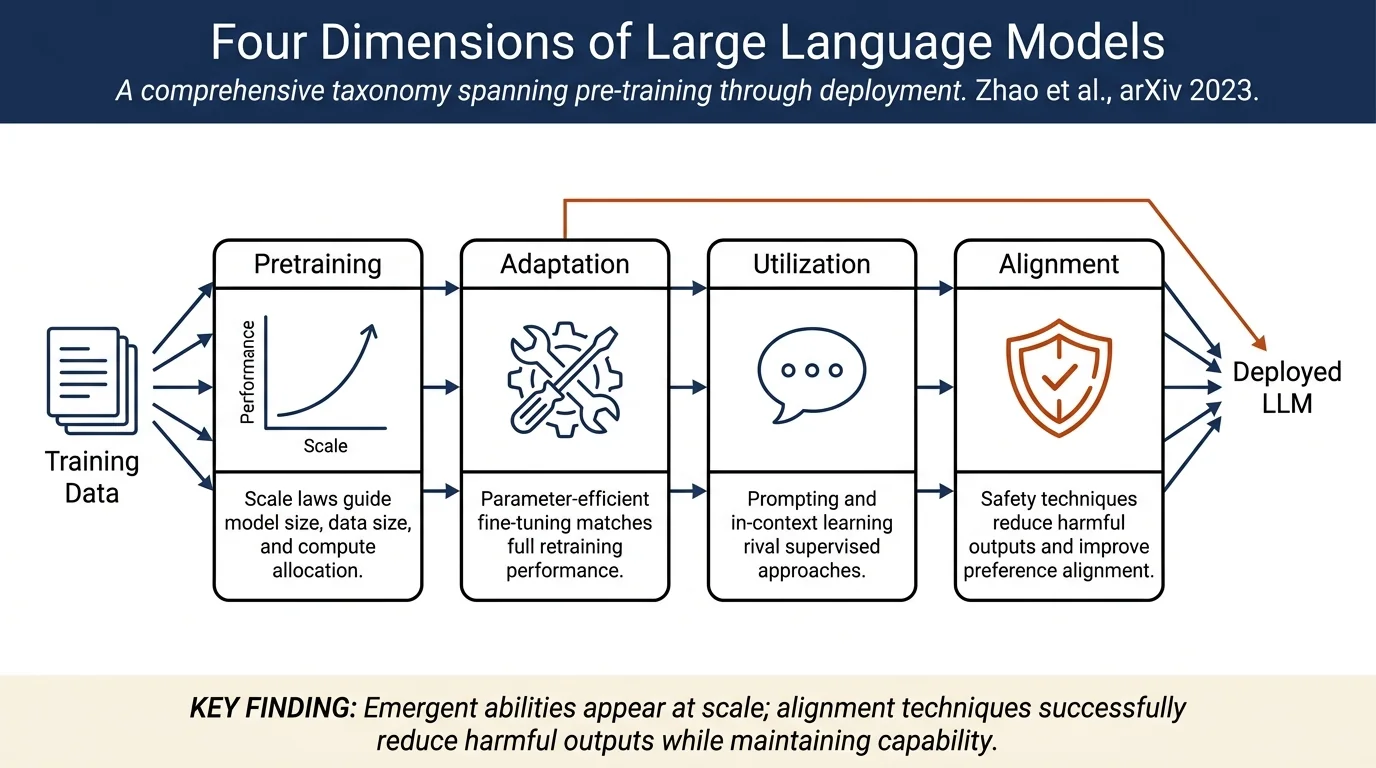
- Comprehensive taxonomy of LLM development across four generations: statistical LMs, neural LMs, pre-trained LMs, and large language models.
- Detailed analysis of pre-training approaches including scaling laws, emergent abilities, and training efficiency.
- Survey of parameter-efficient fine-tuning methods (adapter tuning, prefix tuning, LoRA, prompt tuning) for resource-constrained adaptation.
- Systematic review of utilization techniques including prompting strategies, in-context learning, and chain-of-thought reasoning.
- Examination of alignment methods to make LLMs safe and aligned with human values (RLHF, supervised fine-tuning, DPO, and interactive training).
- Discussion of capacity evaluation, model selection, and practical considerations for deployment.
Method¶
The survey synthesizes literature through historical contextualization and thematic organization. Pre-training covers data collection, model architectures, and scaling laws (e.g., KM scaling law, Chinchilla scaling law) that establish relationships between model size, data size, and compute budget. Adaptation tuning reviews parameter-efficient approaches that fine-tune models for downstream tasks without full retraining. Utilization surveys prompting methods, including manual prompt engineering, automatic prompt optimization, in-context learning with demonstrations, and chain-of-thought reasoning. Alignment discusses making LLMs safe through reinforcement learning from human feedback (RLHF), supervised fine-tuning with human-written examples, direct preference optimization (DPO), and interactive feedback loops. Capacity evaluation addresses how to measure and benchmark LLM abilities across various task categories.
Results¶
The survey establishes that LLMs exhibit several key properties:
- Emergent abilities appear at scale, where smaller models fail but larger ones succeed (e.g., in-context learning, instruction following, arithmetic reasoning).
- Scaling laws are predictable: model performance scales logarithmically with model size, data size, and compute, enabling principled allocation of training budgets.
- Parameter-efficient tuning (LoRA, adapter tuning) can match or approach full fine-tuning with orders of magnitude fewer trainable parameters.
- Prompting effectiveness rivals or exceeds supervised approaches on many tasks; chain-of-thought prompting significantly improves reasoning performance.
- Alignment techniques successfully reduce harmful outputs and improve alignment with human preferences, though trade-offs between capability and safety remain.
The survey documents the rapid evolution of LLM capabilities, from ChatGPT's impact (late 2022) through 2023, showing accelerating progress in model size, training efficiency, and generalization to unseen tasks.
Connections¶
- Related to Prompt Engineering and In-Context Learning which are key utilization techniques for deploying LLMs.
- Related to Model Alignment and Safety which discuss approaches to making LLMs safer.
- Related to Fine Tuning methods for adapting pre-trained models to downstream tasks.
- Related to Transformer Architecture which is the foundation for modern LLMs.
- Related to Emergent Abilities in neural language models as models scale.
Notes¶
This is a broad technical survey covering LLM development and deployment. While it encompasses many technical dimensions, the paper is primarily focused on the engineering and science of building large language models rather than applications to specific domains like misinformation detection. However, the survey's coverage of alignment techniques (safety, preventing harmful outputs) has indirect relevance to preventing malicious uses of LLMs, including potential generation of misinformation or synthetic content. The practical guidance on prompting and in-context learning may inform applications in content moderation and fact-checking, though such applications are not the paper's primary focus.