Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity¶
Authors: Cunxiang Wang, Xiaoze Liu, Yuanhao Yue, Qipeng Guo, Xiangkun Hu, Xiangru Tang, Tianhang Zhang, Cheng Jiayang, Yunzhi Yao, Xuming Hu, Zehan Qi, Wenyang Gao, Yidong Wang, Linyi Yang, Jindong Wang, Xing Xie, Zheng Zhang
Venue: arXiv, 2023 — arXiv:2310.07521
TL;DR¶
This comprehensive survey addresses the critical problem of factuality in large language models, examining how LLMs store and retrieve knowledge, analyzing the mechanisms through which they generate false or misleading content, and reviewing evaluation metrics and enhancement strategies. The paper distinguishes factuality issues from hallucinations and offers a structured taxonomy of the literature across standalone LLMs and retrieval-augmented configurations.
Contributions¶
- Defines factuality in LLMs and distinguishes it from related concepts like hallucinations and outdated information
- Provides exhaustive categorization of evaluation metrics (rule-based, neural, human-based, and LLM-based approaches)
- Catalogs benchmarks for evaluating LLM factuality across diverse domains (medical, legal, finance, etc.)
- Analyzes mechanisms through which LLMs generate factual errors including model-level, retrieval-level, and inference-level causes
- Examines enhancement strategies including retrieval-augmented generation, fine-tuning, and domain-specific optimization
- Distinguishes factuality challenges in two primary configurations: standalone LLMs and retrieval-augmented LLMs
Factuality Problem¶
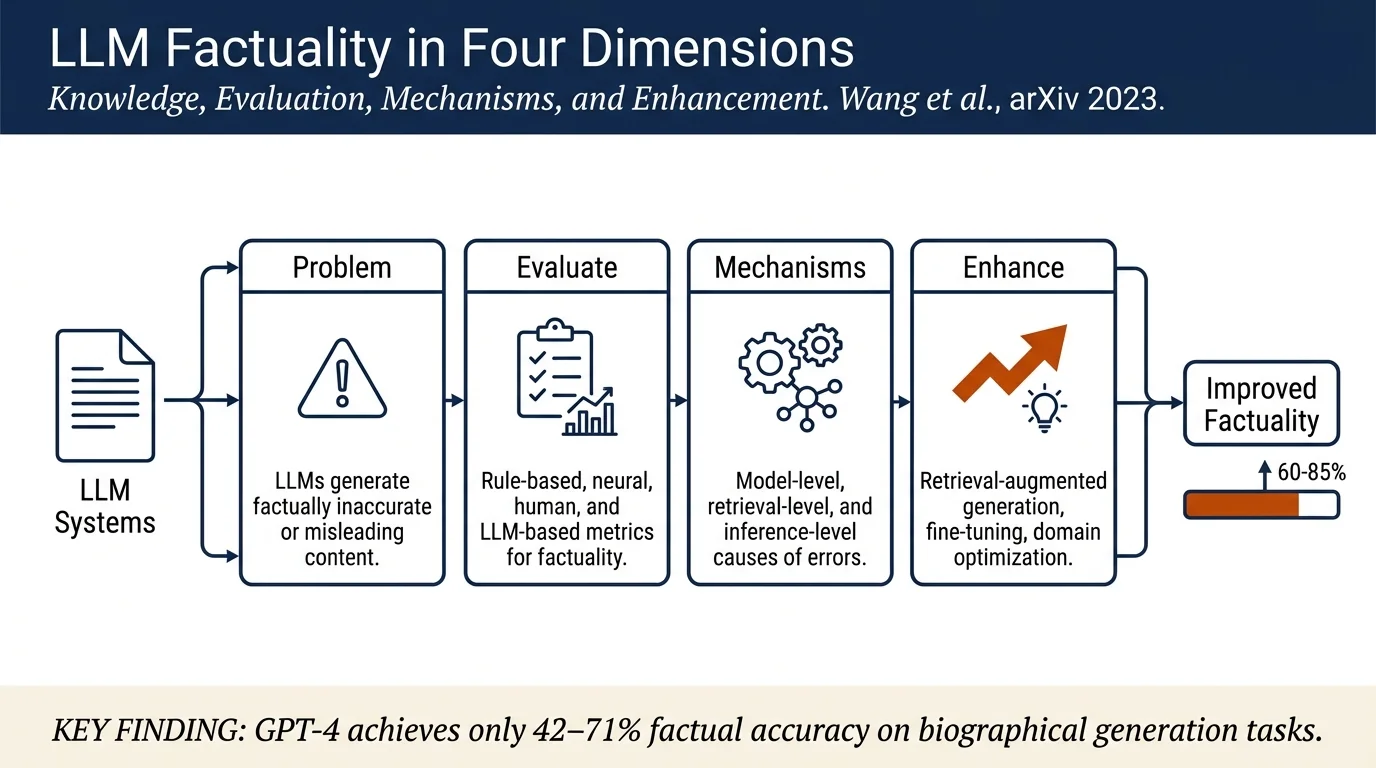
LLMs exhibit a fundamental tension between their powerful generative capabilities and their propensity to generate false or misleading content. Factuality—the model's ability to produce outputs consistent with established facts—is essential as LLMs become integrated into high-stakes applications (medical diagnosis, legal decisions, financial advice). The paper defines factuality issues as arising from three sources: insufficient factual knowledge, inability to accurately retrieve stored knowledge, and failure to properly utilize retrieved information at inference time.
Evaluation Metrics¶
The survey systematically reviews metrics across four categories:
Rule-based metrics (Exact Match, Common Metrics, Calibration, Brier Score) measure agreement with ground-truth text or probabilistic accuracy. These are consistent and implementable but may not account for language variation.
Neural evaluation metrics (ADEM, BERTScore, BLEU, ROUGE, METEOR, QUIP-Score) compare model outputs to reference text using learned representations. They provide finer-grained semantic matching but may introduce bias from the evaluation model.
Human evaluation metrics rely on expert judgment and capture nuances that automated approaches miss, but are time-consuming and subjective. Metrics include Attribution (whether outputs cite verifiable sources) and FActScore (breaking generated text into atomic facts and verifying each).
LLM-based metrics (GPTScore, GPT-judge, Truthfulness and Informativeness metrics, LLM-Eval) leverage LLM capabilities for efficient evaluation. These offer scalability and adaptability across domains but may inherit biases from the evaluator model itself.
Benchmarks¶
The paper catalogs major factuality evaluation benchmarks including: - MMLU (multi-choice QA across 57 subjects) - TruthfulQA (designed to reveal hallucinations and false beliefs) - C-Eval (Chinese domain knowledge evaluation) - BigBench (204 tasks across diverse domains) - HaluEval (comprehensive hallucination evaluation) - Various domain-specific benchmarks (USLE for medical knowledge, C-Eval Hard for rigorous challenges)
Enhancement Strategies¶
The survey identifies mechanisms for improving factuality:
Retrieval-Augmented LLMs integrate external knowledge sources at inference time, providing access to current information while reducing reliance on parametric knowledge alone.
On-Retrieval methods including prompt-based approaches (e.g., self-retrieval, multi-agent systems), SPT-based retrieval, and normal RAG configurations.
Enhancement via domain-specific fine-tuning tailoring models to specialized knowledge domains.
Pretraining on high-quality, factually accurate corpora.
Knowledge-grounded decoding and other inference-time modifications.
Key Findings¶
- Existing LLMs, even state-of-the-art models like GPT-4, exhibit significant factual inaccuracies (FActScores ranging from 42% to 71% on biography generation)
- Factuality issues in LLMs can have profound societal impacts (legal errors, medical misjudgments, financial losses)
- Retrieval-augmented approaches show promise but introduce new challenges around knowledge source quality and selection
- Domain-specific evaluation and enhancement are essential; general-purpose metrics often miss domain-critical knowledge requirements
Connections¶
- Related to Hallucination Detection in understanding and mitigating false output generation
- Cited by and builds upon work on Fact-checking and corrections and Claim Verification methodologies
- Complements Misinformation and fake news detection literature by focusing on LLM-specific generation challenges
- Extends understanding of Knowledge Representation In Neural Networks through the lens of retrieval and factuality
- Intersects with Information Retrieval work on integrating external knowledge sources
Notes¶
Strengths: - Comprehensive and well-organized taxonomy of a rapidly evolving field - Distinguishes factuality from related concepts with clarity; many prior works conflate hallucination and factuality issues - Extensive catalog of evaluation metrics and benchmarks with honest assessment of tradeoffs (rule-based simplicity vs. human evaluation nuance) - Covers both technical mechanisms (knowledge storage/retrieval) and practical applications - Acknowledges domain-specificity as a critical dimension often overlooked in general surveys
Limitations: - Published in late 2023; the field has accelerated rapidly (e.g., emergence of stronger models with better parametric knowledge, post-training techniques like RLHF refinements) - Some benchmarks discussed may already be superseded; regular updates recommended - Limited discussion of emerging approaches like chain-of-thought prompting for factuality improvement - Enhancement strategies section could benefit from more empirical comparison tables
Research Gaps: - Integration of factuality improvements into the broader safety and alignment agendas - Temporal dynamics of factual knowledge degradation in deployed systems - Cost-accuracy tradeoffs in retrieval-augmented approaches at scale - Cross-lingual and culturally-specific factuality challenges