A Survey on Evaluation of Large Language Models¶
Authors: Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, Xing Xie
Venue: Journal of the ACM, Vol. 37, No. 4, Article 111 — arXiv:2207.03109
TL;DR¶
This survey provides a comprehensive review of evaluation methodologies for large language models across three dimensions: what to evaluate, where to evaluate, and how to evaluate. The paper encompasses evaluation tasks spanning natural language processing, natural language generation, robustness, ethics, bias detection, trustworthiness, and social science applications. The authors synthesize 269 papers to illuminate the state of LLM evaluation and identify critical future research directions.
Contributions¶
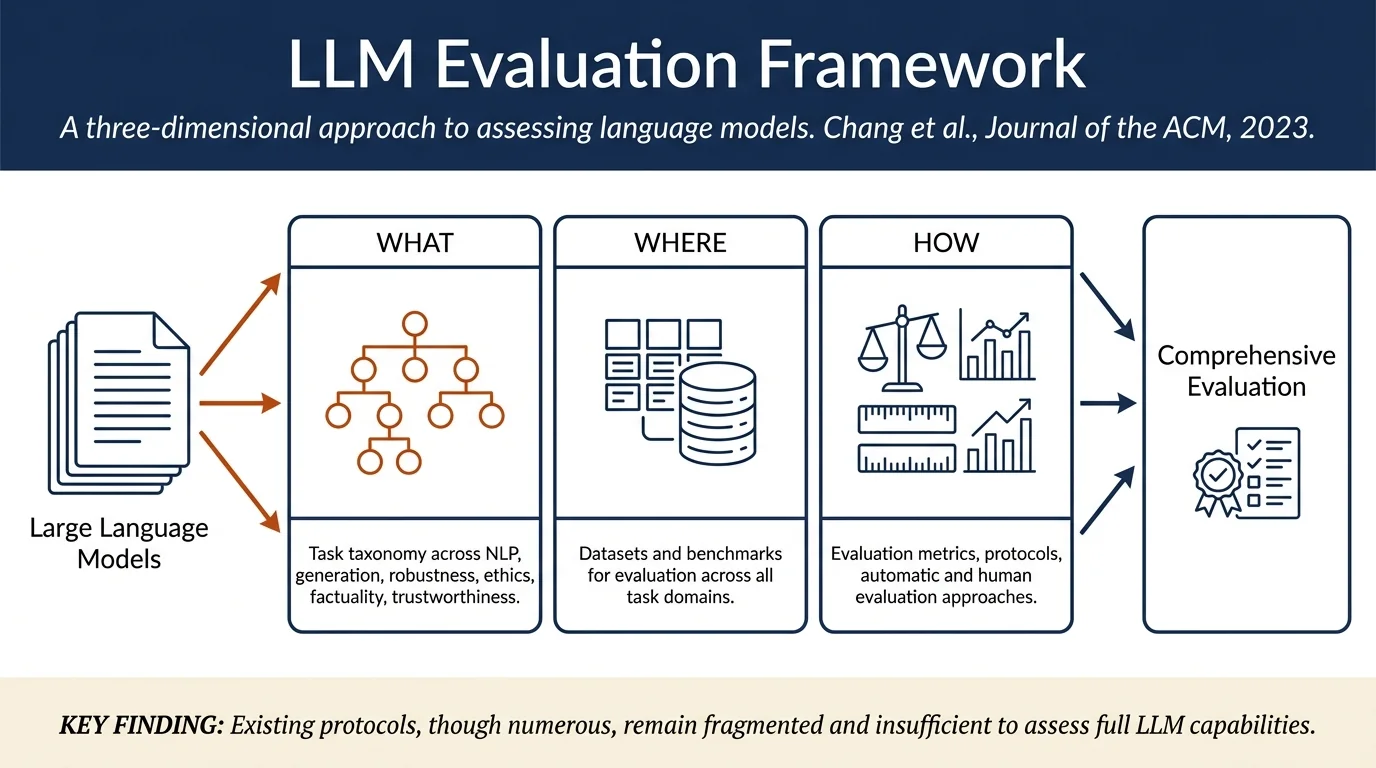
- Comprehensive framework: Organizes LLM evaluation across three dimensions—what to evaluate (task categories), where to evaluate (datasets and benchmarks), and how to evaluate (metrics and protocols).
- Task taxonomy: Categorizes evaluation tasks including natural language understanding, generation, reasoning, social knowledge, robustness, ethics, factuality, and multimodal capabilities.
- Critical gap analysis: Documents the disconnect between evaluation breadth and depth, highlighting that existing protocols may be insufficient for assessing true LLM capabilities across safety-sensitive domains.
- Future challenges: Identifies unmet needs in LLM evaluation, particularly for safety-critical applications in healthcare and finance, and emphasizes the importance of multifaceted evaluation frameworks.
Method¶
The paper follows a systematic literature review approach, analyzing existing LLM evaluation work across multiple dimensions:
What to evaluate: The authors categorize evaluation into eight major domains: - Natural language processing (NLP) tasks: Sentiment analysis, text classification, natural language inference, semantic understanding, reasoning, and other core NLP benchmarks - Natural language generation (NLG) tasks: Summarization, dialogue generation, machine translation, question answering, and other generation tasks - Robustness: Out-of-distribution generalization and adversarial attacks - Ethical concerns: Bias detection, toxicity, fairness, and social harms - Factuality/hallucination: Assessment of whether generated content is grounded in reality - Trustworthiness: Overall reliability and safe deployment - Social science applications: Computational social science, legal reasoning, and case law judgment - Domain-specific evaluation: Medical, educational, and specialized applications
Where to evaluate: The survey catalogs existing datasets, benchmarks, and evaluation frameworks across all these categories, providing a structured overview of the evaluation ecosystem.
How to evaluate: The paper synthesizes evaluation metrics, protocols, and methodologies, including both automatic metrics and human evaluation approaches.
Results¶
Key findings include:
- NLP task performance: LLMs (especially ChatGPT and GPT-4) achieve strong performance on sentiment analysis and text classification, competitive reasoning abilities (with caveats on symbolic reasoning), and emerging semantic understanding. Performance remains mixed on tasks requiring grounded knowledge or exact reasoning.
- Generation quality: LLMs excel at summarization and dialogue but struggle with consistent translation to low-resource languages and sometimes underperform on structured generation tasks.
- Robustness concerns: Models show vulnerability to adversarial inputs and distribution shifts; adversarial robustness remains a challenge.
- Ethical issues: LLMs reproduce training data biases; toxicity and social bias remain problematic despite improvements.
- Factuality: Hallucination—generating plausible but false information—is a critical failure mode. Current detection methods are incomplete.
- Trustworthiness: While LLMs show promise on many dimensions, comprehensive trustworthiness evaluation is underdeveloped.
The paper emphasizes that existing evaluation protocols, though numerous, are fragmented and often insufficient to capture the full scope of LLM capabilities and limitations.
Connections¶
- Related to A Survey of Large Language Models via shared focus on LLM foundations and capabilities; the Zhao paper covers pre-training and scaling while Chang et al. focus on downstream evaluation.
- Related to Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity on the specific problem of hallucination and factuality evaluation, a major component of the Chang survey.
- Contributes to LLM assessment frameworks used in evaluating models for misinformation detection applications.
- Informed by foundational work on NLP evaluation standards and dataset curation.
Notes¶
This survey is important for the fake news wiki because:
- Factuality assessment: A substantial section addresses hallucination and factuality evaluation, directly relevant to deploying LLMs for fact-checking and misinformation detection.
- Trustworthiness and bias: The coverage of ethical evaluation, bias detection, and trustworthiness is critical for understanding whether LLMs can reliably assess claims for veracity.
- Robustness: The discussion of adversarial robustness and out-of-distribution generalization applies to adversarially crafted disinformation.
- Comprehensive scope: The breadth of the survey (269 papers, multiple task domains) makes it a canonical reference for understanding LLM evaluation landscape, including limitations that are pertinent to safety-critical misinformation detection tasks.
The paper is notably human-readable compared to highly technical evaluation papers, making it a good entry point for understanding what we can and cannot reliably test in LLMs before deployment in misinformation contexts.