Scalable and Generalizable Social Bot Detection through Data Selection¶
Authors: Kai-Cheng Yang, Onur Varol, Pik-Mai Hui, Filippo Menczer
Venue: arXiv, November 2019 — arXiv:1911.09179
TL;DR¶
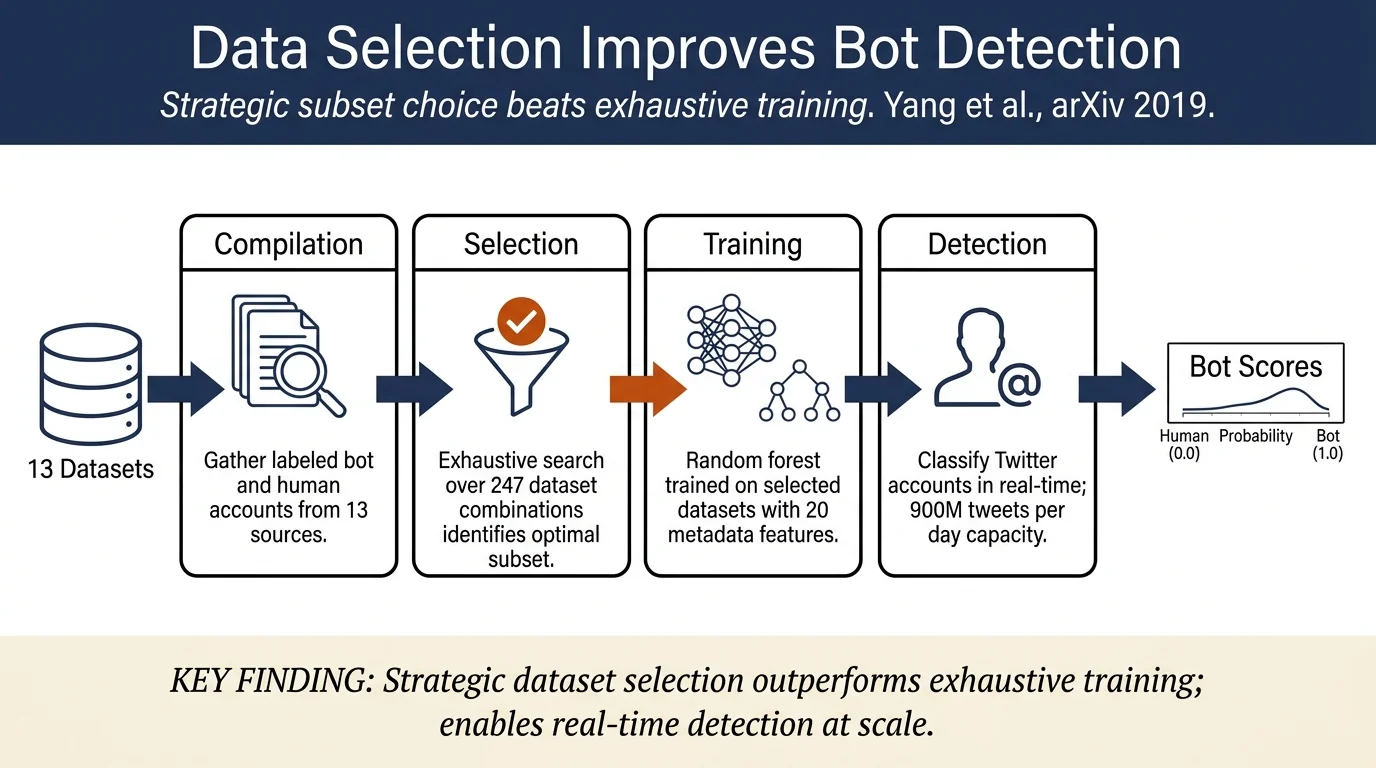
This paper addresses scalability and generalization challenges in social bot detection by proposing a framework using only 20 user metadata features, enabling real-time analysis of the full Twitter stream. The key insight is that strategic data selection—training on a carefully chosen subset of 13 compiled datasets—achieves better generalization and consistency than exhaustively training on all available data.
Contributions¶
- Framework for scalable bot detection using minimal metadata: achieves 900M tweets/day classification speed, exceeding Twitter Firehose capacity
- Compilation and systematic analysis of 13 labeled bot/human datasets (94,124 bots, 43,396 humans) from literature and three newly-created sources
- Quantitative analysis of dataset characteristics: shows separability and generalizability are uncorrelated; some datasets have contradictory labels suggesting labeling noise and fundamental feature limitations
- Data selection methodology: exhaustive search over 247 dataset combinations to identify training sets optimizing cross-validation accuracy, cross-domain generalization, and consistency with Botometer
- Evidence that careful subset selection (model M196) outperforms training on all data (model M246) in generalization tests
- Interpretability: with only 20 features, SHAP explains which characteristics signal bot behavior (e.g., high friends growth, low favorites—bots expand networks without organic engagement)
Method¶
Features: 20 user metadata features extracted from Twitter API user object: statuses count, followers count, friends count, favourites count, listed count, verified status, default profile, profile background image, and derived features (growth rates, ratios, screen name characteristics). The screen name likelihood feature uses 2M+ unique screen names to detect random naming patterns via bigram likelihood.
Datasets: Compiled 13 datasets: caverlee (honeypot-based), varol-icwsm (manually labeled from bot score deciles), cresci-17 (fine-grained: spambots, social spambots, fake followers), pronbots (scam bots), celebrity, vendor-purchased (paid followers), botometer-feedback (flagged by tool users), political-bots, gilani-17 (undergrad-annotated), cresci-rtbust (Italian retweets), cresci-stock (stock-related), midterm-18 (2018 U.S. election), botwiki (self-identified), verified (balance class).
Dataset Analysis: PCA visualization and homogeneity scoring show five datasets with clear bot/human separation; others (cresci-stock, varol-icwsm) are difficult due to coordination-based labeling or low inter-annotator agreement (75%). Cross-dataset AUC matrix reveals contradictory patterns: training on dataset X and testing on Y sometimes yields AUC < 0.5, indicating datasets with opposite labels and highlighting the noise and feature-space gaps in bot detection.
Data Selection: Trained 247 random forest models (one per dataset combination). Evaluated each via five-fold cross-validation, cross-domain tests on four holdout datasets (botwiki-verified, midterm-18, gilani-17, cresci-rtbust), and correlation with Botometer on 100k random accounts. Selected the model with minimal product of ranks across six evaluation metrics—balancing performance rather than maximizing any single metric.
Evaluation: Strict validation system: cross-validation accuracy, cross-domain generalization (unseen datasets), and consistency with reference tool (Botometer).
Results¶
Data Selection Effectiveness: - Model M196 (best model): trained on caverlee, varol-icwsm, cresci-17, celebrity, botometer-feedback, political-bots with AUC 0.99 on botwiki-verified and midterm-18 (vs. Botometer's 0.92 and 0.96) - M196 achieves higher precision across holdout datasets at 0.5 threshold compared to Botometer - M246 (all data): AUC 0.91 and 0.83 on same tests—selective training beats exhaustive training - M196 five-fold cross-validation AUC: 0.98; correlation with Botometer on 100k random accounts: Spearman's r = 0.60
Scalability: - Classification: 9.612 ± 0.00006 seconds per account, enabling 900M tweets/day (exceeds Firehose's 500M/day) - 200× faster than Botometer (which requires 200 tweets per account and user mentions) - Users lookup API rate: 8.6M accounts/day (vs. 43.2k/day for feature-rich methods)
Interpretability (SHAP): - Long screen names, high friends count, high friends growth rate → bot-like - Verified status, high favorites count, high followers count, high followers/friends ratio → human-like - Bots eagerly add friends but don't attract followers; humans show organic engagement patterns
Connections¶
- Extends The Rise of Social Bots and Arming the public with artificial intelligence to counter social bots by proposing scalable detection and analyzing generalization across bot datasets
- Builds on The spread of low-credibility content by social bots showing bots amplify false information
- Relates to Online Human-Bot Interactions: Detection, Estimation, and Characterization on bot behavior and detection
- Uses datasets and methods from Cresci et al. 2017 and Anatomy of an online misinformation network
- Complements Bots increase exposure to negative and inflammatory content in online social systems on bot activity in specific contexts
- Addresses generalization challenges raised in de Cristofaro & Lobo (2018) on cross-domain bot detection failures
Notes¶
Strengths: - First systematic analysis of contradictions across bot datasets—reveals fundamental labeling noise and feature-space limitations - Practical insight: data selection beats exhaustive training, with implications for other noisy domains (speech recognition, emotion detection) - Scalable to real-time stream analysis, enabling large-scale studies - Transparent evaluation: cross-domain validation, holdout testing, consistency with established tools - Highly interpretable 20-feature model; SHAP analysis provides actionable insights - Reproducible: curated datasets published in bot repository
Weaknesses: - 20 features capture only a "tiny portion" of account characteristics (authors' words); methods requiring timeline, content, or social network still outperform on some datasets (e.g., cresci-rtbust) - Cross-domain performance drops on two difficult datasets: gilani-17 and cresci-rtbust (both AUC ~0.68 vs. 0.92 on others), suggesting limits to metadata-only approaches - Feature selection not optimized; threshold choice (0.48 vs. 0.32 for cross-validation vs. cross-domain) requires dataset-specific tuning - Doesn't detect coordinated behavior (explicitly out of scope), only individual account classification
Future directions: - Smarter data selection algorithms beyond exhaustive search - Adaptive thresholds or per-dataset calibration - Integration with network/temporal methods to detect coordinated inauthentic behavior - Generalization analysis on non-Twitter platforms