Online Human-Bot Interactions: Detection, Estimation, and Characterization¶
Authors: Onur Varol, Emilio Ferrara, Clayton A. Davis, Filippo Menczer, Alessandro Flammini
Venue: arXiv preprint, 2017 — arXiv:1703.03107
TL;DR¶
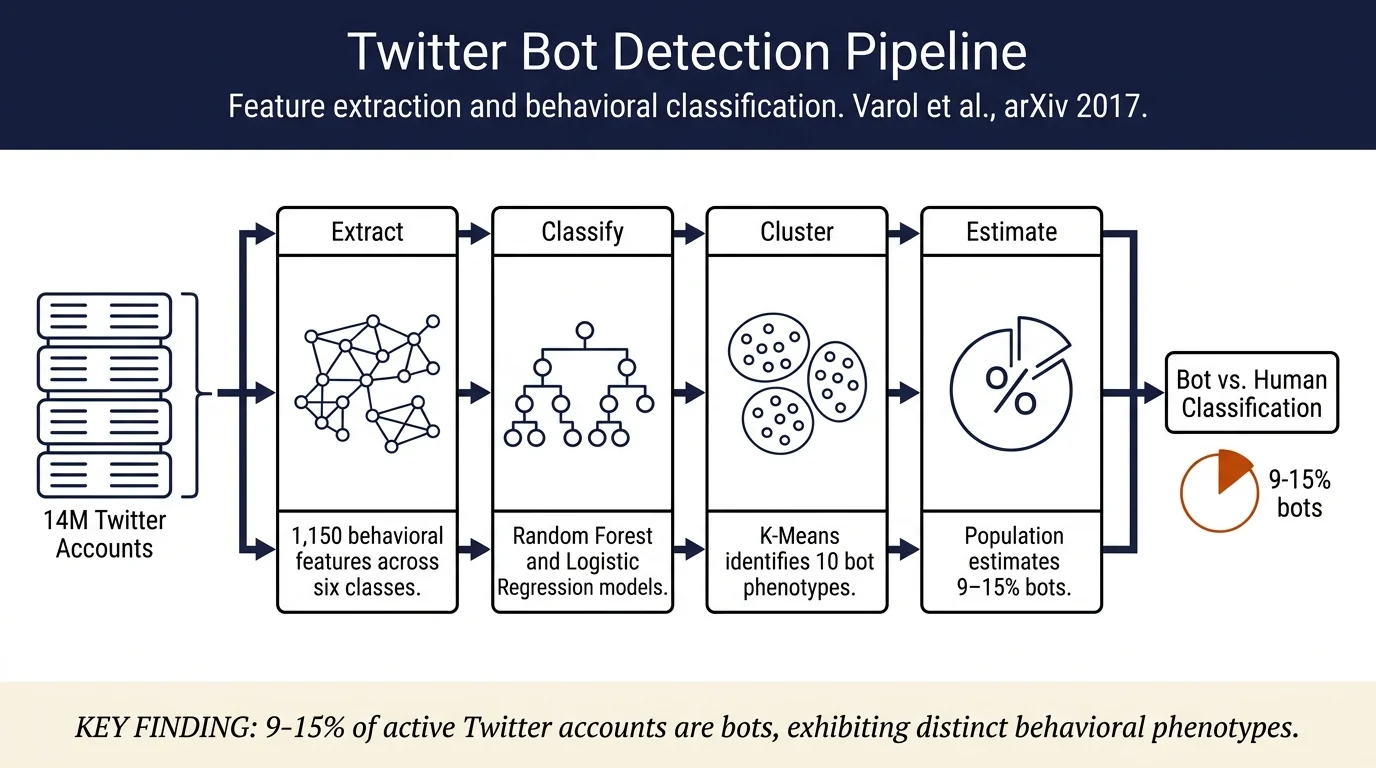
Social media accounts controlled by software can mimic human behavior while executing coordinated campaigns. This paper develops a machine-learning framework extracting 1,150 behavioral features from Twitter account metadata, posting patterns, and social networks to classify bots with 95% accuracy on honeypot data. Large-scale evaluation on 14M Twitter accounts estimates that 9–15% of active users are bots; clustering analysis reveals distinct bot behavioral phenotypes (spammers, self-promoters, coordinated propaganda accounts).
Contributions¶
- Framework extracting 1,150 features across six feature classes (user metadata, temporal patterns, content statistics, sentiment, network structure, interaction behavior) to enable scalable bot detection via supervised learning
- Large-scale dataset of 14M Twitter users with honeypot and newly-annotated bot/human labels; evaluation on diverse account samples to assess model generalization
- Estimation that 9–15% of active Twitter accounts exhibit bot behavior, with population estimates sensitive to classification threshold choice
- Clustering-based analysis of bot behavioral phenotypes; identification of 10 distinct clusters with signature behaviors (e.g., accounts posting content from connected applications, accounts promoting tweets, accounts with legit-looking profiles but low human interaction)
- Empirical analysis of social connectivity and information-flow patterns between human and bot accounts; evidence that bots have different interaction strategies than humans
Method¶
The paper develops a supervised machine-learning bot detection system using features extracted from the Twitter API:
Feature extraction: 1,150 features organized into six classes: - User-based features: screen name length, user account age, default profile picture, friend/follower counts and distributions - Friends features: follower/following relationships, link types (retweets, mentions, replies) - Network features: retweet networks, mention networks, hashtag co-occurrence networks; in/out-strength, clustering coefficients, network density - Temporal features: tweet frequency, time-of-day patterns, inter-tweet intervals, activity bursts - Content features: tweet length, hashtag frequency, URL frequency, POS tags, entropy measures - Sentiment features: polarity and valence scores from sentiment lexicon
Classification: Random Forest, Logistic Regression, Decision Trees trained on manually-annotated data. Model evaluation via 5-fold cross-validation and AUC (Area Under the Receiver Operating Characteristic Curve).
Data collection: Twitter accounts restricted to English-speaking users; sampled via 10% random stream from October 2015 (~14M accounts); pruned to active users (≥200 tweets and ≥90 tweets in 3-month observation window). Manual annotation of 800 bot-sample accounts by crowdsourced workers with disagreement resolution yielded final annotated dataset of 1,800 accounts (900 human, 900 bot).
Dataset effects: Authors created multiple balanced and mixed-ratio training/test splits to investigate model robustness: - Annotation-only dataset: 800 newly annotated accounts (AUC 0.89) - Merged dataset: Combined honeypot (1,500 labeled bots from prior work) + annotation (AUC 0.94) - Mixture experiments: Varied ratios of honeypot/annotation data to study training data composition
Results¶
Detection performance: On newly-annotated (manual) dataset, Random Forest achieves 0.89 AUC; merged dataset (honeypot + manual) yields 0.94 AUC. When trained on honeypot (older data) and tested on new annotation, accuracy drops to 0.86 AUC, indicating concept drift—older bot definitions misclassify newer accounts. Feature-importance analysis ranks user metadata, content features (sentiment, POS), and network statistics as most predictive.
Bot population estimation: Using different thresholds on classifier score: - Conservative estimate (0.0–1.0 classifier score range): 9% of accounts are bots - Aggressive estimate: 15% of active Twitter accounts are bots - Estimate heavily dependent on threshold choice and model definition of "bot"
Bot behavioral phenotypes: Clustering (K-Means on 100 top features via Gini impurity) identifies 10 distinct behavioral clusters: - C0: Legitimate-looking accounts promoting themselves; low follower count, low engagement - C1–C2: Spam and self-promotion accounts; high posting frequency, low followers - C3: Accounts from connected applications (automated news feeds, Instagram/YouTube relay); post frequently, have few social interactions - C4–C9: Mixed behaviors including accounts with sophisticated patterns (intermediate classifier scores), accounts engaging with bots, accounts showing bot-like temporal signatures but plausible content
Social connectivity: Bots and humans show asymmetric interaction patterns: - Bots rarely mention or interact with humans; humans (low-score accounts) occasionally mention bots - Humans are reciprocally followed by both humans and bots; sophisticated bots (high classifier scores) tend to follow bots while being followed primarily by bots - Information flow asymmetry: Bots retweet human content; humans rarely retweet bot content; simple bots retweet other bots
Temporal differences: Bot accounts show different temporal posting patterns than humans—posting rates, inter-post intervals, and activity bursts differ significantly, providing temporal signals for classification.
Connections¶
- Related to Ferrara et al. (2015) — The Rise of Social Bots — earlier foundational survey organizing bot detection taxonomy and characterizing bot sophistication; this work extends with large-scale empirical evaluation and population estimation
- Builds on Stukal et al. (2017) — Detecting Bots on Russian Political Twitter — parallel large-scale bot detection effort using ensemble methods on political Twitter during geopolitical events
- Informs Linvill & Warren (2020) — Troll Factories — characterization of specialized bot behavioral types for propaganda purposes
- Connected to Stella, Ferrara & De Domenico (2018) — Bots increase exposure to negative and inflammatory content — analysis of bot amplification strategies during political crisis
- Related to information operations and social bots as tools for coordinated campaigns
- Methodologically related to Shu et al. (2019) — The Role of User Profiles for Fake News Detection — use of account-level metadata for classification
Notes¶
This work makes three main contributions: (1) a comprehensive feature engineering framework demonstrating that metadata and behavioral signals are sufficient for bot detection, (2) a realistic large-scale evaluation showing that model generalization degrades substantially when test data includes newer, more sophisticated bots, and (3) population-level estimates with explicit uncertainty about bot prevalence.
The paper's honest treatment of concept drift is valuable—models trained on honeypot data (from prior work) generalize poorly to newly-annotated accounts, suggesting the bot detection arms race is real and detection methods must continually adapt. The feature-importance analysis usefully prioritizes user-metadata features (account age, follower ratios, profile characteristics) over complex content features, supporting the practical insight that sophisticated bots can mimic content but behavioral metadata provides stronger signals.
The clustering analysis reveals operational diversity in bot behavior: not all bots are propaganda machines; many are news feeds, personal-promotion accounts, or relay services. This nuance is often lost in polarized "bot vs. human" framing.
Limitations: The manual annotation process is labor-intensive and subject to annotator disagreement (the paper reports 79% inter-annotator agreement, moderately high); the restriction to English-speaking users limits cross-cultural applicability; and the paper (written in 2016–2017) predates sophisticated recent bot architectures leveraging LLM-generated content and multi-account coordination strategies. The population estimates (9–15%) are sensitive to threshold choice and model definition, making it difficult to claim a precise bot prevalence; the range reflects genuine uncertainty rather than a precise count.
Despite these limitations, the work remains a valuable reference for bot detection methodology, feature selection, and the pitfalls of generalization in adversarial settings.