Arming the public with artificial intelligence to counter social bots¶
Authors: Kai-Cheng Yang, Onur Varol, Clayton A. Davis, Emilio Ferrara, Filippo Menczer
Venue: arXiv, February 2019 — arXiv:1901.00912
TL;DR¶
This paper reviews social bot types, their impact on online discourse, and detection methods, then presents Botometer as a case study in how detection tools are used and interpreted by the public. The authors conducted a user experience survey (731 participants) revealing that while users find the tool useful, they struggle with interpreting bot scores and misunderstand what the raw scores mean probabilistically. The paper proposes calibration methods (including Complete Automation Probability) to make bot detection scores more interpretable and actionable.
Contributions¶
- Comprehensive literature review of social bot characterization, activity, and impact on political discourse, health debates, and misinformation spread
- Review of existing bot detection methods including supervised, unsupervised, and hybrid approaches
- Case study of Botometer: user experience survey showing how the public interacts with and interprets bot detection tools
- Empirical evidence that classifier outputs are often misinterpreted: users expect probabilistic outputs but receive raw classification scores
- Calibration methodology to transform raw classifier scores into properly calibrated probabilities using Platt scaling
- Introduction of Complete Automation Probability (CAP) metric, a Bayesian posterior probability that accounts for the base rate of bots in the population
- Analysis of bot detection model generalization across diverse bot datasets (caverlee, ICSM, Cresci-17, pornbots, celebrity accounts, etc.)
- Discussion of the need to continuously update detection models as bot behavior evolves
Method¶
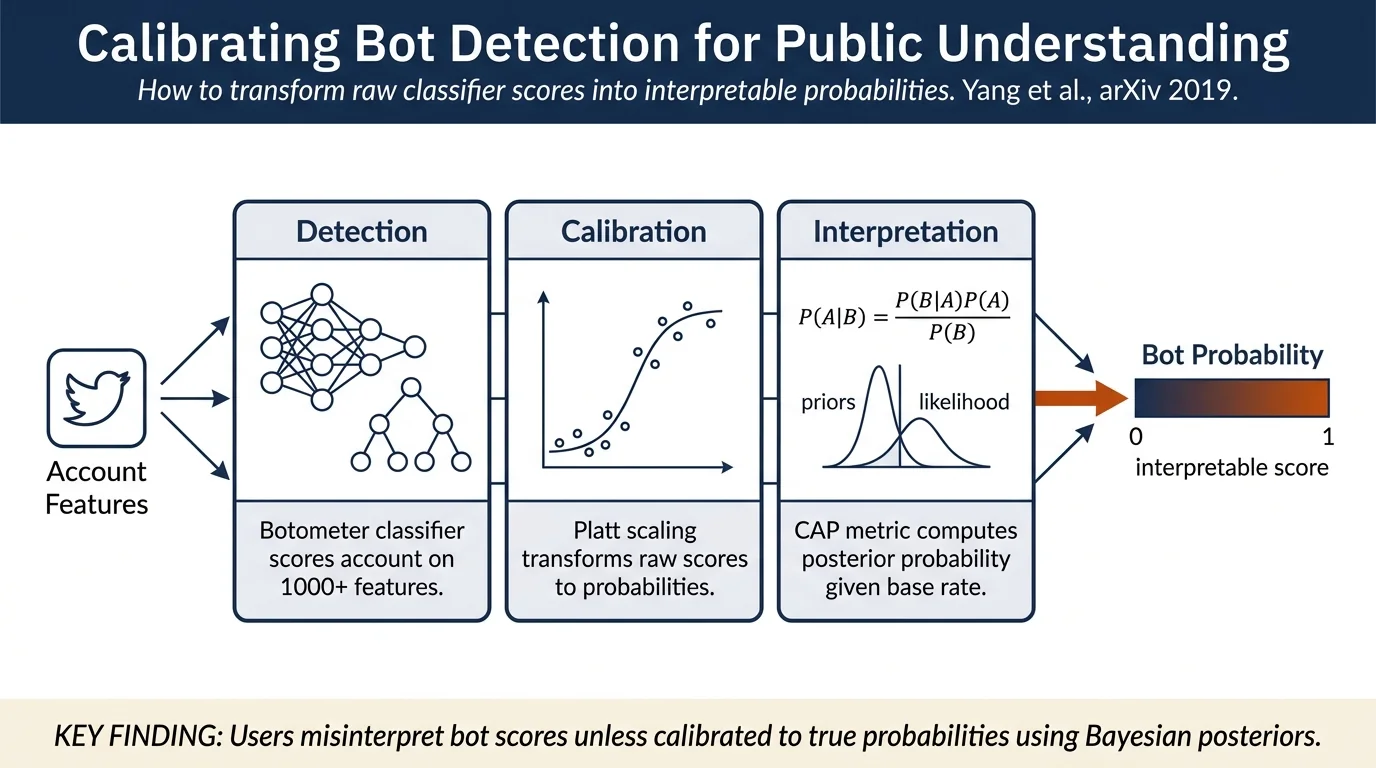
Botometer is a Random Forest classifier trained on 1,000+ features extracted from Twitter account metadata and behavior. The paper focuses on three key methodological innovations:
User Experience Study: The authors surveyed 731 visitors to the Botometer website with two required questions and optional free-text responses. They examined how often users employ the tool, perceived accuracy, interpretability of scores, and error concerns.
Model Calibration: The raw classifier outputs are not probabilities and tend to cluster in the middle range, confusing users about whether a score of 0.5 indicates "definitely not a bot," "50/50 chance," or "definitely a bot." The authors applied Platt scaling to produce calibrated probabilities. They then introduced a more principled Bayesian approach using Complete Automation Probability: $\(P(\text{Bot} \mid S) = P(\text{Bot}) \frac{P(S \mid \text{Bot})}{P(S)}\)$
This computes the posterior probability that an account is a bot given its score, accounting for the prior probability that a random account is automated (~9-15% on Twitter).
Model Generalization: The paper trained multiple versions of Botometer (v1 through v3) on progressively larger and more diverse datasets. They evaluated cross-dataset generalization, finding that models trained on richer datasets generalize better across unseen bot types (spam bots, fake followers, etc.) without degradation.
Results¶
User Survey Findings: - >80% of users believe Botometer accurately classifies bots and humans - Over 80% find the bot scores easy to understand - Roughly equal concern about false positives (humans labeled as bots) and false negatives (bots labeled as humans), varying by usage frequency - Users interpret bot scores as probabilities, despite the classifier producing raw decision function outputs - Survey responses changed after May 2018 update: 39.7% reported the new version much better, 46.1% little better, 9.8% worse
Calibration Results: - Calibrated scores align more closely with true positive rates across the [0,1] range - Complete Automation Probability provides a more conservative (and interpretable) posterior probability than raw scores - Reliability diagrams show calibrated curves are closer to the diagonal (ideal case)
Generalization: Model accuracy improved from 0.95 to 0.97 AUC as new datasets were added. The model generalizes across bot types (honeypot, spam, fake followers, celebrity, vendor-purchased accounts), maintaining high accuracy across diverse bot behaviors.
Connections¶
- Extends The Rise of Social Bots by providing detection tools and studying their public adoption
- Related to The spread of low-credibility content by social bots on the role of bots in spreading low-credibility content
- Complements Online Human-Bot Interactions: Detection, Estimation, and Characterization on how humans interact with bots
- Uses datasets from honeypot-based approaches (Caverlee et al.) and Cresci et al.'s bot collections
- Addresses concerns raised in Anatomy of an online misinformation network about bot-driven amplification of false news
Notes¶
Strengths: - First empirical study of how non-experts interact with and interpret bot detection tools—a critical gap in the research - Practical calibration methods grounded in statistical theory (Platt scaling, Bayesian inference) - Comprehensive dataset curation and generalization testing - Honest about limitations: users misunderstand scores even after calibration improvements
Weaknesses: - User survey limited to Botometer website visitors (selection bias toward active users) - Complete Automation Probability requires estimating base rate of bots, which varies by context and platform - The paper focuses on detection but doesn't deeply address why detection alone is insufficient—effective countermeasures also require platform cooperation and policy
Future directions: - Extending calibration methods to other bot detection tools and domains - Testing whether better explanations (beyond calibration) improve user understanding - Studying the interaction between bot detection, platform transparency, and user behavior change