Predicting Factuality of Reporting and Bias of News Media Sources¶
Authors: Ramy Baly, Georgi Karadzhov, Dimitar Alexandrov, James Glass, Preslav Nakov
Venue: arXiv preprint, 2018 — arXiv:1810.01765
TL;DR¶
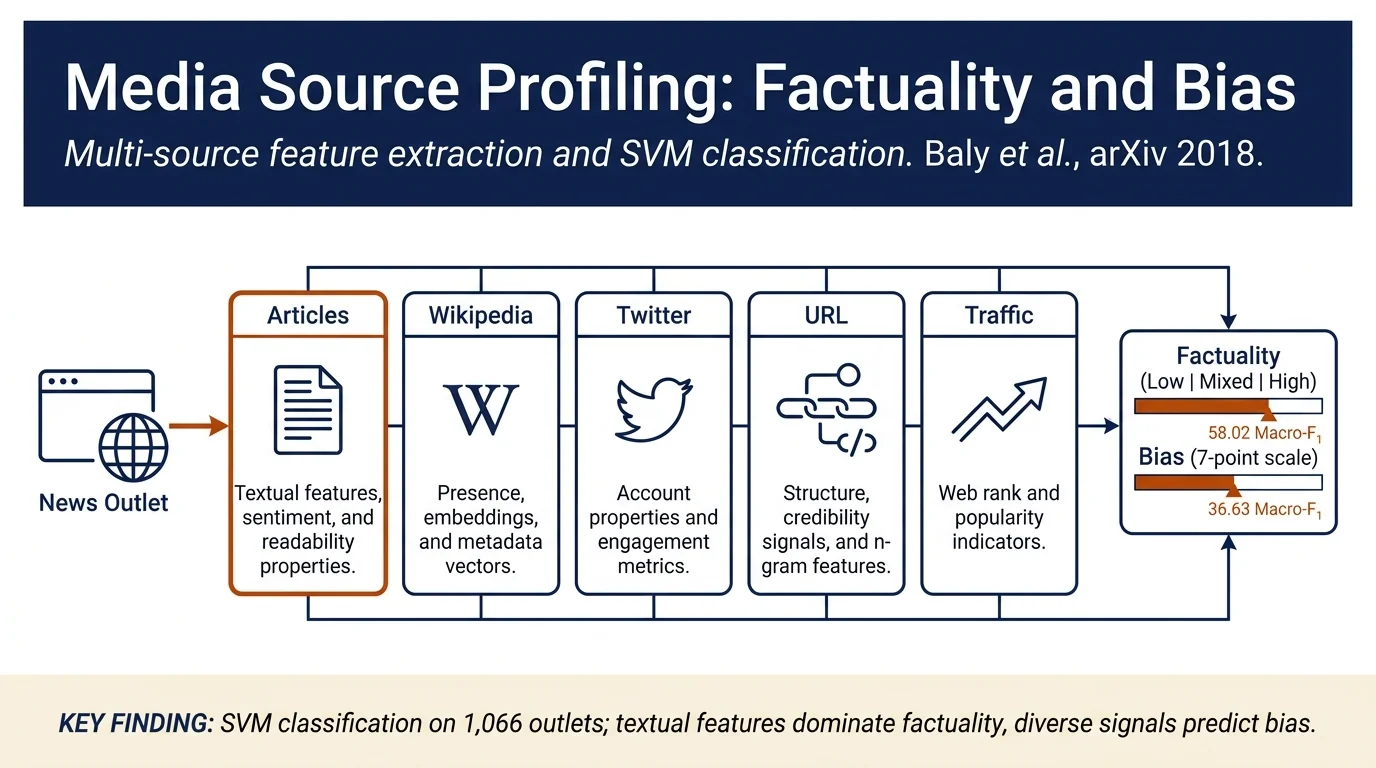
This paper frames predicting news media factuality and bias as classification tasks at the news outlet level rather than at the claim or article level. The authors extract 141 features from multiple sources (articles, Wikipedia, Twitter, URL structure, web traffic) and train SVM classifiers, creating a dataset of 1,066 websites manually annotated for both factuality (low/mixed/high) and bias (7-point political scale). Results show textual features from articles are most predictive for factuality, while Wikipedia and Twitter information help with bias detection; combining feature types yields the best performance.
Contributions¶
- Media-level profiling: Shift focus from individual claims to characterizing entire news outlets as a prior for fact-checking systems
- Large-scale dataset: Release 1,066 websites with annotations for both factuality and bias, 1–2 orders of magnitude larger than prior work
- Multi-source feature extraction: Design 141 features spanning article text, Wikipedia presence, Twitter profiles, URL structure, and traffic patterns
- Feature ablation: Demonstrate complementary value of different feature families; textual features dominate for factuality while bias benefits from diverse signals
Method¶
The authors model factuality (Low, Mixed, High) and bias (7-point scale from Extreme-Left to Extreme-Right) as separate classification tasks using Support Vector Machines.
Data collection: They curate labels from the Media Bias/Fact Check (MBFC) website, which provides manual annotations of news outlets' factuality and political slant. They filter to 1,066 websites where both labels are available or readily inferred (e.g., a satirical outlet is low-factuality).
Feature families:
-
Articles: 141 features including structural properties (POS tags, readability), sentiment scores, engagement metrics (share/like counts), topic-based lexicons, text complexity, bias-related word lexicons, and morality foundation theory features.
-
Wikipedia: Binary presence/absence of a Wikipedia page; seven vector representations using word embeddings from the article's content, infobox, summary, categories, and table of contents; counts of friends/statuses/favorites.
-
Twitter: Account properties (verification status, account age, location presence); tweet-level description vector (Google News embeddings).
-
URL: Character-based n-gram features (1–2-grams), orthographic properties (length, sections, special characters), credibility indicators (HTTPS usage, blog-hosting platforms, top-level domains like .gov).
-
Web Traffic: Alexa Rank as a single feature (less discriminative than expected).
Classification: SVM with RBF kernel, hyperparameters tuned via 5-fold cross-validation. Results reported as Macro-F₁, accuracy, and MAE (for ordinal regression variant).
Results¶
Headline numbers (5-fold cross-validation on full feature set):
- Factuality: 58.02 Macro-F₁ (64.35 accuracy, 0.43 MAE)
- Article features yield best individual performance (58.02 Macro-F₁)
- Wikipedia features contribute meaningfully (55.52 Macro-F₁ alone)
-
URL and Twitter features improve modestly when combined
-
Bias (7-point): 36.63 Macro-F₁ (41.74 accuracy, 1.15 MAE)
- Twitter features most useful (21.38 Macro-F₁), especially counts (friends, statuses, favorites)
- Wikipedia features also important (30.92 Macro-F₁)
- Article features less effective for bias detection than factuality
Ablation studies show feature types are complementary; removing any major family reduces performance, especially for bias. The best model for factuality excludes Web traffic features (negligible contribution), while bias benefits from all feature families.
Connections¶
- Baly et al. 2019 extends this approach to jointly model trustworthiness and political ideology as ordinal regression
- Nakov et al. 2021 surveys the landscape of media profiling for factuality and bias
- Related to Horne et al. 2018 on media bias detection and Shu et al. 2018 on fake news datasets
- Contrasts with claim-level fact-checking (Computational fact checking from knowledge networks) by operating at the media source level
Notes¶
This is a foundational paper in source-level profiling for fake news and media bias. Its main contribution is reframing the task from evaluating individual claims to profiling entire outlets—a practical distinction for deployment on new articles before manual verification. The breadth of features (textual, behavioral, structural) and systematic ablation provide useful baselines for later work.
The dataset is manually curated from MBFC, limiting it to English-language sources known to public fact-checking orgs; coverage of non-Western outlets or emerging misinformation sources may be sparse. The reliance on Wikipedia and Twitter presence also creates a bias toward outlets with high digital footprints. The paper does not deeply explore the correlation between factuality and bias, though later work by Baly et al. (2019) explicitly models this joint structure.