A Survey on Predicting the Factuality and the Bias of News Media¶
Authors: Preslav Nakov, Husrev Taha Sencar, Jisun An, Haewoon Kwak
Venue: arXiv preprint, 2021 — arXiv:2103.12506
TL;DR¶
Survey of media-level profiling methods for predicting news outlet factuality and political bias. Rather than checking individual claims or articles, the approach profiles entire news sources to enable early detection of unreliable content at publication time. Reviews textual, multimedia, audience, and infrastructure features for predicting source reliability, argues for joint modeling of factuality and bias, and outlines challenges in ordinal bias scales, multimodality, and temporal variation.
Contributions¶
- Media-level framing: Shift from claim/article-level fact-checking to source-level profiling, enabling rapid detection when unreliable outlets publish new content
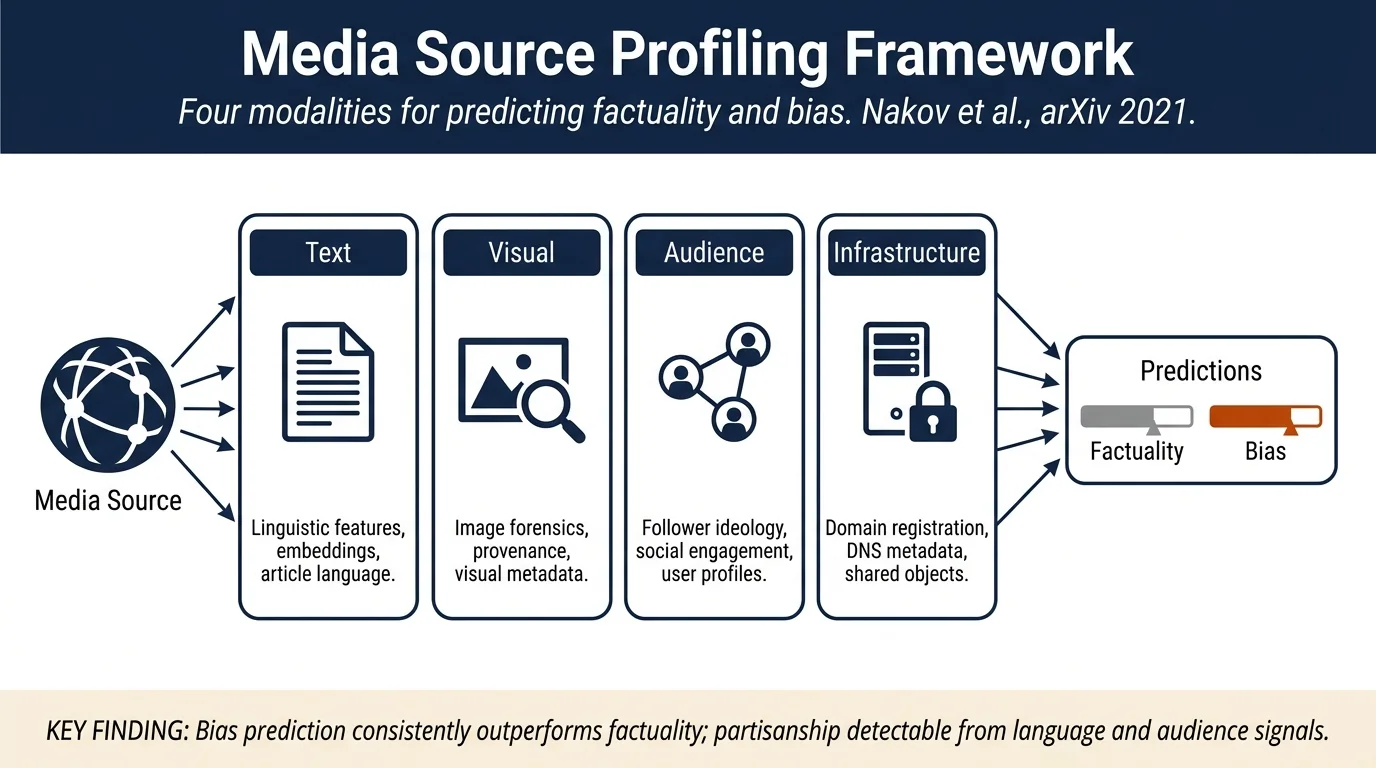
- Comprehensive taxonomy: Systematically categorizes prediction bases into four modalities: (i) textual content (linguistic features, embeddings), (ii) multimedia characteristics (image and video forensics), (iii) audience homophily (social media follower profiles), and (iv) infrastructure features (domain, hosting, certificate metadata)
- Joint modeling argument: Demonstrates connection between factuality and bias—hyperpartisan media are typically less factual—and advocates for unified models rather than separate pipelines
- State-of-the-art review: Surveys work from ~2015–2020 on media bias detection (gatekeeping, coverage, statement bias), framing analysis, news slant measurement, and factuality prediction
- Challenge identification: Documents obstacles including ordinal scale labeling, multimodal fusion, temporal drift, dataset scarcity, and annotation-automation gap
Method¶
The survey organizes media profiling into distinct information sources:
Section 2: Factuality Prediction. Covers source reliability estimation from articles published by a medium, gold-standard labels from platforms like Media Bias/Fact Check, and aggregation strategies (averaging article representations or posterior probabilities).
Section 3: Bias Prediction. Distinguishes multiple bias dimensions: gatekeeping bias (what stories are selected), coverage bias (amount of coverage), statement bias (tone), framing bias, and news slant (ideological positioning). Reviews methods using linguistic patterns, think-tank co-citations, frequency analysis of partisan phrases, and Twitter audience graphs.
Section 4: Prediction Bases.
- Textual Content (4.1): Linguistic features (141 features in NELA toolkit) covering style, complexity, bias, affect, morality, and events; embedding representations (BERT, Sentence-BERT); aggregation via averaging or posterior probabilities
- Multimedia (4.2): Visual characteristics of images at high/low-factuality outlets; deep learning representations; reverse image search provenance; metadata consistency
- Audience Homophily (4.3): Follower ideological profiles on Twitter, Facebook advertising targeting, YouTube engagement metrics, self-descriptions of followers
- Infrastructure Characteristics (4.4): Domain registration, DNS/certificate metadata, web design features, shared data objects (scripts, images, links) across websites
Results¶
The survey documents progress but highlights disparities:
- Bias easier than factuality: Ideological bias prediction consistently outperforms factuality assessment because partisanship is more stable and detectable from language/audience, while factuality requires ground truth verification from external sources
- Multimodal gains: When combined, audience and infrastructure features improve performance by bridging content-agnostic gaps, especially valuable for early-stage outlets with limited text
- Benchmark performance: Media Bias/Fact Check and AllSides data provide gold labels; factuality ratings often ordinal (high/mixed/low) or ternary
- Challenge: temporal variability: Ratings are not static; outlets improve/degrade with corrective action, requiring re-evaluation
Connections¶
- Complements Alam et al. (2021) on multimodal approaches, but extends to source-level rather than article-level analysis
- Related to Propagation-based fake news detection and Graph Neural Networks for network-based source profiling
- Overlaps with Fact-checking and corrections literature; source reliability informs claim-level verification The Fact Extraction and VERification (FEVER) Shared Task
- Extends political bias work by Groseclose & Milyo (2005) and Genzkow & Shapiro (2010) on slant measurement
- Related to user-level credibility assessment, adapted here to media organizations
Notes¶
Strengths: - First survey explicitly unifying factuality and bias at source level, clarifying why they should be modeled jointly - Systematic taxonomy of information sources beyond text (multimedia, audience, infrastructure) - Pragmatic discussion of why factuality is harder than bias (requires external ground truth) - Clear argument for infrastructure features as content-agnostic fallback for new/nascent outlets
Weaknesses: - Limited coverage of non-English or non-US political landscape (most literature assumes left-center-right spectrum); multiparty systems and alternative bias dimensions underexplored - Evaluation challenges undersold—measurement bias from sampling articles non-uniformly across topics; no discussion of how to handle temporal variation in ratings - Infrastructure features promising but sparsely studied; only Hounsel et al. (2020) comprehensively explored this dimension
Follow-ups: - Ordinal regression models for capturing bias intensity (far-left vs. center-left) with synthetic data generation for labeling - Cross-lingual and cross-political-system adaptation of factuality/bias models - Temporal dynamics: modeling when/how outlets shift in reliability; detecting transient vs. structural changes - End-to-end systems integrating article-level detection with source profiling for real-time misinformation feeds