Sampling the News Producers: A Large News and Feature Data Set for the Study of the Complex Media Landscape¶
Authors: Benjamin D. Horne, Sara Khedr, Sibel Adalı
Venue: ICWSM 2018 (Twelfth International AAAI Conference on Web and Social Media)
ArXiv: 1803.10124
TL;DR¶
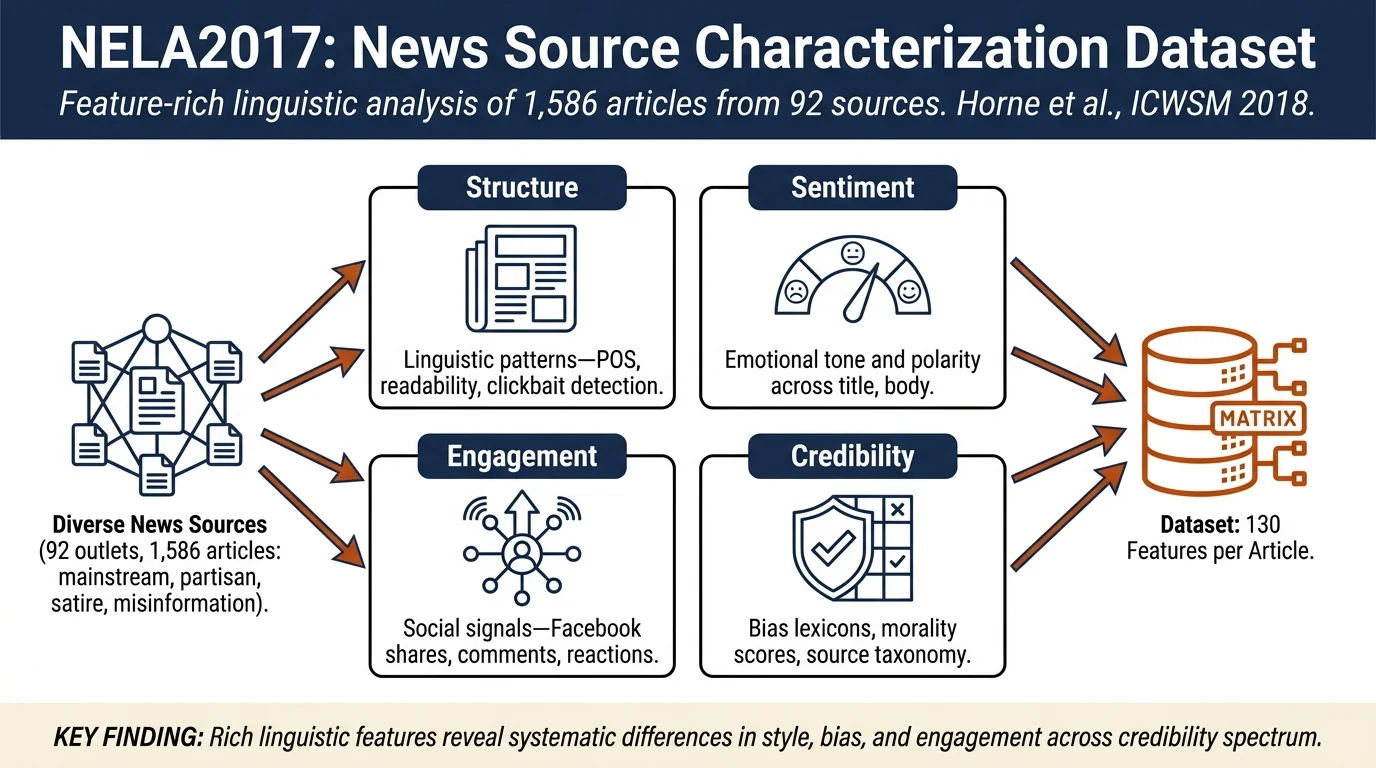
Introduces NELA2017, a dataset of 1,586 news articles from 92 diverse news sources over 7 months (April–October 2017), including mainstream outlets, hyper-partisan sources, satire, and deliberately false news sites. Computes 130 content-based linguistic and engagement features on each article, enabling large-scale comparative analysis of news source behavior and characterization.
Contributions¶
- Large-scale news source dataset — 1,586 articles across 92 distinct news sources, addressing gap in publicly available, diverse media landscape samples
- Comprehensive feature engineering — extraction of 130 content-based features spanning structure (POS, clickbait detection), sentiment, emotion, engagement (Facebook stats), bias, morality, and lexical characteristics
- Diverse source taxonomy — balanced representation across mainstream news, hyper-partisan political blogs, satire outlets, and known producers of deliberately false content
- Foundation for NELA series — establishes methodology and source lexicon extended by NELA-GT-2018, NELA-GT-2019, and beyond
Dataset Description¶
Scope: 1,586 articles from 92 news sources collected April 1 – October 31, 2017.
Source diversity:
Sources selected to span the full media landscape: - Established news outlets (CNN, New York Times, BBC, Reuters, etc.) — ~50% of sources - Hyper-partisan political sources (Breitbart, The Young Turks, etc.) — representing left and right political spectrum - Satire outlets (The Onion, Babylon Bee, etc.) - Known misinformation sources — sites documented as publishers of false, misleading, or conspiracy content
Article metadata collected: - Full article text and title - Source name and URL - Author information (when available) - Publication timestamp (UTC) - HTML markup (for raw feature extraction) - Facebook engagement statistics (shares, comments, reactions)
Temporal distribution: Near-complete daily coverage with some collection gaps; balanced sampling across time period to avoid bias toward trending topics.
Feature Engineering¶
130 features computed on title and article body text, organized into seven categories:
Structure Features (14 features)¶
- POS (Part-of-Speech) n-grams — normalized counts across word classes
- Clickbait detection via fine-tuned RNN classifier
- Linguistic diversity (Type-Token Ratio, Flesch-Kincaid readability)
Sentiment Features (3 features)¶
- Negative, positive, neutral sentiment scores via lexicon-based methods (TextBlob)
- Computed separately for title and body
Emotion Features (13 features)¶
- Categorical emotion detection (joy, sadness, anger, fear, surprise) via lexicons (EmoLex, LIWC)
- Strong/weak emotion indicators
- Distinct emotion word counts
Engagement Features (3 features)¶
- Facebook shares, comments, reactions (aggregate from Facebook API per article)
Complexity Features (7 features)¶
- Bias lexicons (LIWC, training data from Recasens et al.)
- Morality lexicons (Moral Foundation Theory)
- Lexical redundancy and diversity (character/word statistics)
All features computed on both title and body text separately, then combined, yielding ~260 total dimensions per article.
Descriptive Results¶
Source characteristics:
Ranking sources by average subjectivity (writing style), clickbait prevalence, sentiment, and readability reveals: - Hyper-partisan and satire sources score higher on subjectivity - Satire outlets show highest use of clickbait titles - Tabloid and lower-credibility sources lean more negative in sentiment - Established news outlets maintain higher readability (lower Flesch-Kincaid grade)
Feature correlations:
Positive correlations observed between: - Negativity and clickbait titles - Bias lexicon scores and hyper-partisan source classification - Engagement (Facebook shares) and subjective writing style
No strong single-feature discrimination between source types; classifiers require combination of features.
Use Cases¶
- News source characterization — quantify stylistic, emotional, and bias differences across sources
- Engagement prediction — predict Facebook engagement from linguistic features
- Fake news detection — features as input to ML classifiers distinguishing misinformation sources
- Media landscape comparison — systematic comparison of writing styles, biases, and narratives across left/right political spectrum
- Temporal analysis — track feature evolution as news producers respond to events and audience reactions
Design Decisions & Novelty¶
Feature-rich representation — Unlike prior fake news datasets focused on binary labels or social context, NELA2017 emphasizes content-level linguistic and structural features, enabling direct analysis of how misinformation differs from reliable reporting.
Source-level diversity — Carefully curated lexicon of 92 sources spanning political spectrum, credibility levels, and content types; avoids engagement bias (e.g., focusing only on viral content).
Temporal real-world data — Collection from actual publication timelines rather than curated lists or experiments, capturing authentic editorial decisions and audience interaction.
Connections¶
- Succeeded by NELA-GT-2018 — expands to 713K articles from 194 sources with multi-source ground truth labels
- Succeeded by NELA-GT-2022 — further expansion to 1.78M articles with refined collection methodology
- Related to FakeNewsNet — provides social propagation context on subset of fact-checked articles; NELA2017 focuses on source characterization at scale
- Related to LIAR dataset — statement-level fact-checking; NELA2017 operates at article/source level with linguistic features
- Influenced methodology in Potthast et al. 2017 on hyperpartisan news detection — stylometric features from similar linguistic tradition
Notes¶
Strengths: - Large feature set enables diverse downstream tasks and cross-source analysis - Transparent methodology for source selection and feature extraction - Foundation for subsequent releases (GT-2018, GT-2019, GT-2022) shows long-term utility - Balanced representation across credibility and partisan spectrum
Limitations: - Relatively small dataset (1,586 articles) compared to modern standards; later NELA versions address this - No per-article ground truth labels (veracity, fact-check status); relies on source-level classification - Feature engineering assumes English text; not multilingual - Facebook engagement data may reflect platform-specific virality patterns rather than content quality - Collection period (April–Oct 2017) captures specific historical moment; generalization to other time periods unclear
Methodological note: The shift from article-level fact-checking to source-level characterization is pragmatic — establishing reliable ground truth at scale is expensive. The linguistic feature approach trades explicit labels for rich content analysis that reveals how sources differ, rather than just whether they're correct.