Computational fact checking from knowledge networks¶
Authors: Giovanni Luca Ciampaglia, Prashant Shiralkar, Luis M. Rocha, Johan Bollen, Filippo Menczer, Alessandro Flammini
Venue: ArXiv, 2015 — arxiv:1501.03471
TL;DR¶
This paper proposes a computational approach to fact checking by framing it as a network problem on knowledge graphs. The method finds the shortest path between entities in Wikipedia's knowledge graph using semantic proximity metrics that account for entity generality. Evaluated on tens of thousands of claims, the approach consistently assigns higher truth values to true statements than false ones, demonstrating that knowledge graph topology contains meaningful signal for fact verification.
Contributions¶
- Novel computational fact-checking method based on semantic proximity in knowledge graphs, reducing fact checking to shortest-path computation
- Semantic proximity metric that incorporates entity generality via transitive closure on weighted graphs
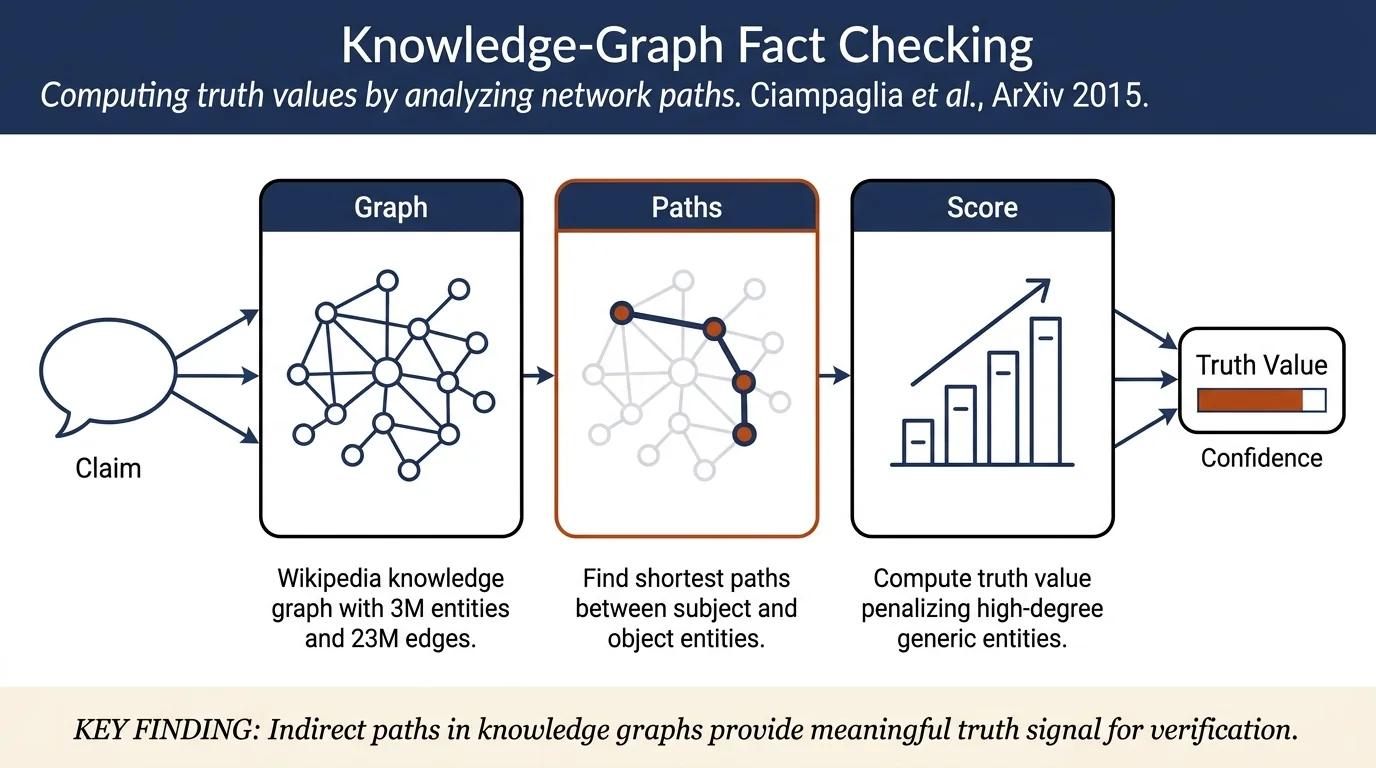
- Wikipedia Knowledge Graph (WKG) extraction with 3 million entity nodes and ~23 million edges from DBpedia
- Comprehensive evaluation on multiple claim datasets (simple factual statements, political ideology classification, annotated relation extraction corpus)
- Demonstration that indirect paths in the knowledge graph carry more information than direct edges for truth assessment
Method¶
The paper frames fact checking as a network analysis problem. Given a statement claim e = (s, p, o) (subject-predicate-object), the truth value is determined by analyzing paths in the Wikipedia Knowledge Graph.
The WKG is constructed from DBpedia, using only infobox data to ensure reliability. Each node represents an entity and edges represent predicates; the graph contains approximately 3 million entities and 23 million edges.
The core innovation is a semantic proximity metric that accounts for the generality (specificity) of entities along a path. The truth value is computed as:
where the path evaluation function is:
Here \(k(v)\) is the degree of entity \(v\) (how many statements mention it). Entities with high degree (generic entities like "United States" or "Male") contribute less to path strength, while paths through specific entities provide stronger support. This is derived from information-theoretic principles via epistemic closure.
The authors test alternative definitions including ultra-metric closure (widest bottleneck paths) and find that the metric closure (shortest paths) performs best empirically.
Results¶
Ideological classification task: Using truth values as features to classify US Congress members' ideology, the method achieves: - Senate: F-score 0.99 (Random Forest) using truth values, AUROC 1.00 - House: F-score 0.99 (Random Forest) using truth values, AUROC 1.00 - Performance matches the DW-NOMINATE baseline, which uses explicit roll-call voting data
Simple factual statements: Testing on four subject domains (Academy Awards, US presidential couples, US state capitals, world capitals) with artificially created true/false statement pairs, the method assigns higher truth values to true statements with probabilities of 95%, 98%, 61%, and 95% respectively.
Annotated relation extraction corpus (GREC): On the Google Relation Extraction Corpus (education degrees and institutional affiliations): - Truth values positively correlate with human ratings: Spearman ρ = 0.17 (p = 2×10⁻⁹) for degrees, ρ = 0.09 (p = 4×10⁻¹⁰) for institutions - Kendall's τ = 0.13 (p = 10×10⁻⁶) for degrees, τ = 0.07 (p = 1×10⁻²⁴) for institutions
Key finding on indirect paths: Most of the discrimination signal comes from indirect paths (> 2 nodes). When constraining the algorithm to use only direct edges (infobox statements), performance drops significantly (F-score from 0.99 to 0.54 on House ideological classification), demonstrating that network structure beyond direct facts carries truth information.
Connections¶
- Related to knowledge graph methods for information extraction and reasoning
- Extends network analysis approaches to the fact-checking domain; complementary to natural language and evidence-based approaches
- Influenced later work on graph neural networks for misinformation detection
- Applies concepts from semantic similarity and information theory to the credibility assessment problem
Notes¶
Strengths: - Clean problem formulation reducing fact checking to graph algorithms - Well-motivated semantic proximity metric grounded in information theory - Comprehensive evaluation across multiple heterogeneous datasets - Demonstrates that graph topology alone carries meaningful signal without NLP
Weaknesses: - Limited to simple predicates ("is-a", direct relations); negation and complex predicates not handled - Wikipedia infobox coverage is biased toward well-known entities; lower-coverage domains would be problematic - Correlation with human ratings on GREC is modest (ρ ≈ 0.1), suggesting the method captures only part of credibility - No evaluation on temporal or evolving statements; assumes static graph
Follow-ups: - Extending to richer, structured predicate semantics - Incorporating temporal information and graph dynamics - Combining with NLP methods for better handling of complex claims - Scaling to other knowledge bases beyond Wikipedia