Multi-Task Ordinal Regression for Jointly Predicting the Trustworthiness and the Leading Political Ideology of News Media¶
Authors: Ramy Baly, Georgi Karadzhov, Abdelrhman Saleh, James Glass, Preslav Nakov
Venue: arXiv preprint, 2019 — arXiv:1904.00542
TL;DR¶
Rather than predicting media bias and trustworthiness separately, this paper jointly models both as ordinal regression tasks using Copula Ordinal Regression. The intuition is that hyper-partisan outlets tend to be less trustworthy, while centrist outlets are more factual. Multi-task learning with auxiliary tasks at different granularities substantially reduces mean absolute error compared to single-task baselines.
Contributions¶
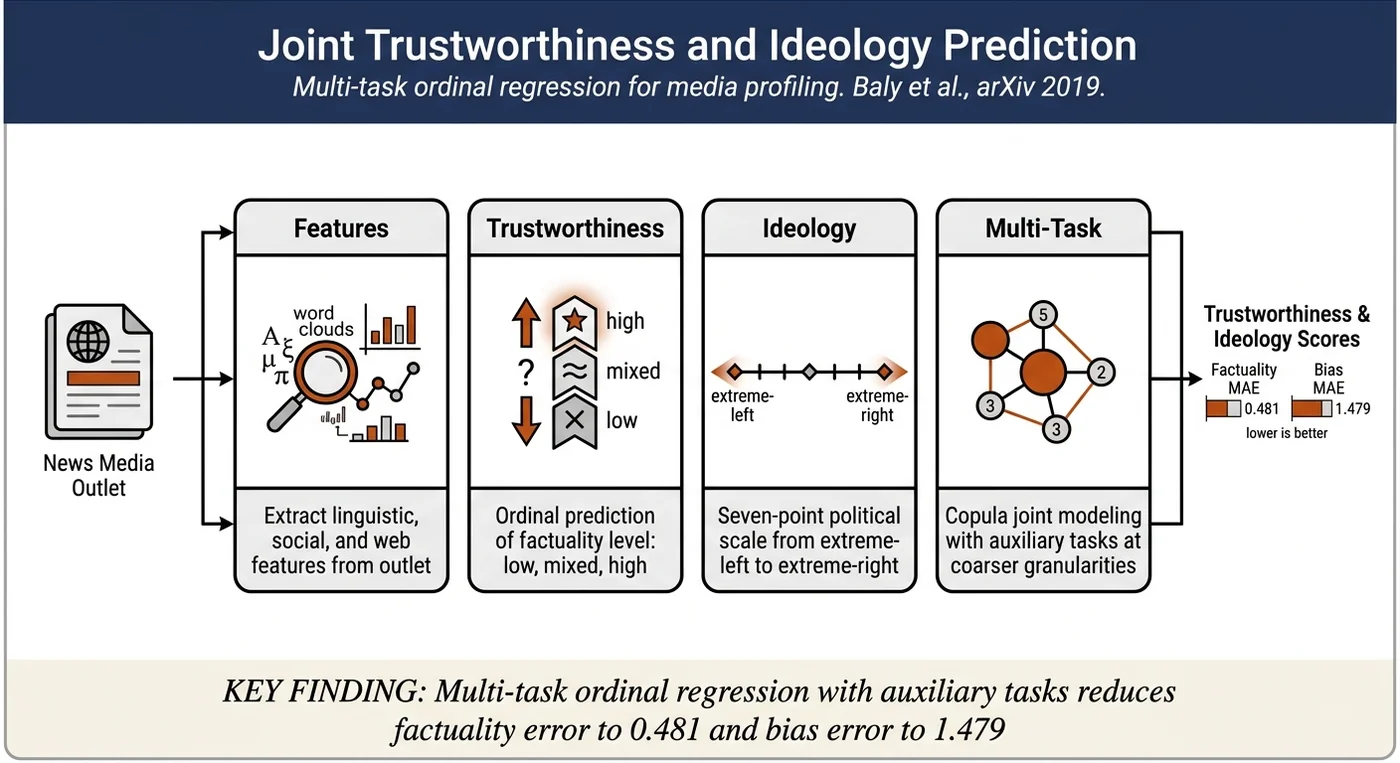
- Joint ordinal modeling: Addresses trustworthiness (3-point scale: low, mixed, high) and political ideology (7-point scale: extreme-left to extreme-right) simultaneously rather than independently, capturing the inherent correlation between extreme bias and low factuality.
- Copula Ordinal Regression framework: Adapts the Copula Ordinal Regression (COR) model from facial action unit prediction to jointly model the bivariate distribution of bias and factuality, capturing dependencies between the two tasks.
- Auxiliary task design: Introduces multiple auxiliary tasks derived from the bias labels at different granularities (5-point, 3-point, 2-point scales for extreme partisanship and centrality modeling), demonstrating that coarser-grained auxiliary tasks reduce gross errors in the primary task.
- Statistical validation: Shows that best multi-task models outperform single-task baselines with p ≤ 0.02, with factuality MAE improving to 0.481 and bias MAE to 1.479.
Method¶
Copula Ordinal Regression. The COR model uses copula functions and conditional random fields to approximate the joint probability distribution of two random variables (bias and factuality). For news media, bias and factuality are analogous to facial action unit intensities: each medium has a particular political ideology and a factuality level, both ordinal in nature.
Ordinal scales: - Trustworthiness: 3-point (low, mixed, high) - Political ideology: 7-point (extreme-left, left, center-left, center, center-right, right, extreme-right)
Auxiliary tasks (derived from bias labels): - Bias5-way: Collapse 7-point to 5-point scale - Bias3-way: Collapse to 3-point scale (left, center, right) - Bias-extreme: Binary task—extreme (far-left/far-right) vs. non-extreme - Bias-center: Binary task—center vs. non-center (ignoring polarity)
Features: POS tags, linguistic cues (sentiment, complexity, morality), document embeddings, Wikipedia features (if available), Twitter metadata (verified status, follower count), web-based features (URL structure, Alexa traffic rank).
Results¶
Factuality prediction: The combination bias-center + bias-extreme as auxiliary tasks achieves MAE = 0.481 (compared to single-task baseline MAE = 0.514). The insight: knowing whether a medium is centric or hyper-partisan is crucial for predicting factuality.
Bias prediction (7-point scale): Multi-task with 5-point and 3-point auxiliary tasks achieves MAE = 1.479 (single-task baseline MAE = 1.582). Coarser auxiliary tasks reduce gross directional errors (e.g., predicting extreme-left when the true label is extreme-right).
Statistical significance: Best multi-task models outperform single-task models with p ≤ 0.02 and majority-class baselines with p ≤ 0.001.
Dataset¶
MBFC (Media Bias/Fact Check): 949 news media (after excluding 117 satire/pseudo-science outlets) annotated by volunteers for: - Factuality: low (198), mixed (282), high (469) - Bias: extreme-left (23), left (151), center-left (200), center (139), center-right (105), right (164), extreme-right (167)
Connections¶
- Precursor to What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context which extends the approach with multi-modal features (text, social media audience, Wikipedia)
- Related to A Survey on Predicting the Factuality and the Bias of News Media survey, which reviews ordinal regression and joint factuality-bias modeling across the literature
- Uses MBFC (Media Bias/Fact Check) dataset also employed in related work
- Ordinal regression framework connects to fact-checking infrastructure and media assessment work
Notes¶
Strengths: - Novel application of Copula Ordinal Regression to media profiling; joint modeling is well-motivated and clearly beats single-task - Well-designed auxiliary task hierarchy exploiting natural granularities in the bias scale - Thorough ablation studies showing which auxiliary tasks matter most (bias-center + bias-extreme for factuality; 5-point + 3-point for bias) - Clear motivation from data: observed correlation between bias and factuality in Figure 1
Weaknesses: - Limited to news outlets with sufficient article/social media presence; sparse feature sets for nascent outlets - MBFC dataset is annotation-heavy and relies on volunteer annotators; inter-annotator agreement not discussed in detail - Features are relatively simple (embeddings, URL features, Alexa rank); no exploration of more fine-grained source credibility signals - Evaluation limited to English-language US/global media; generalization to non-Western political spectrums (multiparty systems, regional ideologies) unclear
Future directions: - Cross-lingual experiments and adaptation to non-binary political spectrums (e.g., eurosceptic vs. europhile, nationalist vs. globalist) - Temporal modeling of how media outlets' bias and factuality shift over time - Integration of audience homophily and infrastructure features for outlets with limited published content