Exposing the Deception: Uncovering More Forgery Clues for Deepfake Detection¶
Authors: Zhongjie Ba, Qingyu Liu, Zhenguang Liu, Shuang Wu, Feng Lin, Li Lu, Kui Ren
Venue: arXiv, 2024 — arXiv:2403.01786
TL;DR¶
This paper proposes a framework for deepfake detection that extracts both local and global forgery clues by decomposing facial features into disentangled local representations. Using mutual information theory to ensure comprehensive yet non-overlapping feature extraction, the method achieves state-of-the-art results on five benchmark datasets including FaceForensics++, Celeb-DF, and DFDC, with strong cross-dataset generalization.
Contributions¶
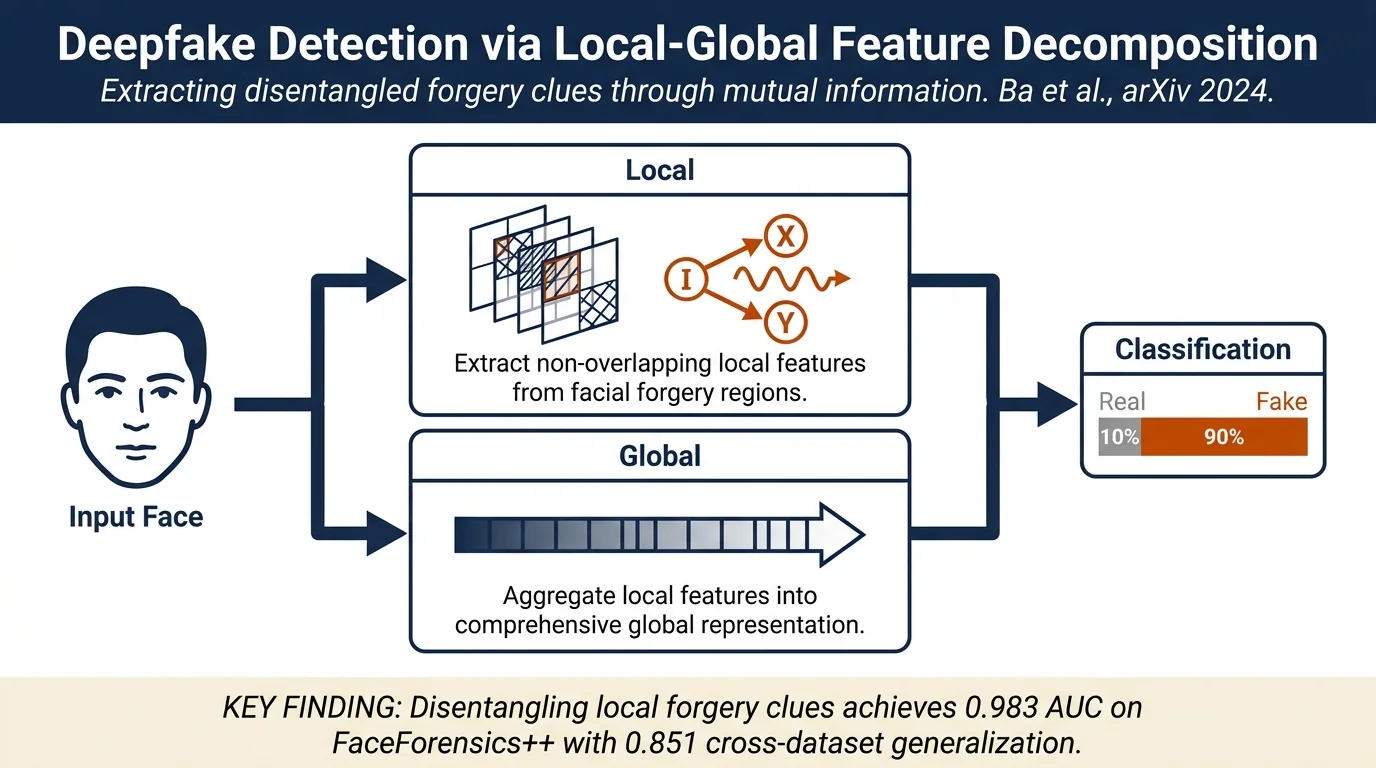
- A novel framework that adaptively extracts multiple non-overlapping local features corresponding to different forgery regions while also aggregating them into a sufficient global representation
- Mathematical formulation of Local Information Loss (L_LIL) and Global Information Loss (L_GIL) using mutual information theory to ensure local features are comprehensive, orthogonal, and task-relevant
- Theoretical analysis showing how information bottleneck principles ensure elimination of superfluous information while retaining discriminative cues
- State-of-the-art empirical performance on in-dataset (FaceForensics++: 0.983 AUC, Celeb-DF-V2: 0.999 AUC) and cross-dataset evaluations
Method¶
The framework consists of two main components: Local Disentanglement Module and Global Aggregation Module.
Local Disentanglement: The method extracts n ≥ 2 disentangled local feature representations z_i from an input image using the information bottleneck principle. The goal is to ensure each local feature z_i is: (1) comprehensive — contains sufficient task-relevant information about forgery, and (2) orthogonal — removes mutual information between different local features to avoid redundancy. This is formulated as:
where y is the label and Z is the joint local representation. The Local Information Loss enforces this constraint via KL-divergence:
Global Aggregation: Local features are concatenated into a global feature G guided by Global Information Loss (L_GIL) that eliminates superfluous information:
The overall objective combines cross-entropy classification loss with both information losses, allowing the model to extract broader forgery cues beyond single regions.
Results¶
In-dataset performance (frame-level AUC): - FaceForensics++ (C23): 0.983 - Celeb-DF-V2: 0.999 - DFDC: 0.939
Cross-dataset performance (frame-level AUC, trained on FaceForensics++): - Celeb-DF-V1: 0.818 - Celeb-DF-V2: 0.864 - DFDC-Preview: 0.851 - DFDC: 0.721
Video-level results (trained on FaceForensics++): - Celeb-DF-V2: 0.936 AUC - DFDC-Preview: 0.902 AUC - DFDC: 0.754 AUC
The method outperforms prior state-of-the-art approaches (e.g., Chugh et al. 2020, ICT) across all benchmarks. Ablation studies demonstrate that both L_LIL and L_GIL are critical; removing either loss results in substantial performance drops (0.966 → 0.826 AUC on FF++ when L_GIL is removed).
Connections¶
- Related to The Creation and Detection of Deepfakes: A Survey — comprehensive background on deepfake detection methods
- Extends techniques from FaceForensics++: Learning to Detect Manipulated Facial Images — uses FF++ dataset and builds on previous detection work
- Shares dataset evaluations with The DeepFake Detection Challenge (DFDC) Dataset — DFDC benchmark evaluation
- Influenced by DeepFakes: a New Threat to Face Recognition? Assessment and Detection — early deepfake detection threat modeling
- Related to Deepfakes and Disinformation: Exploring the Impact of Synthetic Political Video on Deception, Uncertainty, and Trust in News — broader disinformation implications of deepfakes
Notes¶
Strengths: The paper addresses a genuine limitation of prior work: existing methods often focus only on specific local regions or learn unimodal features, limiting generalization. The information-theoretic framework is principled and grounded in mutual information theory rather than heuristic. The empirical results are strong across both in-dataset and challenging cross-dataset scenarios. The ablation studies clearly demonstrate the contribution of each component.
Weaknesses: The method relies heavily on data-driven feature learning without explicit geometric or frequency-domain constraints (though visualization suggests the model discovers semantically meaningful regions like eyes, nose, mouth). The paper notes that performance on fully cross-dataset scenarios (trained on FF++, tested on DFDC) drops to 0.721 AUC, suggesting room for improvement in domain generalization. The approach requires face extraction as preprocessing, limiting applicability to non-frontal faces or heavily occluded deepfakes.
Follow-ups: Future work could combine local-global decomposition with frequency-domain analysis to capture both spatial and spectral forgery artifacts. Incorporating adversarial robustness testing and exploring semi-supervised learning for low-resource deepfake detection scenarios would strengthen practical applicability.