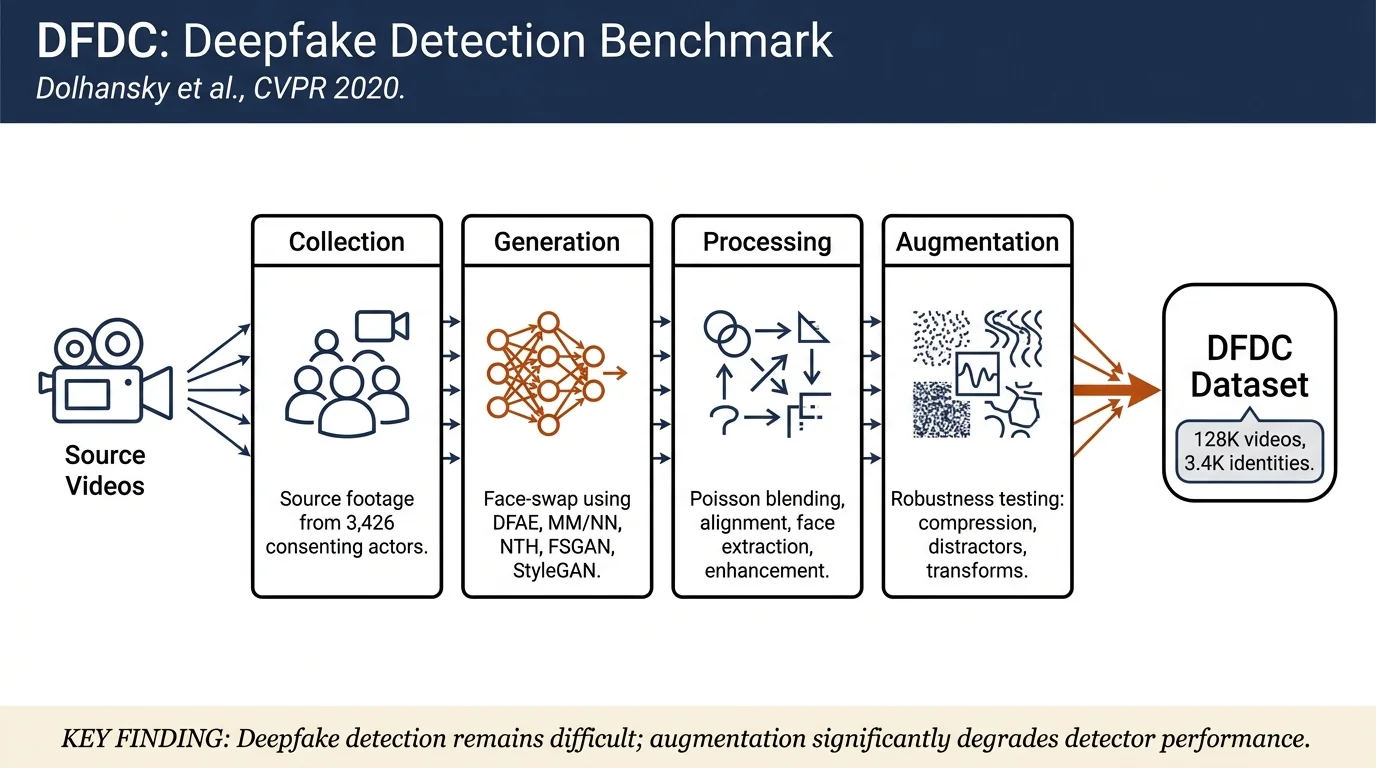
The DeepFake Detection Challenge (DFDC) Dataset¶
Authors: Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, Cristian Canton Ferrer
Affiliation: Facebook AI
Venue: CVPR 2020 (presented as arXiv preprint, October 2020)
Paper: https://arxiv.org/abs/2006.07397
TL;DR¶
This paper introduces the DFDC Dataset, the largest publicly available deepfake detection benchmark at the time with 128,154 videos from 3,426 consented actors and >100,000 face-swapped clips. The dataset addresses ethical and methodological limitations of prior deepfake benchmarks by requiring explicit participant consent, including diverse face-swap generation methods (DFAE, MM/NN, NTH, FSGAN, StyleGAN), and providing augmented test sets to measure robustness. A major Kaggle competition benchmarking detection methods shows that deepfake detection remains a difficult unsolved problem despite state-of-the-art approaches.
Contributions¶
- Large-scale ethically-constructed deepfake dataset: 128,154 videos (38.4 days of footage) from 3,426 paid, consenting actors, addressing privacy and consent issues in prior datasets.
- Methodological diversity: Videos created with multiple face-swap and generative methods (DFAE, MM/NN, NTH, FSGAN, StyleGAN) rather than a single method, increasing generalization potential.
- Augmentation robustness testing: ~79% of test videos include realistic post-processing (distractors, color shifts, compression) to evaluate detector robustness to distribution shift.
- Public benchmark competition: Organized the DeepFake Detection Challenge on Kaggle with thousands of submissions, providing real-time detection performance assessment.
- Detailed method descriptions: Full technical documentation of eight deepfake generation methods (DFAE architecture, MM/NN morphable-model approach, NTH meta-learning, FSGAN adversarial learning, StyleGAN refinement, plus audio manipulation and augmentation strategies).
Method¶
The paper describes the end-to-end pipeline for constructing the DFDC dataset:
Source data collection and preprocessing¶
The source videos consist of 3,426 subjects filmed in natural settings (outdoor and indoor) with high-resolution cameras. All subjects explicitly consented to have their likenesses manipulated for research purposes.
Face tracking and alignment was performed on all source videos using an internal face tracking and alignment algorithm. All face frames were extracted and resized to 256×256 pixels for deepfake generation.
Deepfake generation methods¶
Eight generation methods were applied to create face-swapped videos:
DFAE (Deep Face Auto-Encoder): Standard convolutional autoencoder with separate encoder/decoder pairs trained for each identity. The encoder converts a source identity face to a latent space vector, while the decoder reconstructs the target identity's face in the latent space. Pixel-shuffle operators maintain spatial coherence. Training uses MSE loss on in-distribution studio video.
MM/NN (Morphable Model / Nearest Neighbor): Facial landmarks extracted manually for source and target faces. Nearest-neighbor search identifies the best morphable face model match. Pixel morphing transforms source pixels to match target landmarks. Post-processing uses spherical harmonics to transfer illumination from target to source, creating realistic shading.
NTH (Neural Talking Head): Meta-parameter learning approach enabling few-shot training on limited data. A meta-learner network learns to generate talking-head videos where facial expressions and head movements from one video are transferred to another identity. Computationally efficient (single GPU training).
FSGAN (Face-Swapping GAN): Fully described in referenced work; uses two-stage pipeline with first GAN producing rough identity swap, second GAN refining appearance and details with adversarial loss.
StyleGAN: High-fidelity generative model producing synthetic face images from latent vectors. Applied selectively as a refinement step on deepfake outputs to increase perceptual quality.
Video post-processing: Deepfake faces are extracted as 256×256 resolution crops, then blended into full-resolution frames using Poisson blending. Sharpening filters enhance perceived quality with minimal computational cost. Face alignment is preserved using affine transforms estimated from facial landmarks.
Video augmentation¶
Augmentations were applied to test set videos to evaluate detector robustness:
- Distractors: Overlaid images (social media logos like YouTube watermarks), shapes, and text; ~30% of test videos contain distractors
- Augmenters: Geometric transforms (rotation, horizontal flipping), color adjustments (brightness, contrast), frame rate changes, grayscale conversion, audio removal, Gaussian noise, quality reduction via encoder settings
- Augmentation application: ~79% of final evaluation test set videos received one or more augmentations
Results¶
The paper focuses on two key results:
1. Detection is difficult. Multiple state-of-the-art deepfake detection methods, computer vision models, and custom approaches were benchmarked on the DFDC validation set via the Kaggle competition. The best submissions achieved only moderate accuracy, with significant room for improvement. The result demonstrates that deepfake detection remains an unsolved problem even with large labeled datasets.
2. Augmentation causes significant performance degradation. Models trained on clean (non-augmented) validation data show substantial accuracy drop when evaluated on augmented test videos. This highlights the critical challenge of building detectors that generalize to the distribution shift introduced by realistic post-processing and compression.
Key observations from the paper:
- Consent and ethical design: All 3,426 subjects were paid for participation and explicitly agreed to have their likenesses manipulated for research purposes, addressing major ethical concerns in prior datasets.
- Scale advantage: DFDC has nearly 100× more videos (128K vs. 1K) and more identities (3.4K vs. hundreds) than prior datasets like Celeb-DF, enabling training of more robust detection models.
- Generation method diversity: Inclusion of multiple face-swap methods (DFAE, MM/NN, NTH, FSGAN, StyleGAN) prevents overfitting to artifacts specific to a single generation technique.
- Generalization remains hard: Despite diversity and scale, the Kaggle competition shows significant performance gaps when detectors encounter held-out test splits and augmented videos, suggesting fundamental challenges in deepfake detection.
Connections¶
- Deepfakes (topic) — The deepfakes topic page discusses detection methods and the arms race between generation and detection; DFDC is the largest benchmark enabling this research.
- Synthetic media (topic) — Places deepfakes within broader context of AI-generated content.
- Vaccari & Chadwick (2020) — Empirical study of deepfake impact on trust and uncertainty; DFDC enables research into detecting the videos in that work.
- Fagni et al. (2020) — TweepFake — Parallel detection benchmark for machine-generated text; similar challenge structure and goal of advancing the field through public datasets and competitions.
- Multimodal detection (topic) — DFDC combines visual, audio, and temporal signals for detection.
Notes¶
Strengths: - Largest deepfake dataset at publication time (128K videos, 3.4K identities) - Explicit ethical design with full participant consent - Diversity of generation methods prevents single-method overfitting - Augmentation-robustness testing is realistic and necessary - Public Kaggle competition enables real-time benchmarking and community participation - Detailed method descriptions allow reproducibility
Limitations: - All source videos filmed in controlled studio settings; lacks diversity of real-world video production (broadcast news, surveillance, mobile video) - Augmentation represents only subset of real-world post-processing scenarios - Limited to face-swap and GAN methods available in 2020; newer diffusion-based generation methods not represented - Test set size (10K videos) is modest by modern dataset standards - No analysis of cross-dataset generalization (e.g., does a detector trained on DFDC generalize to FaceForensics++ or Celeb-DF?)
Research impact: The DFDC Dataset has become a standard benchmark for deepfake detection research, enabling thousands of researchers to develop and compare detection algorithms. The associated Kaggle competition accelerated progress in the field by providing real-time feedback on detection performance. However, the persistent difficulty of detection (even with massive labeled datasets) highlights that deepfake detection may require multimodal approaches, temporal analysis, or social context rather than image-level analysis alone.