FaceForensics++: Learning to Detect Manipulated Facial Images¶
Authors: Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, Matthias Niessner
Affiliations: Technical University of Munich, University Federico II of Naples, University of Erlangen-Nuremberg
Venue: arXiv preprint, August 2019
Paper: https://arxiv.org/abs/1901.08971
TL;DR¶
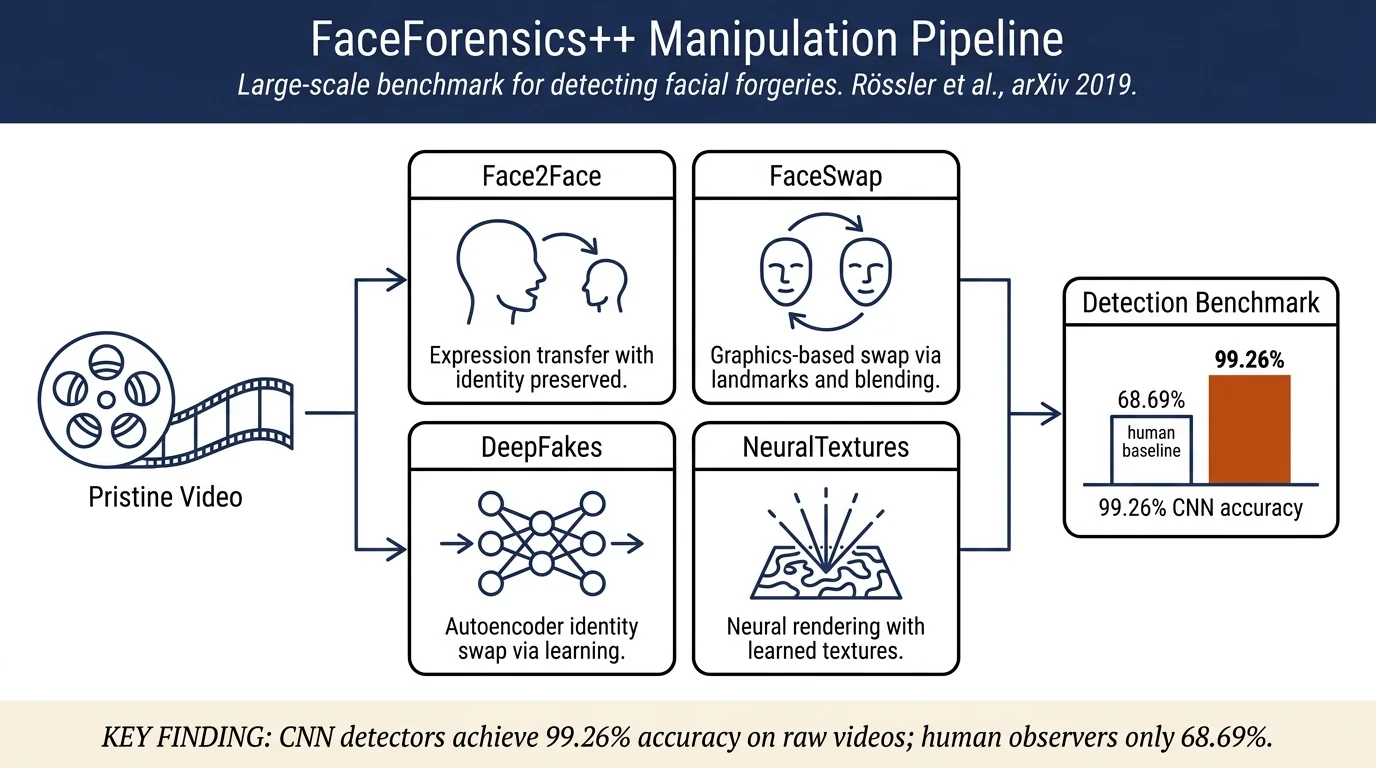
FaceForensics++ introduces a large-scale benchmark (1.8+ million manipulated images from 1,000+ videos) for detecting facial manipulations created with four state-of-the-art methods: Face2Face, FaceSwap, DeepFakes, and NeuralTextures. The paper comprehensively evaluates detection methods from stegananalysis to deep learning, demonstrating that learned CNN-based approaches significantly outperform human observers, but robustness to compression remains a major challenge.
Contributions¶
- Large-scale facial forgery dataset: FaceForensics++ extends the original FaceForensics dataset to 1.8+ million images from 1,000+ pristine YouTube videos manipulated via four automated methods.
- Automated benchmark with compression robustness: Evaluation methodology addresses realistic scenarios by testing detector performance on raw and compressed videos (simulating H.264 compression at quality levels 23 and 40), with performance degradation quantified.
- Comprehensive detection evaluation: Systematic evaluation of five detection approaches: stegananalysis features (Steganalysis with SVM), hand-crafted forensic features (Cozzolino et al., Bayar & Stamm), and learned CNN features (MesoNet, XceptionNet) on all four manipulation methods.
- Human baseline and user study: User study (N=204 participants) establishing human detection accuracy (68.7% on raw, 58.7% on compressed videos), showing XceptionNet significantly outperforms humans.
- Domain-specific detection pipeline: Face tracking and extraction improve detector performance by removing irrelevant image content, demonstrating value of domain knowledge.
Method¶
The paper constructs FaceForensics++ through a four-stage pipeline:
1. Source Video Collection and Preparation¶
Source videos were collected from YouTube to ensure real-world video quality and diversity. Videos were manually screened for: - High face quality and stable framing (faces nearly front-facing without significant occlusions) - Adequate length (minimum 250 frames) - Diverse identities, lighting, and backgrounds
Final collection: 1,000 pristine source videos with 509,914 images selected for manipulation.
2. Facial Manipulation Methods¶
Four automated manipulation methods were applied to each video:
Face2Face: Facial reenactment system transferring expressions from a source video to a target video while preserving target identity. Uses 3D face reconstruction, expression tracking, and Blendshape-based manipulation with 76 parameters per frame. Maintains target lighting and pose.
FaceSwap: Graphics-based face-swap approach using sparse facial landmarks, 3D template models, and Blendshape fitting. Projects deformed shape and textured landmarks, then blends result with Poisson image editing. No learning required; computationally lightweight.
DeepFakes: Learning-based autoencoder approach with shared encoder (source and target mapped to latent space) and separate decoders reconstructing each identity. Trained via Poisson image editing blending onto target frames.
NeuralTextures: Neural rendering approach learning per-pixel deformation fields and texture codes. Uses coarse 3D face geometry from Face2Face tracking with photometric reconstruction loss combined with adversarial loss.
3. Video Quality Simulation¶
To evaluate robustness to real-world compression: - Raw videos preserved in original quality - Compressed videos created with H.264 codec at quality level 23 (lower quality, higher compression) - Compressed videos created with H.264 codec at quality level 40 (higher quality, lower compression)
4. Detection Approaches¶
Stegananalysis: Hand-crafted co-occurrence features on high-pass filtered images (4-pixel patterns, horizontal and vertical directions), trained via linear SVM.
Hand-crafted forensic features: Evaluated methods from Cozzolino et al. (residual noise) and Bayar & Stamm (constrained convolutional layers).
Learned CNN features: Five architectures evaluated: - Cozzolino et al. (CNN on previous section) - Bayar & Stamm (CNN variant) - Rahmouni et al. (global pooling statistics) - MesoNet (shallow CNN designed for face tampering) - XceptionNet (pre-trained on ImageNet, fine-tuned)
Domain-specific preprocessing uses face tracking to extract face region (enlarged 1.3×) centered on tracked face, improving performance by removing background.
Results¶
Detection Accuracy Summary (Table 1, Full Image XceptionNet): - Raw videos: 99.26% accuracy on compression-free videos - Compressed quality 23: 98.36% accuracy - Compressed quality 40: 99.26% accuracy
Method-specific performance (Table 4, XceptionNet on raw videos): - DeepFakes: 99.59% (most detectable) - Face2Face: 99.61% (most detectable) - FaceSwap: 99.36% - NeuralTextures: 99.36%
Performance degradation under compression (Table 2, low-quality videos): - Stegananalysis: 51.80% accuracy (baseline 73.64%) - Cozzolino et al.: 55.20% accuracy (baseline 85.45%) - XceptionNet: 81.00% accuracy (baseline 99.26%)
Human baseline (User Study, N=204): - Raw videos: 68.69% accuracy - High quality: 66.57% accuracy - Low quality: 58.73% accuracy - Humans particularly struggle with Face2Face and NeuralTextures (subtle artifacts)
Training corpus size analysis (Table 6, Figure 8): - XceptionNet trained on 10 videos: 64.55% accuracy - Trained on 50 videos: 75.39% accuracy - Trained on 100 videos: 83.68% accuracy - Trained on 300 videos: 88.88% accuracy - Trained on all videos: 96.65% accuracy
Connections¶
- Deepfakes (topic) — FaceForensics++ is the largest benchmark for deepfake detection, enabling systematic comparison of detection methods and studying generalization across manipulation techniques.
- Synthetic media (topic) — Places facial manipulation within broader context of AI-generated visual content.
- Multimodal fake news detection (topic) — While FaceForensics++ focuses on visual detection, related work combines audio and temporal signals for robustness.
- Dolhansky et al. (2020) — The DeepFake Detection Challenge Dataset — Parallel large-scale deepfake detection benchmark with emphasis on ethical consent and augmentation robustness; both are now standard resources in the field.
- Vaccari & Chadwick (2020) — Studies epistemic impact of deepfakes on trust and uncertainty; FaceForensics++ enables research into detecting such videos at scale.
- Facial manipulation detection (topic) — FaceForensics++ is foundational benchmark for face-swap, reenactment, and synthetic media detection literature.
Notes¶
Strengths: - Largest facial forgery dataset at publication (1.8M+ images from 1K+ videos) - Diverse manipulation methods (four state-of-the-art approaches) prevents overfitting to single-method artifacts - Systematic evaluation of compression robustness, reflecting real-world deployment scenarios - Human baseline quantifies performance gap between automated detectors and human observers - Domain-specific face tracking preprocessing improves performance, demonstrating value of combining forensics knowledge with learning - Extensive ablation studies on training corpus size, compression levels, and method combinations - Publicly available dataset and models have become standard benchmarks in the field
Limitations: - Source videos from YouTube lack diversity of real-world scenarios (surveillance, broadcast, livestream) - Four manipulation methods represent landscape as of 2019; newer diffusion-based and GAN-based methods not included - Compression evaluation limited to H.264; other codecs (VP9, AV1) not tested - No cross-dataset generalization analysis (detector trained on FaceForensics++ tested on DFDC or vice versa) - Detection methods are image-level; temporal consistency and multimodal approaches not explored - Closed-set evaluation (all videos manipulated via one of four known methods); open-set generalization to unknown methods unclear
Impact: FaceForensics++ became the canonical benchmark for facial manipulation detection research, cited in hundreds of follow-up papers. The dataset's public availability and scale enabled rapid progress in detection methods and exposed fundamental generalization challenges (compression robustness, cross-method transfer) that remain open problems in the field.