DeepFakes: a New Threat to Face Recognition? Assessment and Detection¶
Authors: Pavel Korshunov, Sébastien Marcel Venue: arXiv, 2018 — arXiv:1812.08685
TL;DR¶
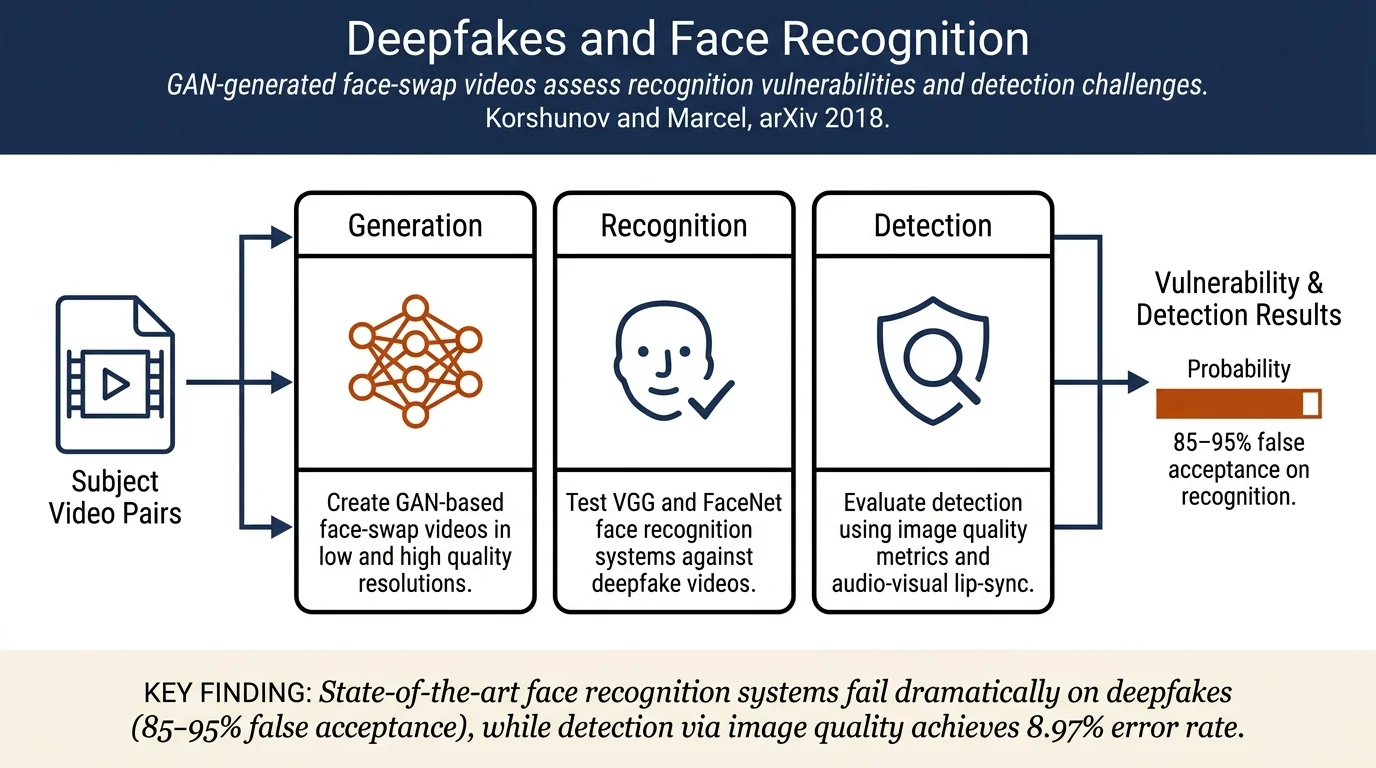
GAN-based face-swapping (Deepfakes) pose a significant threat to face recognition systems: VGG and FaceNet achieve false acceptance rates of 85.62% and 95.00% on high-quality Deepfakes. The authors release the first public Deepfake video database (620 videos from 16 subject pairs) and show that image quality metrics with SVM achieve 8.97% equal error rate for detection, while audio-visual lip-sync approaches fail entirely.
Contributions¶
- First publicly available dataset of GAN-generated Deepfake videos (620 videos, low and high quality versions) from VidTIMIT database
- Vulnerability analysis demonstrating that state-of-the-art face recognition systems (VGG, FaceNet) fail dramatically on Deepfakes
- Evaluation of multiple Deepfake detection methods including lip-sync inconsistency and image quality metrics
- Open-source implementation and benchmark scores for reproducibility
Method¶
The authors use a GAN-based face-swapping algorithm to generate Deepfakes from video pairs where subjects have similar visual features. They create two quality versions:
- Low Quality (LQ): 64×64 facial regions, 200 training frames extracted at 4 fps, 100k training iterations (~4 hours)
- High Quality (HQ): 128×128 facial regions, 400 training frames at 8 fps, 200k iterations (~12 hours)
For each quality version, different blending techniques are used: LQ uses face segmentation masks, while HQ uses facial landmark alignment plus histogram normalization for lighting adjustment. All 16 subject pairs generate bidirectional swaps, yielding 320 videos per quality level.
For face recognition evaluation, the authors test VGG and FaceNet on both genuine and Deepfake videos, measuring false acceptance rates (FAR) at the equal error rate (EER) threshold from the licit scenario. For detection, they evaluate:
- Audio-visual approach: LSTM trained on MFCCs (audio) and mouth landmark distances (visual) to detect lip-sync inconsistency
- Image-based approaches: PCA+LDA on raw pixels, IQM+PCA+LDA, and IQM+SVM (129 image quality metrics)
Results¶
Face Recognition Vulnerability: VGG achieves EER of 0.03% on genuine videos but FAR of 85.62% on high-quality Deepfakes. FaceNet achieves 0.00% EER on genuine videos but FAR of 95.00% on HQ Deepfakes—demonstrating that more sophisticated recognition systems are paradoxically more vulnerable.
Detection Performance: The lip-sync approach completely fails (41.8% EER on LQ) because GANs successfully generate facial expressions synchronized with speech. Image quality metrics with SVM perform best: 3.33% EER on low-quality Deepfakes but 8.97% EER on high-quality versions, showing the challenge scales with visual fidelity.
Dataset¶
The paper introduces the VidTIMIT Deepfake dataset, the first publicly available set of 620 GAN-generated face-swap videos from 16 manually-selected similar-looking pairs. Both low-quality (64×64) and high-quality (128×128) versions are provided, enabling systematic evaluation of how visual fidelity affects both face recognition vulnerability and detection difficulty.
Connections¶
- Related to Deepfakes and Disinformation: Exploring the Impact of Synthetic Political Video on Deception, Uncertainty, and Trust in News on the misinformation implications of Deepfakes
- Cited by work on Synthetic Media Detection and video forensics
- Complements EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection on multimodal fake content detection
Notes¶
This paper is foundational for Deepfake detection: it established the first public benchmark, demonstrated concrete vulnerability of production face recognition systems, and framed detection as a critical research challenge. The finding that lip-sync fails is important—synthetic videos that preserve audio-visual consistency are harder to detect. The 8.97% error rate on HQ Deepfakes, while reasonable, hints at an arms race: as generation quality improves, detection becomes harder. The paper's emphasis on dataset quality (low vs. high visual quality) presaged later findings that realistic synthesis makes detection substantially more difficult.