Atlas: Few-shot Learning with Retrieval Augmented Language Models¶
Authors: Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, Edouard Grave
Venue: arXiv, August 2022 — arXiv:2208.03299
TL;DR¶
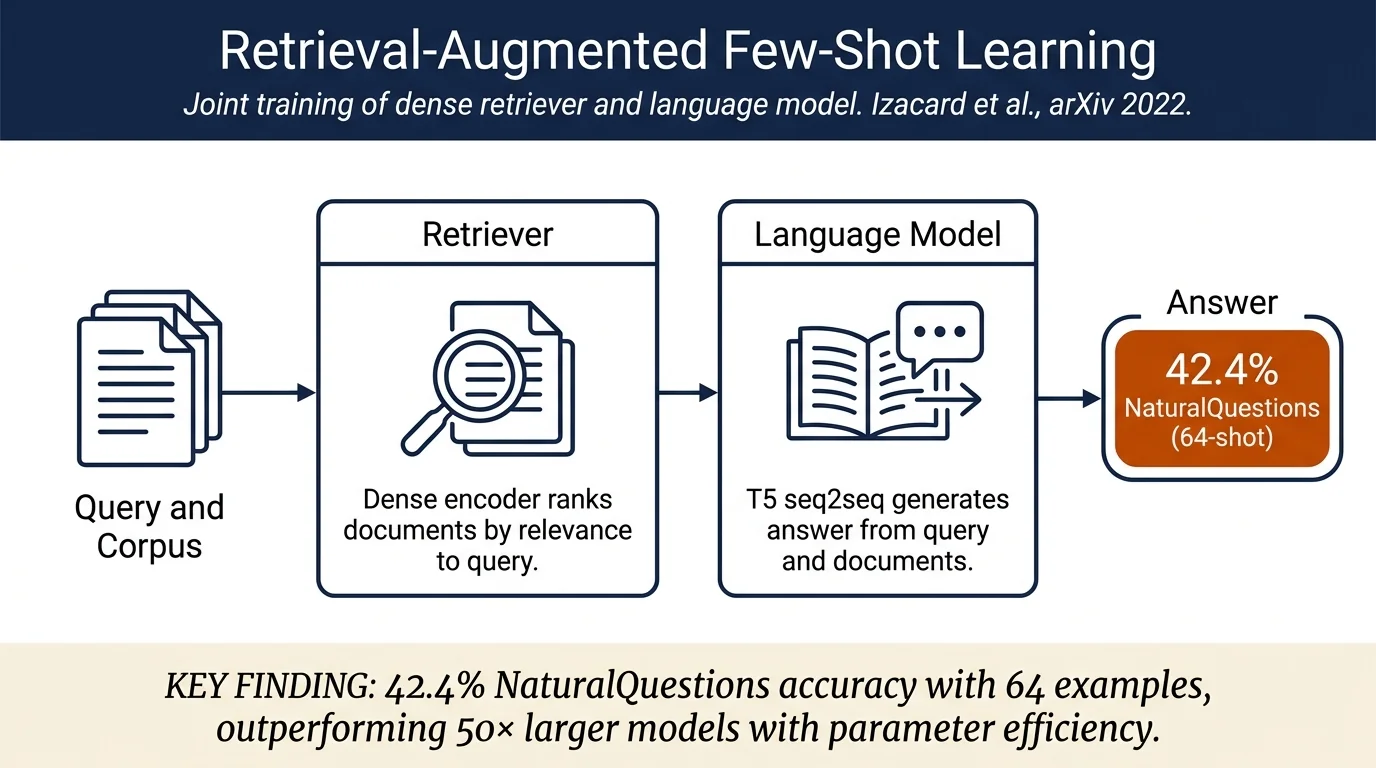
ATLAS is a retrieval-augmented language model that achieves strong few-shot performance on knowledge-intensive tasks by jointly training a dense retriever with a sequence-to-sequence language model. Unlike standard language models that must memorize knowledge, ATLAS retrieves relevant documents at both pre-training and fine-tuning stages, achieving 42.4% accuracy on NaturalQuestions with only 64 training examples—outperforming much larger models—and 64.3% on FEVER fact-checking, demonstrating practical advantages for resource-constrained deployment.
Contributions¶
- A comprehensive study on designing and training retrieval-augmented language models, addressing the tradeoff between memorization and retrieval for few-shot learning.
- ATLAS: a pre-trained retrieval-augmented model with three parameter scales (770M, 3B, 11B) that exhibits few-shot learning capabilities rivaling much larger dense-only language models.
- Four joint training objectives (Attention Distillation, EMDR², Perplexity Distillation, LOOP) to train the retriever using signals from the language model without requiring explicit document annotations.
- Extensive ablations on pretext tasks, retriever fine-tuning strategies, and index content, identifying masked language modeling and re-ranking as most effective.
- Evaluation on knowledge-intensive benchmarks (KILT, MMLU, NaturalQuestions, TriviaQA, FEVER, KILT) showing state-of-the-art few-shot results and competitive full-dataset performance.
- Analysis of interpretability (retrieved document inspection), temporal updateability (index swapping without retraining), and memory efficiency (index compression from 49GB to 4GB with minimal accuracy loss).
Method¶
Architecture. ATLAS uses two jointly trained components: (1) a dense retriever based on Contriever that encodes queries and documents independently and scores them via cosine similarity, and (2) a sequence-to-sequence language model based on T5 that processes the query concatenated with retrieved documents. The retriever's flexibility allows both pre-training and fine-tuning without document annotations—the language model provides training signal through distilled attention weights or by conditioning on retrieved documents.
Training objectives. The paper proposes four loss functions: - Attention Distillation (ADist): Distills cross-attention scores from the language model's decoder to train the retriever to rank documents that matter for the output. - EMDR² (End-to-end Multi-Document Reader): Trains the retriever to rank documents that maximize the language model's likelihood of the correct output at the token level. - Perplexity Distillation (PDist): Trains the retriever to predict how much each document would improve the language model's perplexity on the output. - Leave-one-out Perplexity (LOOP): Trains the retriever by removing one retrieved document and measuring the impact on language model perplexity.
Pretext tasks for pre-training. Three unsupervised pre-training tasks jointly pre-train the retriever and language model without labeled data: (1) prefix language modeling (mask second half of text, retrieve documents via first half to predict output), (2) masked language modeling (mask spans, retrieve documents via masked query to predict masks), and (3) title-to-section generation (retrieve Wikipedia articles by title to generate sections).
Efficient fine-tuning. When the index is large and frequently updated, recomputing all document embeddings is expensive. The paper explores: (1) full index update (recompute all embeddings), (2) re-ranking (retrieve many documents with stale embeddings, re-rank with updated embeddings), and (3) query-side fine-tuning (only update query encoder, freeze document embeddings). Re-ranking provides the best speed-accuracy tradeoff in few-shot settings, yielding ~10% overhead vs. standard language model fine-tuning.
Results¶
Few-shot knowledge-intensive language tasks (KILT). ATLAS-11B achieves competitive zero-shot and few-shot results across 11 knowledge-intensive tasks: 42.4% accuracy on NaturalQuestions (64-shot, outperforming PaLM 540B by 3 points with 50× fewer parameters), 56.2% on FEVER fact-checking (15-shot), 64.3% (65-shot), and 78.0% (full-dataset, state-of-the-art). On KILT hidden test sets, ATLAS-11B full-dataset training achieves 90.6% on AIDA (entity linking) and strong results on hotpotQA and other tasks.
Multi-task language understanding (MMLU). ATLAS-11B reaches 56.3% accuracy on the 57-domain MMLU 5-shot setting, comparable to closed-book T5-XXL (56.4%) and within 13.9 points of GPT-3, while being substantially more parameter-efficient and interpretable.
Open-domain question answering. ATLAS-11B achieves 42.4% on NaturalQuestions 64-shot (vs. 29.9% for GPT-3, 28.2% for Gopher, 35.5% for Chinchilla), outperforming Chinchilla despite using 18× fewer parameters. On TriviaQA, ATLAS achieves 74.5% exact match in 64-shot and 89.4% full-dataset, competitive with retrieval-augmented baselines.
Fact-checking (FEVER). ATLAS reaches 56.2% accuracy on the 15-shot FEVER benchmark, 64.3% on the 65-shot setting, and 80.1% with full-dataset fine-tuning—state-of-the-art or near-state-of-the-art across shot settings, demonstrating retrieval-augmented models can effectively verify claims with minimal labeled data.
Connections¶
- A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT — foundational context on generative AI capabilities that ATLAS exemplifies.
- On the Opportunities and Risks of Foundation Models — discusses foundation models and their societal risks including misinformation; retrieval-augmented approaches like ATLAS offer improved factuality for detection systems.
- Causal Machine Learning: A Survey and Open Problems — causal reasoning and knowledge retrieval are complementary for robust claim verification.
- The Fact Extraction and VERification (FEVER) Shared Task — FEVER benchmark for fact verification; ATLAS demonstrates state-of-the-art few-shot performance on this task.
- Attention Is All You Need — ATLAS builds on Transformer architecture for both retriever and language model components.
Notes¶
Strengths. The paper makes a compelling case that retrieval-augmented models are more parameter-efficient for knowledge-intensive tasks than dense-only language models—a critical insight for fact-checking and misinformation detection systems operating under resource constraints. The four proposed training objectives provide flexible ways to leverage language model signals to train the retriever without expensive human document annotations. Extensive ablations clarify which design choices matter. The analysis of index updateability without retraining is particularly valuable for deploying systems in dynamic information environments (e.g., detecting claims about recent events).
Relevance to misinformation detection. ATLAS addresses a core challenge in fact-checking: rapidly adapting to new claims and evidence with limited labeled data. The fact-checking results on FEVER (80.1% full-dataset) and strong few-shot performance (56.2% with 15 examples) directly demonstrate applicability. Retrieval-augmentation provides transparency by exposing which documents informed a decision—important for explainability in high-stakes fact-checking. Index updateability enables systems to incorporate newly-fact-checked claims without full retraining.
Limitations. The paper focuses on English and existing Wikipedia-scale knowledge. Cross-lingual and real-time fact-checking (where retrieved documents may not yet exist for breaking claims) remain open questions. Retrieval quality depends on index coverage; claims contradicting but not mentioned in Wikipedia may be harder to verify. The work is pre-training-heavy; the practical cost of pre-training on unlabeled text is not discussed relative to alternative approaches (e.g., prompting very large models).