The Fact Extraction and VERification (FEVER) Shared Task¶
Authors: James Thorne, Andreas Vlachos, Oana Cocarascu, Christos Christodoulopoulos, Arpit Mittal
Venue: ACL 2018 Shared Task Workshop
arXiv: 1811.10971
TL;DR¶
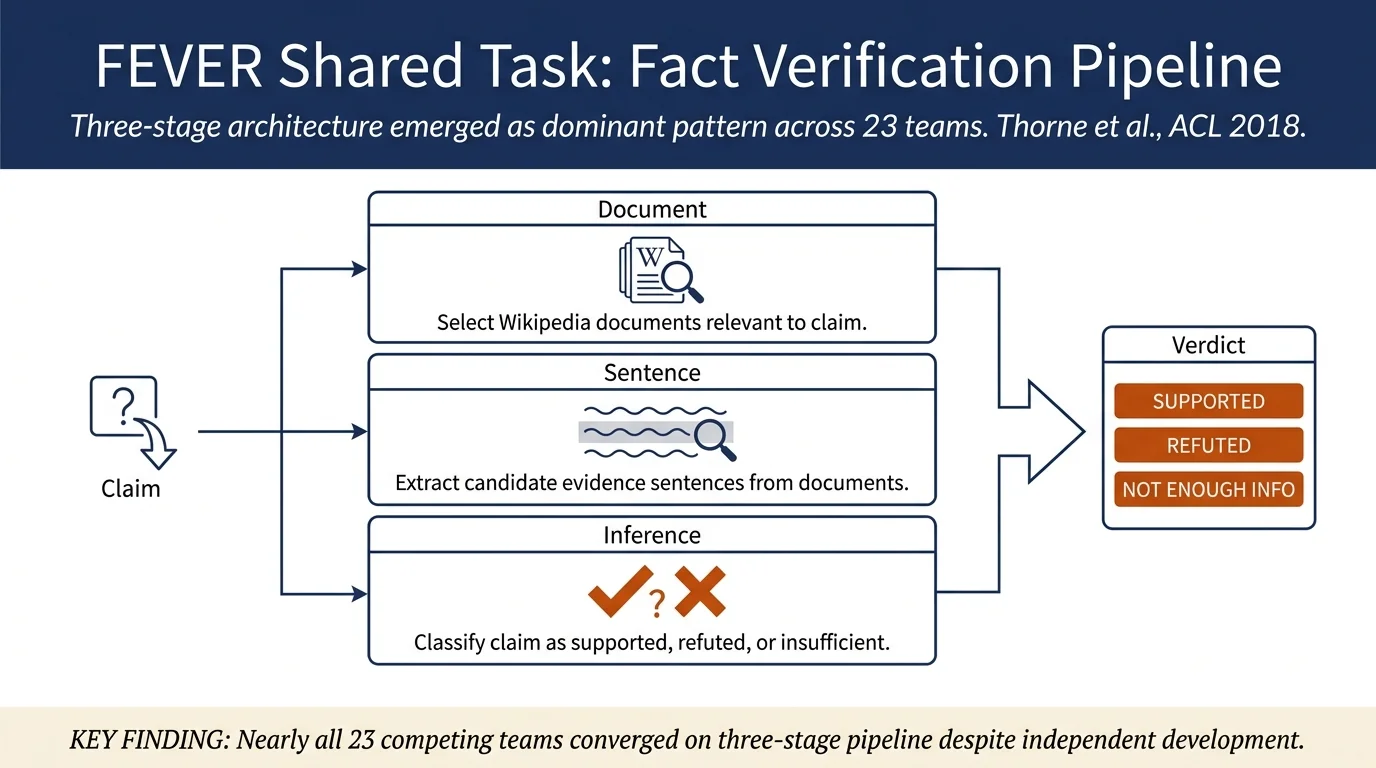
This paper presents results of the first FEVER shared task competition, which challenged 23 teams to classify whether human-written factoid claims could be SUPPORTED or REFUTED using evidence retrieved from Wikipedia. The best system achieved 64.21% FEVER score, demonstrating the difficulty of joint evidence retrieval and natural language inference for fact verification; most participating systems followed a three-stage pipeline (document selection, sentence selection, NLI) though some jointly optimized evidence extraction and verification.
Contributions¶
- First large-scale shared task on fact extraction and verification, establishing a benchmark combining evidence retrieval from a corpus with textual entailment reasoning
- 185,445 human-generated claims dataset (FEVER) with three labels (SUPPORTED, REFUTED, NOT ENOUGH INFO), manually verified against Wikipedia with annotated evidence sentences
- Comprehensive system analysis across 23 teams showing dominant architectural patterns: document retrieval via named entities/Wikipedia search → sentence selection via neural classifiers → NLI via Enhanced LSTM or Transformers
- Evidence augmentation methodology: post-competition annotation of previously unseen correct evidence from 18,846 claims, identifying 308 new evidence sets and correcting 87 mislabeled claims
Method¶
The FEVER shared task requires systems to:
- Classify claim veracity into three classes: SUPPORTED (evidence fully supports the claim), REFUTED (evidence contradicts it), or NOT ENOUGH INFO (Wikipedia contains insufficient evidence)
- Retrieve supporting or refuting evidence as complete sets of Wikipedia sentences—claims require evidence for SUPPORTED/REFUTED labels to count toward the primary FEVER score
Dataset construction: Claims were generated by paraphrasing Wikipedia facts and applying systematic mutations (some meaning-preserving, some meaning-altering). Annotators selected evidence sentences without knowing the source pages. The dataset was split by generating Wikipedia page, creating disjoint train/dev/test splits (80,035 SUPPORTED / 29,775 REFUTED / 35,639 NOT ENOUGH INFO in training).
Scoring metric: The primary metric is label accuracy conditioned on providing at least one complete set of evidence. Precision, recall, and F₁ of evidence are also reported to diagnose retrieval vs. reasoning performance.
Results¶
Final leaderboard (86 total submissions from 23 teams): - Rank 1 (UNC-NLP): 64.21% FEVER score, 70.91% label accuracy, 42.27% evidence precision - Rank 2 (UCL Machine Reading Group): 62.52%, 82.84% label accuracy, 22.16% evidence precision - Rank 3 (Athene UKP TU Darmstadt): 61.58%, 85.19% label accuracy, 23.61% evidence precision - Baseline (published earlier): 27.45% FEVER score
Architectural patterns identified:
Document selection: Multi-step approaches using named entities, noun phrases, and capitalized expressions. Top teams reported using Wikipedia search API or Lucene/Solr indexes. UNC-NLP ranked candidates by Wikipedia page viewership statistics.
Sentence selection: Three approaches prevalent—keyword matching (token/NE overlap), supervised binary classification (Enhanced LSTM, Decomposable Attention), and similarity scoring (Word Mover's Distance, cosine similarity over ELMo/TFIDF embeddings).
Natural language inference: All submissions modeled NLI as supervised classification. Evidence combination strategies varied: UNC-NLP concatenated evidence into a single string; others classified evidence-claim pairs individually then aggregated. Sentence representations ranged from non-lexical features (negation, antonyms, noun overlap) to contextualized embeddings (ELMo, WordNet).
Connections¶
- Extends SemEval-2017 Task 8: RumourEval: Determining rumour veracity and support for rumours by adding evidence retrieval as a required subtask alongside stance detection
- Related to EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection via shared focus on integrating evidence into fake news detection pipelines
- Precursor dataset to extensive fact verification research; cited in A Survey on Natural Language Processing for Fake News Detection as a major benchmark for textual entailment and evidence-based methods
- Related to Fact-Checking: A Meta-Analysis of What Works and for Whom for formal definition of fact-checking task and evaluation metrics
Notes¶
Strengths: - First shared task to jointly require evidence retrieval from a large corpus and reasoning over retrieved evidence, capturing a realistic fact-verification scenario - Large annotated dataset (185,445 claims) with high-quality Wikipedia evidence; split by generating page ensures test generalization - Post-competition evidence annotation (1,003 additional annotations) identified correctable label noise, improving dataset quality - Transparent leaderboard with detailed system descriptions from 15 of 23 teams, enabling architectural comparison and reproducibility - Scoring metric (FEVER score) correctly incentivizes both evidence precision and verification accuracy
Weaknesses: - Dataset construction via paraphrasing Wikipedia facts introduces artificial claim generation; coverage of real-world misinformation types (satire, rumors, synthetic claims) is limited - Wikipedia as sole evidence source limits real-world applicability; many claims require cross-domain or out-of-date information - Evidence annotation by participants post-hoc rather than during dataset construction; incomplete evidence coverage in original annotations may have underestimated true performance - NOT ENOUGH INFO label definition unclear; some claims labeled NEI should arguably be REFUTED (e.g., claims about recent events Wikipedia hadn't covered at annotation time) - Top-performing systems achieved only 64.21% FEVER score despite simple baseline structure, suggesting fundamental difficulty of the joint task remains unresolved
Follow-up opportunities: - Scaling evidence sources beyond Wikipedia (news archives, scientific papers, domain-specific databases) - Multi-hop reasoning where evidence spans multiple Wikipedia pages or requires inference chains - Out-of-domain generalization to non-Wikipedia claims and different evidence sources - Real-time fact-checking systems addressing continuous information updates