A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT¶
Authors: Yihan Cao, Siyu Li, Yixin Liu, Zhiling Yan, Yutong Dai, Philip S. Yu, Lichao Sun Venue: J. ACM, Vol. 37, No. 4, Article 111 ArXiv: 2303.04226
TL;DR¶
This is the first comprehensive survey of AI-Generated Content (AIGC) covering the history, techniques, and applications of generative models from GANs through ChatGPT. It addresses both the impressive capabilities of these models (text, image, audio, video generation) and critical concerns including factuality, security, privacy, and potential for spreading misinformation. The paper catalogs foundation models, multimodal architectures, applications across domains, and open challenges for responsible deployment.
Contributions¶
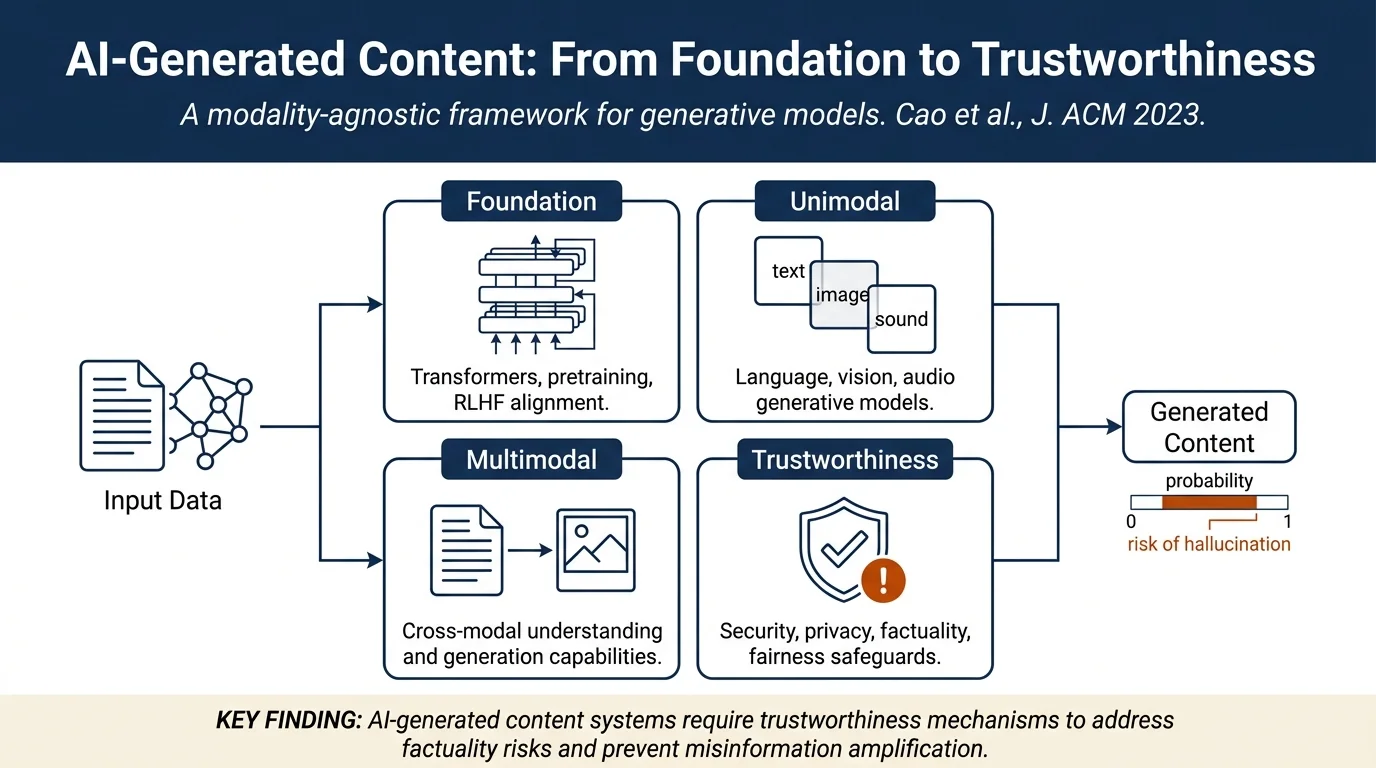
The paper provides: - A comprehensive review of AIGC techniques, organized by modality (unimodal vs. multimodal generation) - Historical context on generative AI development from early models (HMMs, VAEs, GANs) through transformer-based architectures to modern large language models - Technical overview of foundation models (transformers, pre-trained language models, RLHF) - Detailed coverage of unimodal generative models (language models like GPT, BART, T5; vision models like GANs, diffusion models, VAEs; audio/music generation) - Survey of multimodal generation (text-to-image, text-to-video, cross-modal models) - Review of real-world applications (chatbots, art generation, music, code, education) - Analysis of efficiency challenges and solutions (prompt learning, model compression, distributed training) - Critical discussion of trustworthiness and responsible AIGC (security, privacy, fairness, factuality) - Identification of open problems and future research directions
Method¶
The survey organizes AIGC along multiple dimensions:
Foundation Models: Transformers serve as the backbone for most modern AIGC systems. The paper covers transformer architecture (self-attention, encoder-decoder variants), pre-trained language models (masked language modeling for BERT, autoregressive models for GPT), and Reinforcement Learning from Human Feedback (RLHF) for aligning outputs with human preferences.
Unimodal Generation: - Language models are categorized as decoder-only (GPT), encoder-decoder (T5, BART), or bidirectional (BERT variants) - Vision models include GANs (Generative Adversarial Networks) with variants like Progressive GAN and StyleGAN, VAEs (Variational Autoencoders), normalizing flows, and diffusion models (recently becoming dominant for image generation) - Audio/music generation using models like AIVA and Jukebox - Code generation via models like CodeGPT
Multimodal Generation: - Vision-language models combining image and text understanding - Text-to-image models using diffusion (Stable Diffusion, DALL-E) - Cross-modal understanding across text, vision, and audio
Applications: The survey maps real applications to their underlying models (ChatGPT, Meena, BlenderBot for dialogue; DALL-E, Stable Diffusion for image generation; CodeGPT, Copilot for code; Minerva for education).
Results¶
The paper catalogs major milestones in AIGC development with dates, model architectures, and key capabilities. Key technical findings include:
- Scaling laws: Model performance improves predictably with scale (parameters, data volume, compute), with GPT-3 demonstrating emergent abilities from large-scale pretraining
- Efficiency-performance tradeoffs: Methods like model compression, prompt engineering, and parameter-efficient fine-tuning reduce computational requirements while maintaining quality
- Multimodal convergence: Foundation models trained on diverse modalities show improved generalization compared to unimodal specialists
- RLHF effectiveness: Alignment with human feedback significantly improves output quality and reduces undesired behaviors
Connections¶
- Related to Propagation-based fake news detection through the role of AI-generated content as a misinformation vector
- Extends Deepfake Detection by covering generation of synthetic content across all modalities
- Complements Factuality In NLP by documenting hallucination and factuality challenges across language models
- Relevant to Adversarial robustness in the context of security vulnerabilities in AIGC systems
- Cited in works on misinformation amplification via synthetic content
Notes¶
Strengths: - Exceptionally comprehensive coverage of both language and vision modalities, unusual for AIGC surveys - Technical depth on foundation architectures (transformers, diffusion models, GANs) combined with practical applications - Dedicated sections on trustworthiness (factuality, toxicity, privacy, fairness) that directly address concerns for this wiki - Clear organization from foundations through applications to challenges - Honest treatment of limitations: acknowledges hallucination in language models, deepfake risks, and privacy vulnerabilities
Limitations and gaps: - For a 2023 survey, the treatment of recent multimodal models (GPT-4V, LLaVA) is necessarily incomplete - Security section focuses primarily on known attack vectors; emerging adversarial approaches may not be captured - Limited quantitative comparison of factuality across different model sizes and training approaches - Policy and regulation discussion is brief given the real-world importance
Relevance to fake news wiki: This survey is fundamental for understanding how AI-generated content is created and why it poses risks to information integrity. The security section (7.1) directly documents factuality and hallucination issues in language models, including NewsGuard's findings that ChatGPT generated false narratives. The privacy section (7.2) covers data extraction and membership inference attacks. The paper provides context for how misinformation can be scaled via these technologies and what technical countermeasures exist (factual grounding, retrieval-augmented generation, constitutional AI). This is essential reading for researchers studying AI-augmented misinformation and detection approaches.