Attention Is All You Need¶
Authors: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
Venue: Advances in Neural Information Processing Systems (NeurIPS), 2017
ArXiv: 1706.03762
TL;DR¶
The authors introduce the Transformer, a sequence transduction model based entirely on self-attention mechanisms that dispenses with recurrence and convolution. The model achieves state-of-the-art BLEU scores on machine translation tasks while being significantly more parallelizable and requiring less training time. The architecture generalizes well to other sequence modeling tasks like parsing.
Contributions¶
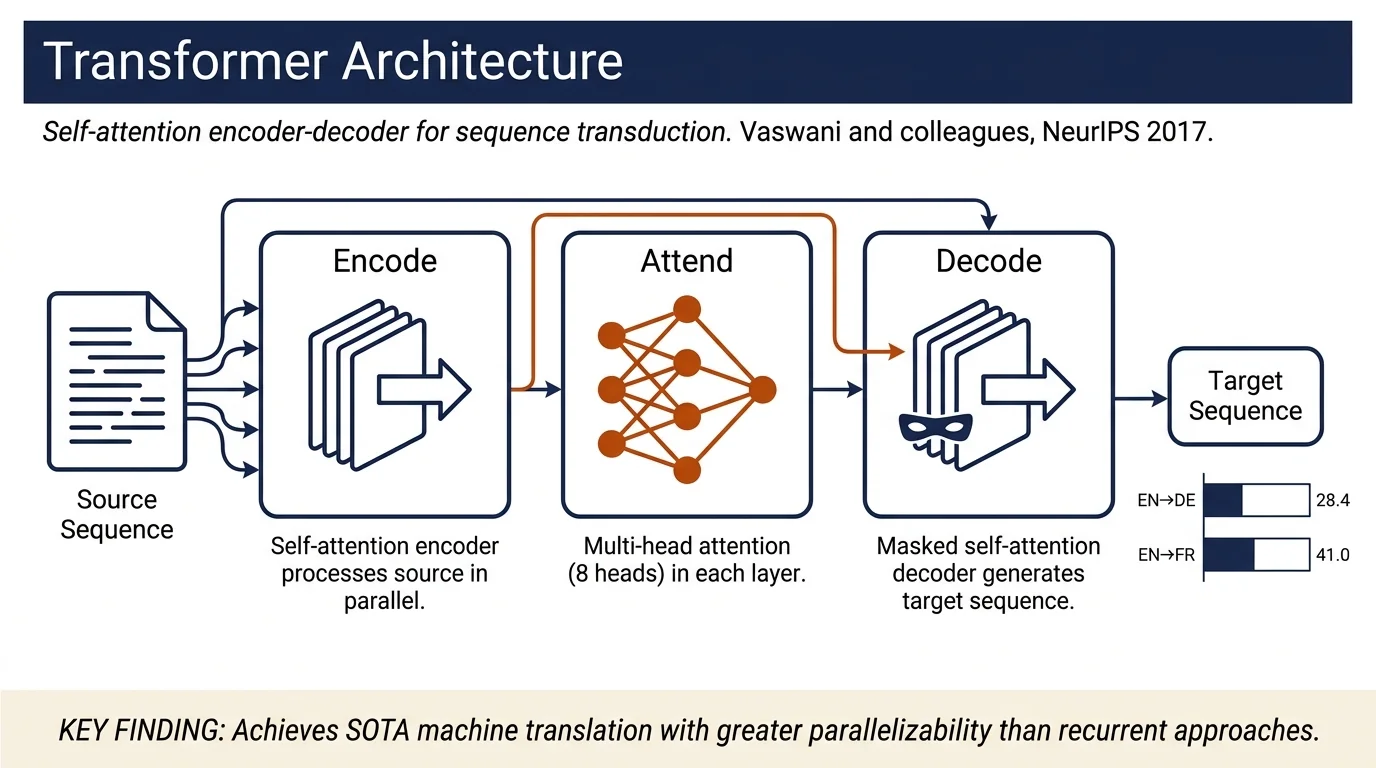
- Proposes the Transformer architecture, the first sequence transduction model relying entirely on self-attention to draw global dependencies between input and output without using recurrent or convolutional layers.
- Introduces scaled dot-product attention and multi-head attention mechanisms that allow the model to jointly attend to information from different representation subspaces at different positions.
- Achieves new state-of-the-art BLEU scores on WMT 2014 English-German (28.4) and English-French (41.0) translation tasks, improving over previous ensembles while requiring significantly fewer training resources.
- Demonstrates strong generalization to other tasks: achieves 93.3 F1 on WSJ Section 23 English constituency parsing with minimal task-specific tuning.
Method¶
The Transformer uses a standard encoder-decoder architecture where both encoder and decoder consist of stacked identical layers. The encoder and decoder each contain N = 6 layers.
Attention mechanisms: The core innovation is the attention function, which maps queries and key-value pairs to outputs. The model uses scaled dot-product attention:
where queries, keys, and values are all vectors of dimension d_k. Instead of a single attention function, the model uses multi-head attention, which allows the model to jointly attend to information from h = 8 different representation subspaces. Each head operates on reduced-dimension projections (d_k = d_v = d_model/h = 64), and the outputs are concatenated.
Architecture details: Each layer in both encoder and decoder contains two sub-layers: (1) multi-head self-attention, and (2) a position-wise fully connected feed-forward network. Residual connections surround each sub-layer, followed by layer normalization. The encoder uses self-attention on all positions in the input sequence. The decoder uses masked self-attention (preventing positions from attending to subsequent positions) and multi-head attention over encoder outputs.
Positional encoding: Since the model contains no recurrence or convolution, the model must inject information about the relative or absolute position of tokens. The authors use sinusoidal positional encodings with different frequencies:
Results¶
Machine translation: - WMT 2014 English-to-German: Transformer (big) achieves 28.4 BLEU, improving over the previous state-of-the-art ensemble of 26.36 (Conv2S2 Ensemble). - WMT 2014 English-to-French: Transformer (big) achieves 41.0 BLEU, improving significantly over previous single-model state-of-the-art. - Training efficiency: The base Transformer model trained for 100K steps takes 3.3 × 10^{18} FLOPs; the big model trained for 300K steps requires 2.3 × 10^{19} FLOPs. Both are substantially cheaper than prior approaches.
English constituency parsing: - WSJ Section 23: Transformer (4-layer) achieves 92.7 F1 with semi-supervised training, competitive with or exceeding previous specialized parsing models without task-specific tuning.
Connections¶
- Foundation for Transformer-based architectures widely used in NLP and misinformation detection.
- Multi-head attention mechanism cited extensively in attention-based detection methods.
- Enables efficient sequence modeling for tasks like stance detection, rumor detection, and fake news detection.
- Building block for models like BERT and GPT, which are applied across the fake news detection literature.
Notes¶
This is the canonical reference for Transformer architectures and self-attention. Its simplicity and parallelizability have made it the de facto standard in NLP. The paper's clarity on attention mechanisms and positional encodings makes it an essential reference for understanding modern neural approaches to text processing. The generalization results on constituency parsing demonstrate the architecture's robustness beyond the original machine translation motivation.