MultiFC: A Real-World Multi-Domain Dataset for Evidence-Based Fact Checking of Claims¶
Authors: Isabelle Augenstein, Christina Lioma, Dongsheng Wang, Lucas Chaves Lima, Casper Hansen, Christian Hansen, Jakob Grue Simonsen
Affiliation: University of Copenhagen, Department of Computer Science
Venue: arXiv preprint, 2019 — arXiv:1909.03242
TL;DR¶
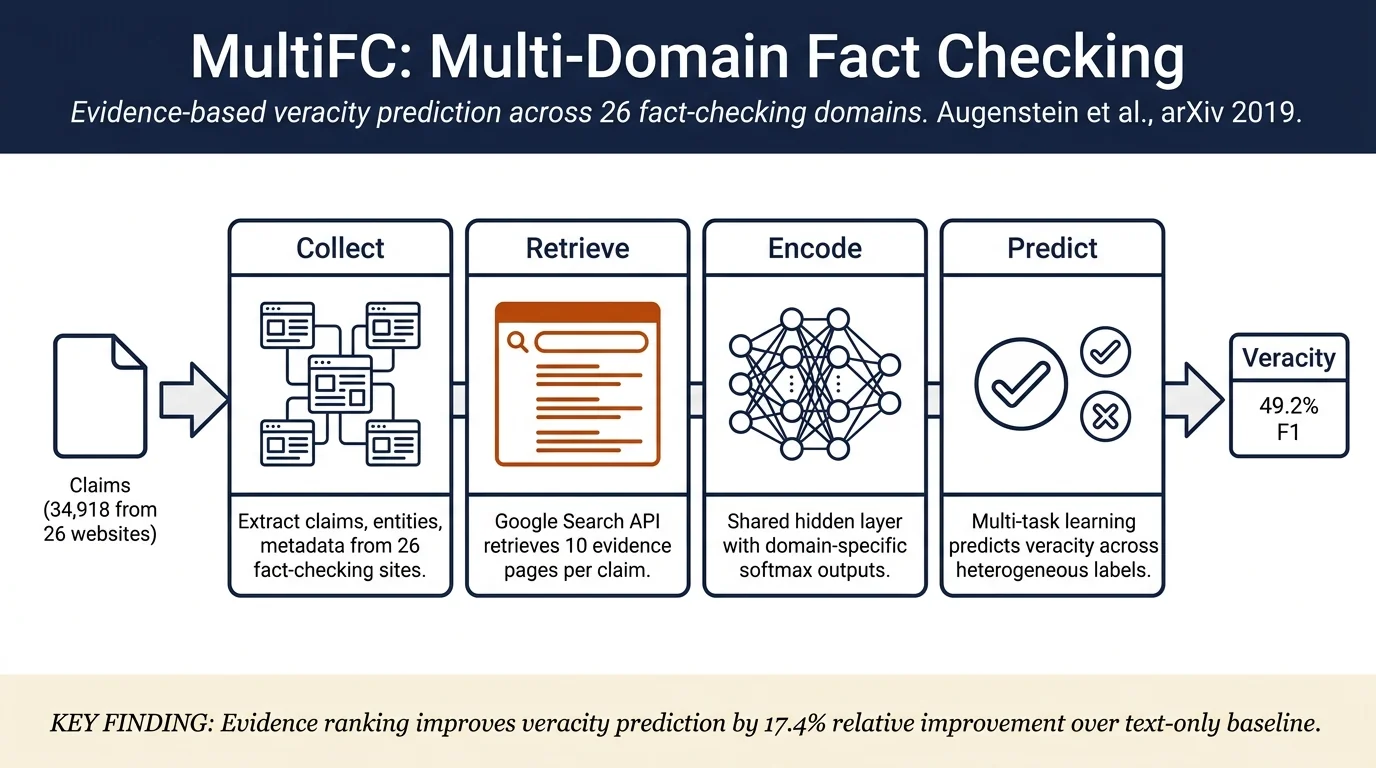
MultiFC is the largest publicly available real-world dataset of naturally occurring factual claims (34,918 claims) collected from 26 fact-checking websites, with rich metadata, evidence pages retrieved via Google Search, and entity linking to Wikipedia. The paper demonstrates that evidence ranking combined with veracity prediction significantly improves over evidence-agnostic baselines, achieving a best Macro F1 of 49.2%, and shows that multi-domain heterogeneity presents a challenging testbed for fact verification.
Contributions¶
- Largest real-world fact-checking dataset: 34,918 naturally occurring claims collected from 26 fact-checking websites in English, substantially larger than prior datasets (prior largest was ~10,564)
- Rich metadata and annotations: Each claim includes categorical metadata (reason for label, speaker, fact-checker, publication date, claim date), entity linking to Wikipedia (25,763 unique entities, 15,351 claims contain Wikipedia-linkable entities), and verbatim text extracted from fact-checking websites
- Evidence retrieval pipeline: Evidence pages retrieved via Google Search API using claim text as query; resulting corpus includes Wikipedia, news outlets, government sites, and other authoritative sources
- Multi-domain veracity labels: Claims span 26 fact-checking domains with heterogeneous label schemas (ranging from 2 to 27 distinct labels per domain), necessitating multi-task learning approaches
- Joint evidence and veracity prediction: Novel multi-task learning approach jointly learns to rank evidence pages and predict claim veracity across domains with disparate label spaces, achieving Macro F1 of 49.2%
- Comprehensive analysis: Dataset characterization identifying entity distributions, evidence source prevalence, domain-level label heterogeneity, and performance analysis with baseline models
Method¶
Data collection involves three stages:
Stage 1: Website Crawling. All active English-language fact-checking websites listed on Duke Reporters' Lab and the Fact Checking Wikipedia page were targeted for crawling. Ten websites could not be crawled due to protection (SSL/TLS, timeouts, paywalls, or crawling restrictions); crawling succeeded for 38 websites spanning 26 domains. Each domain is a specific fact-checking organization (e.g., PolitiFact, FactCheck.org), with some organizations managing multiple subdomains.
Stage 2: Claim and Evidence Extraction. From each crawled website, claims and associated metadata are extracted: claim text, claim ID, verification label, fact-checker identity, speaker, claim date, publication date, and claim category/reason for label. When available, hyperlinked text and full article text are captured. Claim text is submitted verbatim to Google Search API without quotes; the 10 most highly ranked results are retrieved as evidence pages, storing title, URL, timestamp, and full web page content.
Stage 3: Entity Linking. Named entities (persons, organizations, locations, other entities) within claims are recognized and linked to Wikipedia pages using the state-of-the-art neural entity linking model (Kolitsas et al., 2018). For claims with multiple references to the same entity, disambiguation via Wikipedia link context is applied.
Veracity prediction modeling employs multi-task learning (MTL) to handle domain heterogeneity:
- Base architecture: Deep neural network with shared hidden layer (h ∈ ℝ^d) and task-specific softmax output layers. For each domain's veracity prediction task, a task-specific weight matrix W^T_i ∈ ℝ^{L_i × h} and bias b^T_i ∈ ℝ^{L_i} define per-domain label distributions
- Input encoding: Claims encoded as concatenation of claim text representation and optional metadata (speaker, fact-checker, claim category, publication metadata)
- Evidence encoding: Evidence pages ranked using claim-evidence similarity; top-ranked evidence incorporated into claim representation via weighted average of evidence embeddings
- Multi-task training: Joint optimization across all domain-specific veracity tasks; label embedding layers project disparate label spaces into fixed-length embedding space, enabling knowledge transfer across domains
Results¶
Dataset statistics:
- Total claims: 34,918 (after removing duplicates and claims occurring <5 times per label)
- Domain coverage: 26 fact-checking websites (ranging from 20 to 2,943 claims per domain)
- Entity statistics: 25,763 unique entities detected; 15,351 claims (42.0%) contain entities linkable to Wikipedia; average 2.9 entities per claim; maximum 35 entities in single claim
- Evidence retrieval: Successfully retrieved evidence pages for majority of claims; corpus includes Wikipedia (4.425%), Snopes (3.992%), Washington Post (3.025%), New York Times (2.478%), and 30+ other sources
- Label heterogeneity: Domains employ 2–27 distinct veracity labels (e.g., "correct/incorrect" vs. "true/mostly true/half true/misleading/mostly false/false/unsubstantiated")
Baseline model performance:
- Evidence-agnostic baseline: Macro F1 = 41.8% across domains
- Evidence ranking + veracity prediction: Macro F1 = 49.2% (17.4% relative improvement)
- Performance variation: Domain-level F1 ranges from 30–75%, reflecting label heterogeneity and claim difficulty
Cross-domain analysis:
- Multi-task learning with shared hidden representation outperforms domain-specific models, demonstrating benefit of learning across domains
- Encoding metadata (speaker, fact-checker, reason for label) contributes to improved performance
- Evidence pages assist veracity prediction; domains with longer evidence documents and more available evidence achieve higher accuracy
Connections¶
- Related to FEVER: A Large-Scale Dataset for Fact Extraction and VERification through focus on evidence-based fact verification with large-scale claim dataset, but differs in real-world vs. constructed claims and heterogeneous vs. homogeneous labels
- Extends Liar, Liar Pants on Fire: A New Benchmark Dataset for Fake News Detection by incorporating evidence pages and multi-domain structure
- Related to EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection via joint treatment of evidence ranking and veracity prediction
- Cited by A Survey on Natural Language Processing for Fake News Detection as comprehensive benchmark for fact-checking and evidence retrieval methods
- Related to Embracing Domain Differences in Fake News: Cross-domain Fake News Detection using Multimodal Data through multi-domain learning for misinformation detection
Notes¶
Strengths:
- Largest real-world fact-checking dataset at publication (34,918 claims); naturally occurring claims from 26 diverse fact-checking sources provide broad coverage of misinformation phenomena
- Rich metadata (entities, speakers, categories, temporal information) and evidence pages enable complex feature engineering and evidence-based approaches
- Multi-domain nature with heterogeneous labels reflects real-world fact-checking practice and motivates transfer learning approaches
- Comprehensive dataset analysis identifies key challenges: label heterogeneity, domain variation, and entity distribution
- Entity linking to Wikipedia connects claims to structured knowledge, enabling knowledge-graph-based approaches
Weaknesses:
- Label heterogeneity (2–27 labels per domain) complicates unified evaluation and model comparison; label remapping necessary for learning, potentially introducing error
- Evidence retrieval via Google Search may miss relevant sources or introduce temporal bias; changes in search rankings over time affect reproducibility
- Not all fact-checking websites provide uniform coverage or metadata; some domains under-represented
- English-only coverage limits applicability to multilingual misinformation
- Best model achieves Macro F1 of 49.2%, indicating substantial remaining difficulty; performance varies widely across domains
- Evidence pages sometimes unavailable or off-topic; correlation between evidence availability and accuracy not fully characterized
Future directions:
- Cross-lingual fact verification using multilingual sources
- Temporal fact verification incorporating claim publication and fact-checking dates
- Fine-grained veracity labels capturing nuance beyond binary true/false
- Integration of knowledge graphs and structured knowledge bases
- Real-time claim verification on emerging claims
- Investigation of domain transfer and few-shot learning for low-resource fact-checking sites