Embracing Domain Differences in Fake News: Cross-domain Fake News Detection using Multimodal Data¶
Authors: Amila Silva, Ling Luo, Shanika Karunasekera, Christopher Leckie
Affiliation: School of Computing and Information Systems, The University of Melbourne
Venue: AAAI 2021 — arXiv
TL;DR¶
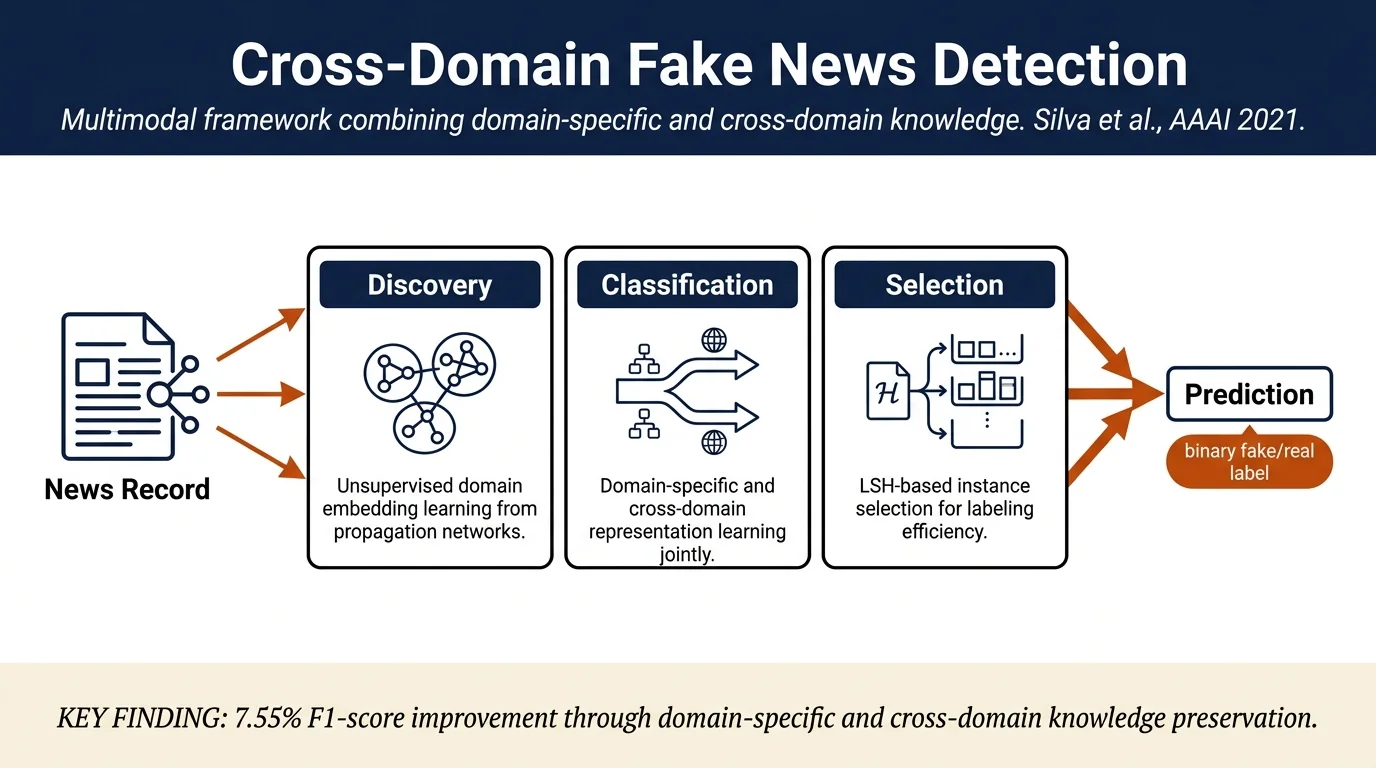
Most fake news detection models are trained on a single domain (e.g., politics) and fail when tested on others (e.g., entertainment, COVID-19). This paper proposes a multimodal framework that leverages both domain-specific and cross-domain knowledge to detect fake news across different domains. Using unsupervised domain discovery and supervised domain-agnostic classification, the model achieves 7.55% F1-score improvement over baselines on rarely-appearing domains.
Contributions¶
- A multimodal fake news detection framework that exploits both domain-specific and cross-domain knowledge without requiring hard domain labels.
- An unsupervised domain embedding learning technique using propagation networks and textual content to discover domains in unlabeled data.
- A supervised domain-agnostic classification module using domain-specific and cross-domain embedding spaces to preserve both local and global knowledge.
- An LSH-based instance selection technique to reduce manual labeling cost while maintaining domain coverage across multiple datasets.
- Empirical validation on three public datasets (PolitiFact, GossipCop, CoAID) showing substantial improvements on rarely-appearing domains.
Method¶
The proposed framework consists of two main components: (1) unsupervised domain discovery and (2) supervised domain-agnostic fake news classification.
Unsupervised Domain Discovery (Module A): The framework constructs a heterogeneous network from news propagation patterns (users tweeting/sharing news, words appearing in titles) using a two-step process. First, communities in this network are detected using the Louvain algorithm to identify distinct user groups with homophilous interests. Second, domain embeddings are learned by concatenating the soft-membership probabilities of communities, yielding low-dimensional representations that cluster records by domain.
Supervised Domain-agnostic Classification (Module B): Each news record is represented as a multimodal vector combining text content (via BERT) and propagation network features. The classification model maps input into two separate subspaces: one preserving domain-specific knowledge (via a domain-specific decoder) and one preserving cross-domain knowledge (via a shared decoder). The domain-specific and cross-domain decoders are trained jointly with an adversarial loss to ensure that domain information does not leak into the cross-domain representation.
LSH-based Instance Selection (Module C): To address the labeling cost when training across multiple domains, the model uses Locality-Sensitive Hashing to select high-quality instances that maximize domain coverage. The method works by: (1) creating random hash functions mapping records to buckets; (2) constructing a hash table; (3) randomly picking records from hash buckets with equal probability; (4) repeating until the dataset size reaches the labeling budget. This approach substantially outperforms random selection for rarely-appearing domains.
Results¶
The model was evaluated on three public datasets combined to create a cross-domain dataset: PolitiFact (269 fake, 280 real), GossipCop (1,269 fake, 2,466 real), and CoAID (135 fake, 1,568 real).
Main results: The proposed approach achieves 0.836–0.869 F1-score across domains, substantially outperforming seven widely-used baselines (LIWC, TextCNN, HPNF+SVM, EANN-Unimodal, EANN-Multimodal, HPNF+SVM, SAFE) which achieve 0.744–0.831 F1-score. The best baseline (EANN-Multimodal) achieves 0.833 F1-score, showing the importance of domain-specific knowledge and the ability of the proposed approach to capture domain-specific information while generalizing across domains.
Ablation study: Removing domain-specific loss (Eq. 5) drops F1-score by ~3%, removing network modality drops by ~3%, and removing text modality drops by ~2%, demonstrating the value of each component. The LSH-based instance selection approach yields 24% F1-score improvement for PolitiFact and 27% for CoAID when compared to random selection, with substantially better domain coverage.
Connections¶
- Related to Wang et al. (2018) — EANN via shared focus on multimodal fake news detection; this work extends to cross-domain settings and introduces unsupervised domain discovery.
- Related to Zhou et al. (2020) — SAFE via shared attention mechanism on multiple modalities for fake news detection.
- Related to Shu et al. (2018) — FakeNewsNet as a source of evaluation datasets (PolitiFact and GossipCop).
- Related to Propagation-based fake news detection via use of propagation networks to capture domain-specific knowledge.
Notes¶
This paper addresses a critical practical problem: fake news detectors trained on one domain often fail dramatically on others. The key insight is that domain differences are not random noise but systematic patterns in user behavior and language that should be preserved rather than averaged out. The unsupervised domain discovery approach is elegant—using network structure to infer domains without labels—though it assumes communities correlate with domains, which may not always hold. The LSH-based instance selection is a practical contribution for practitioners managing labeling budgets across multiple domains.