FEVER: A Large-Scale Dataset for Fact Extraction and VERification¶
Authors: James Thorne, Andreas Vlachos, Christos Christodoulopoulos, Arpit Mittal
Affiliation: University of Sheffield, Amazon Research Cambridge
Venue: arXiv preprint, 2018 — arXiv:1803.05355
TL;DR¶
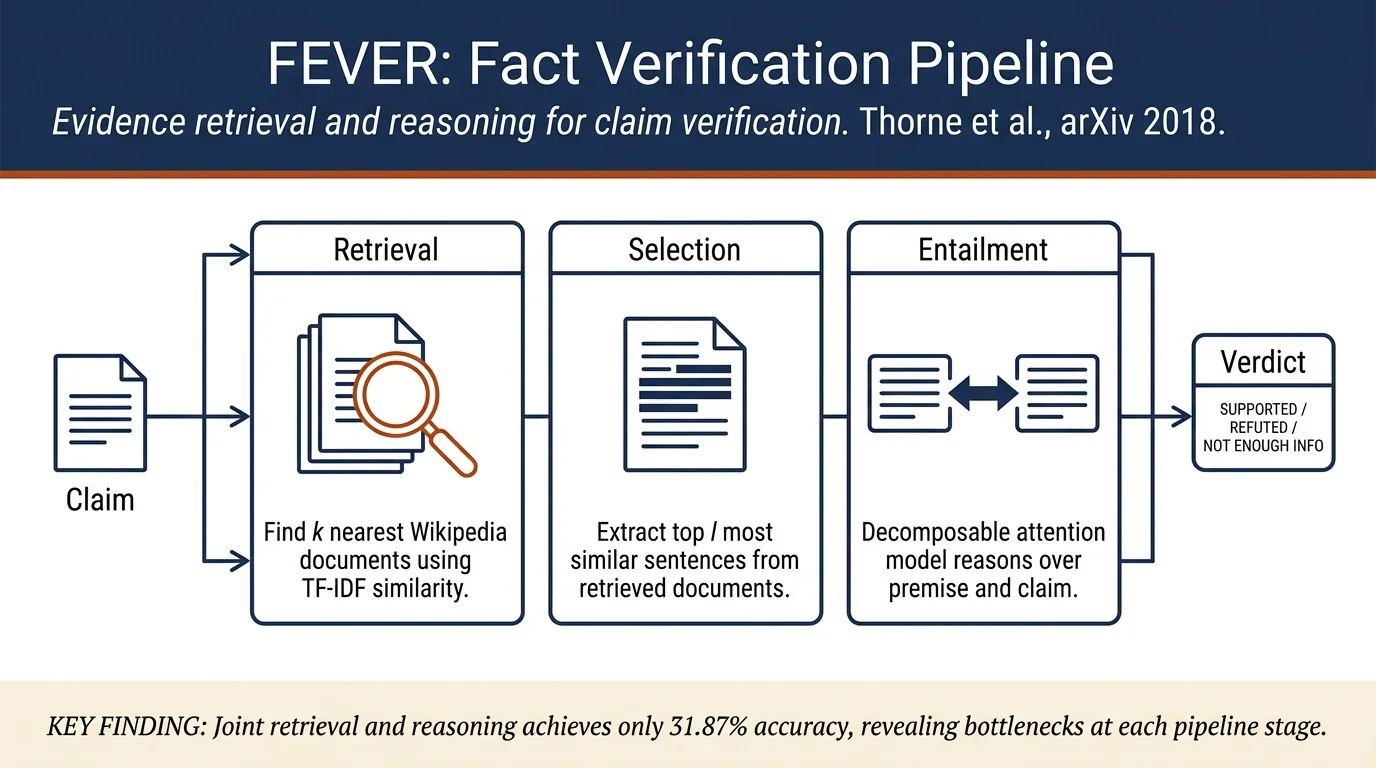
This paper introduces FEVER, a large-scale dataset of 185,445 human-verified claims with Wikipedia evidence for training fact verification systems. Claims are generated from Wikipedia and labeled as SUPPORTED, REFUTED, or NOT ENOUGH INFO; the paper presents a three-stage baseline pipeline (document retrieval, sentence selection, textual entailment) achieving 31.87% accuracy when requiring correct evidence, demonstrating the challenge of jointly retrieving evidence and reasoning over it.
Contributions¶
- Large-scale dataset for fact verification: 185,445 claims generated from Wikipedia introductory sections, verified by human annotators against Wikipedia sources with inter-annotator agreement of 0.6841 Fleiss κ
- Three-class claim classification: SUPPORTED (claim fully supported by evidence), REFUTED (contradicted by evidence), or NOT ENOUGH INFO (insufficient Wikipedia evidence available)
- Complex claim generation methodology: Claims created through systematic mutation of Wikipedia sentences (paraphrasing, entity substitution, word modifications) to generate natural-sounding but semantically complex claims
- Comprehensive baseline system: Three-component pipeline combining document retrieval, sentence selection, and natural language inference; best configuration achieves 31.87% FEVER score (31.87% label accuracy when requiring correct evidence) and 50.91% without evidence requirement
- Detailed annotation analysis: Multiple validation approaches including inter-annotator agreement (5-way on 4%), super-annotator coverage (1% sample), and author validation of 227 examples
Method¶
Dataset construction occurs in two stages:
Stage 1: Claim Generation. Annotators extract sentences from Wikipedia introductory sections (approximately 50,000 popular pages, processed with Stanford CoreNLP). For each selected sentence, annotators generate claims about single facts using dictionary knowledge (additional world knowledge provided to limit complexity) and specified mutation types: paraphrasing, entity substitution (same/different entity), relation modification, and negation. This produces claims with average length 9.4 tokens.
Stage 2: Claim Labeling. Annotators label each claim as SUPPORTED, REFUTED, or NOT ENOUGH INFO and identify evidence (sentences from any Wikipedia page supporting or refuting the claim). For SUPPORTED and REFUTED, annotators must find evidence; for NOT ENOUGH INFO, they confirm insufficient information is available. Annotation interface provides introductory section of claim entity plus linked Wikipedia pages as reference.
Baseline system comprises three components:
- Document Retrieval: Use DrQA TF-IDF implementation to return k nearest documents to claim using cosine similarity between binned unigram/bigram TF-IDF vectors
- Sentence Selection: Extract top l most similar sentences from k retrieved documents using TF-IDF similarity; simple unigram TF-IDF with binning and cosine similarity
- Recognizing Textual Entailment (RTE): Train decomposable attention model (Parikh et al., 2016) on premise-hypothesis pairs. For NOT ENOUGH INFO, sample random sentences or nearest pages to estimate upper bound accuracy
Results¶
Dataset statistics (185,445 total claims split into training/development/reserved test): - Training: 80,035 SUPPORTED, 29,775 REFUTED, 29,775 NOT ENOUGH INFO claims (139,585 total) - Development: 3,333 SUPPORTED, 3,333 REFUTED, 3,333 NOT ENOUGH INFO (9,999 total) - Test: 3,333 per class (9,999 total) - Reserved: 6,666 per class (19,998 total)
Baseline performance: - Document retrieval: With k=5 most similar documents, 55.30% of claims can be fully supported using retrieved documents before sentence selection; oracle accuracy 70.20% - Sentence selection: After applying TF-IDF sentence selection with l=5, 41.22% of claims can be fully supported using extracted sentences; oracle accuracy 62.81% for MLP, 56.02% for DA - Full pipeline: Best decomposable attention model with NEAREST PAGE strategy achieves 31.87% FEVER score (requiring correct evidence for SUPPORTED/REFUTED) and 50.91% ignoring evidence requirement; analysis reveals 13.84% of claims have misparsed entities
Inter-annotator agreement and validation: - 5-way agreement on 4% sample (n=7,506): Fleiss κ = 0.6841 (encouraging given task complexity) - Super-annotator coverage: 1% of data (n=1,005) annotated by super-annotators; regular annotators achieved >90% precision/recall; evidence coverage 95.42% precision, 72.36% recall - Author validation of 227 examples: 91.2% correctly labeled; 3% of mislabeled claims were annotation errors missed during labeling
Connections¶
- Extends SemEval-2017 Task 8: RumourEval: Determining rumour veracity and support for rumours by adding Wikipedia evidence retrieval requirement alongside claim labeling
- Related to Truth of Varying Shades: Analyzing Language in Fake News and Political Fact-Checking through focus on fine-grained claim verification with supporting evidence
- Precursor to The Fact Extraction and VERification (FEVER) Shared Task, which organized competition using this dataset with 23 participating teams
- Cited extensively in A Survey on Natural Language Processing for Fake News Detection as foundational benchmark for evidence-based fact verification and NLI approaches
- Related to EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection via joint treatment of evidence retrieval and verification reasoning
Notes¶
Strengths: - Large-scale (185,445 claims) carefully constructed dataset with systematic mutation types ensuring claim complexity beyond trivial paraphrasing - Wikipedia as evidence source enables precise sentence-level annotation and reproducibility; split by generating page ensures better test generalization - Multiple validation approaches (inter-annotator agreement, super-annotators, author validation) demonstrate reasonable data quality despite complexity - Three-class labeling (NOT ENOUGH INFO) captures realistic fact-checking scenario where claims cannot be verified from available sources - Detailed baseline analysis identifies specific bottlenecks: document retrieval achieves good recall (55.30% claims supportable in top-5 documents) but sentence selection becomes bottleneck (41.22% after selection) - Annotation guidelines and interface design address practical challenges (ambiguous entities, multi-hop inference requirements, negative mutation generation)
Weaknesses: - Artificial claim generation from Wikipedia may not reflect real-world misinformation distribution; Wikipedia facts differ systematically from disputed claims in online discourse - Wikipedia as sole evidence source limits applicability to contemporary events, scientific claims requiring up-to-date information, and non-encyclopedic sources - NOT ENOUGH INFO label conflates "information not in Wikipedia" with "unverifiable claim"; some labeled NOT ENOUGH INFO might be correctly identifiable with external sources - Mutation-based claim generation produces relatively simple semantic modifications; real misinformation often involves more complex transformations, decontextualization, or rhetorical techniques - Best baseline achieves only 31.87% (50.91% without evidence requirement), suggesting fundamental difficulty in jointly optimizing retrieval and reasoning remains unresolved - Evidence annotation conducted post-hoc during labeling rather than integrated into dataset construction; some claims may have incomplete evidence sets
Future directions: - Multi-document evidence combining information across Wikipedia pages - Dynamic/temporal fact verification for claims about recent events - Cross-lingual and multilingual fact verification - Hybrid evidence sources combining Wikipedia with news archives and scientific literature - Real-time claim verification with continuously updated information sources