SemEval-2017 Task 8: RumourEval¶
Authors: Leon Derczynski, Kalina Bontcheva, Maria Liakata, Rob Procter, Geraldine Wong Sak Hoi, Arkaitz Zubiaga
Venue: Proceedings of the 11th International Workshop on Semantic Evaluations (SemEval-2017), pages 69–76, August 3–4, 2017
DOI/URL: ACL Anthology
TL;DR¶
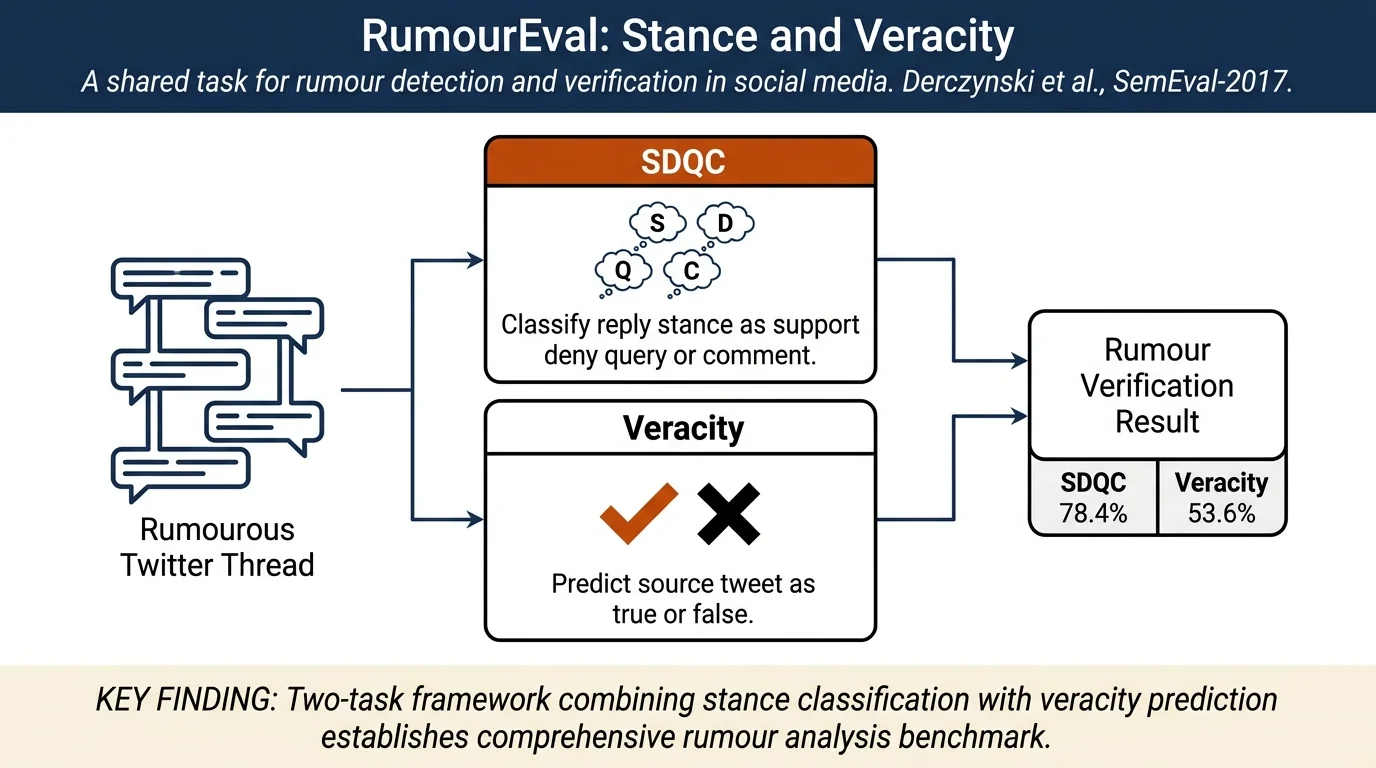
RumourEval is a shared task benchmark for detecting and verifying rumours in social media. It introduces two subtasks: (a) stance classification (SDQC: Support/Deny/Query/Comment) of replies to rumourous claims, and (b) veracity prediction (true/false) of source tweets. The task combines annotation schemes, datasets from 8–10 events, and results from 13 participating systems, establishing a foundation for rumour verification research on Twitter.
Contributions¶
- Annotation scheme for rumours and community reactions (SDQC framework)
- Large benchmark dataset with 297 training threads (8 events) and 28 test threads (10 events), totalling 5,599 tweets
- Two-subtask framework:
- Subtask A: Stance classification in conversation threads
- Subtask B: Veracity prediction of individual claims
- Evaluation metrics and baseline results from 13 systems, establishing benchmarks for the community
Method¶
Data collection and annotation¶
The task uses Twitter threads collected around newsworthy events. For each event, researchers:
- Sample likely rumourous tweets (high retweet count)
- Manually identify unverified claims (by journalist annotators)
- Collect all replies to each rumourous source tweet
- Annotate reply tweets via crowdsourcing (SDQC labels) and journalist consensus (veracity)
Training data: 297 threads across 8 events (Charlie Hebdo shooting, Ferguson unrest, Germanwings plane crash, etc.)
Test data: 28 additional threads including 2 new events (Hillary Clinton pneumonia rumour during 2016 election, Marina Joyce kidnapping rumour)
Subtask A: SDQC stance classification¶
Classify each reply tweet into one of four categories:
- Support (S): Author agrees with the rumour's veracity
- Deny (D): Author refutes the rumour
- Query (Q): Author requests additional evidence
- Comment (C): Author makes a comment without direct veracity stance
Replies form tree-structured conversations; context from preceding tweets is important.
Subtask B: Veracity prediction¶
Classify source tweets as true or false based on: - Closed variant: Tweet text only - Open variant: Tweet text + Wikipedia articles + archived linked URLs
Systems also report confidence scores (0–1); confidence of 0 indicates unverifiable claims.
Results¶
Subtask A (SDQC classification)¶
Best system (Turing): 78.4% accuracy using sequential LSTM classification accounting for tweet context.
| Rank | Team | Accuracy |
|---|---|---|
| 1 | Turing | 0.784 |
| 2 | UWaterloo | 0.780 |
| 3 | ECNU | 0.778 |
| Baseline (4-way) | – | 0.741 |
Key insight: Systems explicitly addressing class imbalance (especially over-representation of comments) performed best.
Subtask B (Veracity prediction)¶
Closed variant (best: IKM/NileTMRG, 53.6%): - Most systems underperformed the baseline (57.1%), suggesting veracity is AI-hard - Confidence calibration was weak even for correct predictions
Open variant (best: IITP, 39.3%): - Additional context (Wikipedia, archived URLs) did not substantially improve results - Indicates challenge lies beyond information retrieval
Connections¶
- Related to Stance Detection literature and SemEval-2016 Task 6 on general stance detection
- Builds on Pheme Project research framework for rumour analysis in social media
- Precedes Rumour Verification Surveys that synthesize follow-up work
- Foundational for Misinformation and fake news detection benchmarks in NLP
- Influenced subsequent work on Context Aware Rumour Detection and Temporal Rumour Evolution
Notes¶
Strengths: - Well-motivated task with clear real-world applications (journalism, crisis response) - Rigorous annotation protocol validated in prior work - Diverse global participant pool (13 teams from 4 continents) - Public dataset release with Twitter's compliance - Clear distinction from prior work (SemEval-2016 Task 6 on stance, SemEval-2015 Task 3 on CQA)
Limitations: - Class imbalance in SDQC (comments dominate, representing ~71% of training labels) - Inter-annotator agreement for replies only 62.2% (vs. 81.1% for source tweets), indicating task difficulty - Veracity prediction substantially harder than stance—even best systems underperform majority baselines - Limited to English Twitter; generalization to other languages/platforms unclear - 2016 Wikipedia snapshot used in open variant; temporal information incomplete for some events
Impact: This paper established RumourEval as the benchmark task in the field. Follow-up RumourEval editions (2018, later) extended the task, and the dataset remains widely cited in rumour detection research. The SDQC framework became standard in subsequent work on community-based claim verification.