BotOrNot: A System to Evaluate Social Bots¶
Authors: Clayton Davis, Onur Varol, Emilio Ferrara, Alessandro Flammini, Filippo Menczer
Venue: Proceedings of the 25th International Conference Companion on World Wide Web (WWW'16), April 2016
ArXiv: 1602.00975
TL;DR¶
BotOrNot is a publicly available service and API that evaluates whether a Twitter account is controlled by a human or automated bot. Using 1,000+ features across six categories (network, user, friends, temporal, content, sentiment), the system applies Random Forest classification to achieve 0.95 AUC on a labeled dataset of 15k bots and 16k legitimate accounts. Since its May 2014 release, the service has served over one million API requests from researchers, journalists, and the public.
Contributions¶
- First large-scale bot detection service: Public web and API access to bot classification, lowering barriers for non-technical researchers and journalists to identify suspicious accounts.
- Comprehensive feature engineering: Systematic extraction of 1,000+ features across six categories capturing different bot characteristics—network structure, temporal posting patterns, content language use, and sentiment signals.
- Practical deployment insights: Documents system stability, rate limiting, and API design lessons from operating a high-volume service (18k requests in first eight months, scaling to 540k+ monthly after API announcement).
- Reproducible baselines: Provides reference performance metrics (0.95 AUC) against manually verified social bots, enabling future work to measure progress.
System Design¶
Classification Features¶
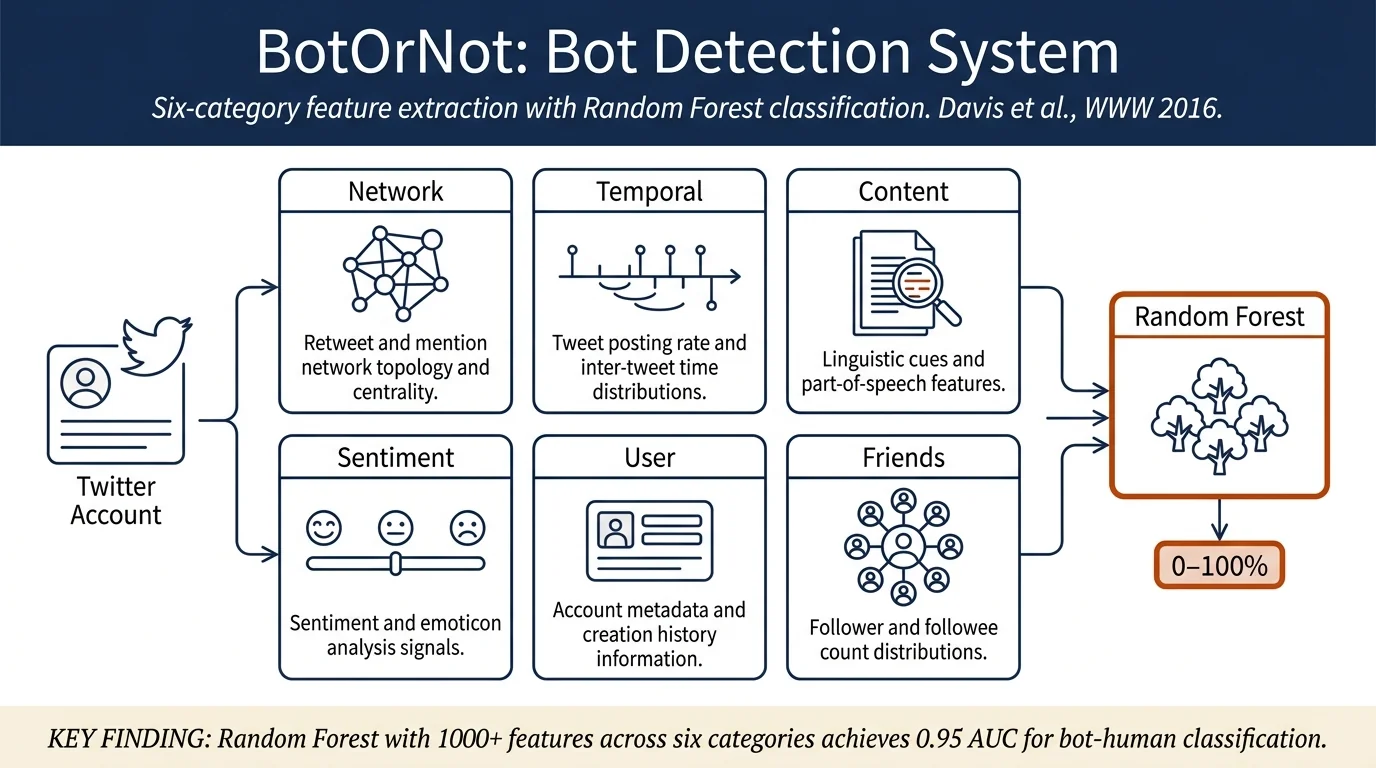
BotOrNot extracts features across six categories:
- Network features: Information diffusion patterns based on retweets, mentions, and hashtag co-occurrence networks (e.g., degree distribution, clustering coefficient, centrality measures).
- User features: Account metadata including language, geographic location, and account creation time.
- Friends features: Descriptive statistics of the account's social contacts (median, moments, and entropy of followers, followees, post counts).
- Temporal features: Timing patterns of content generation and consumption, including tweet rate and inter-tweet time distributions.
- Content features: Linguistic cues computed via part-of-speech tagging and natural language processing.
- Sentiment features: General-purpose and Twitter-specific sentiment analysis (happiness, arousal-dominance-valence, emoticon scores).
Classification Model¶
The system uses Random Forest, an ensemble supervised learning method. Seven separate classifiers are trained: one for each feature subclass and one for the overall bot-likelihood score. Models are trained on a dataset of 15,000 manually verified social bots and 16,000 legitimate human accounts comprising 5.6 million tweets. Ten-fold cross-validation yields a performance of 0.95 AUC (Area Under the Receiver Operating Characteristic Curve), though the authors note this likely overestimates current real-world performance given the age of the training data.
Service Architecture¶
Users interact via:
- Website: Browser-based interface where users enter a Twitter screen name and receive a bot-likelihood score (0–100%) with visualizations of feature contributions.
- Python API: botornot-python package enabling programmatic batch classification.
- REST API: HTTP endpoint with rate limiting matching Twitter's 180 requests per 15 minutes.
The service retrieves account data from Twitter's REST API (recent tweets and mentions), computes features on the BotOrNot server, and returns classification results either as visualizations (website) or JSON (APIs).
Results¶
Service Adoption¶
- May 2014: Service launched with web interface only (no public API).
- First 8 months: ~18,000 requests via website.
- December 2015: Public REST API announced; subsequent month delivered 540,000+ requests.
- Total by publication: Over 1 million cumulative API requests.
Performance¶
- Classification AUC: 0.95 on 10-fold cross-validation with 15k bots and 16k humans.
- Feature importance: Network, temporal, and content features are most discriminative.
- Score distribution: Analysis of 900k+ unique classifications reveals bimodal distribution, with clear separation between high-confidence human and bot accounts.
Connections¶
- The Rise of Social Bots — companion survey paper synthesizing social bot detection methods and characterizing bot behaviors that inform BotOrNot's feature design.
- Online Human-Bot Interactions — extended system paper describing large-scale population estimation and more nuanced bot-human interaction characterization.
- The Spread of Low-Credibility Content by Social Bots — empirical application of bot detection to measure amplification of misinformation during 2016 U.S. election.
- Detecting Bots on Russian Political Twitter — application of bot detection methods to identify state-sponsored bot networks.
- Arming the Public with Artificial Intelligence to Counter Social Bots — user study on how to communicate bot-likelihood scores interpretably to non-technical audiences.
Notes¶
Strengths:
- Practical accessibility: A publicly available service dramatically reduces friction for researchers and journalists investigating bot campaigns, democratizing bot detection research.
- Feature breadth: Combining network, temporal, content, and sentiment features captures diverse bot signatures—algorithmic bots, those spreading misinformation, and those engaging in financial manipulation exhibit different patterns.
- Deployment experience: Documents real-world challenges (system stability, rate limiting, API adoption) that inform best practices for open research infrastructure.
Limitations and open questions:
- Training data age: Features trained on 2014 data; bot evasion tactics and platform changes likely degrade performance by 2016. Adversarial adaptation is an ongoing arms race.
- Class imbalance and label quality: Training uses manually verified bots from Caverlee's work, but coverage of bot types is unknown—financial-spam bots, purchased followers, and state-sponsored accounts may differ substantially from training distribution.
- Feature erosion: Account metadata and behavioral signals that distinguished bots from humans (e.g., bimodal temporal patterns) may have converged; newer bots mimic human posting patterns more effectively.
- Limited validation: No independent test set with ground truth; 0.95 AUC on cross-validation may not reflect real-world deployment performance where bot strategies evolve continuously.
Follow-ups:
- Online active learning: Incorporate feedback from human reviewers of borderline cases to improve classifier robustness.
- Temporal dynamics: Track how bot scores and feature distributions change over time—do known bots' features degrade?
- Cross-platform generalization: Can features trained on Twitter transfer to Facebook, Instagram, or other platforms with different affordances?
- Explainability: The companion paper Yang et al. (2019) showed users are often confused by raw scores; how should uncertainty and feature contributions be communicated?