DELL: Generating Reactions and Explanations for LLM-Based Misinformation Detection¶
Authors: Herun Wan, Shangbin Feng, Zhaoxuan Tan, Heng Wang, Yulia Tsvetkov, Minnan Luo
Venue: arXiv, 2024 — 2402.10426
Affiliations: Xi'an Jiaotong University; University of Washington; University of Notre Dame
TL;DR¶
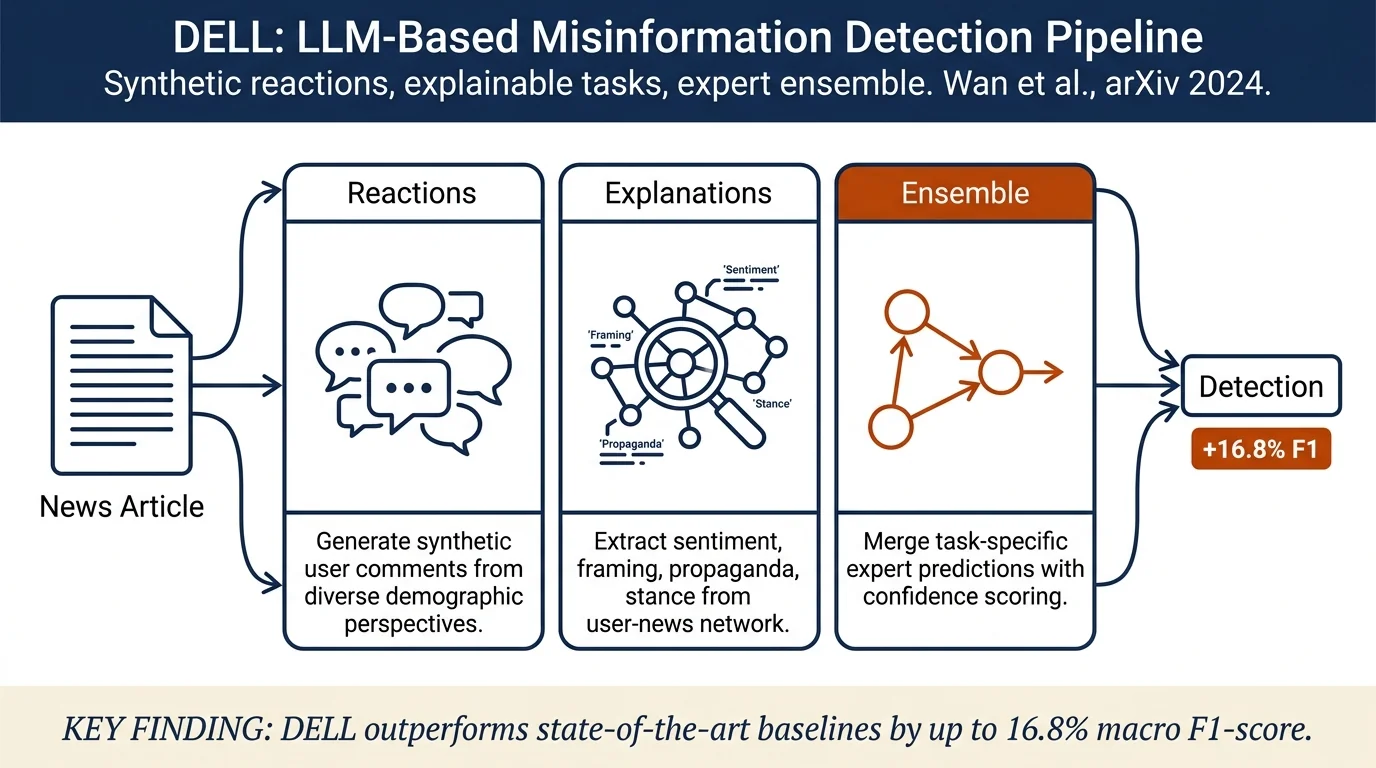
Large language models struggle with factuality and hallucinations in misinformation detection. DELL proposes a three-stage pipeline where LLMs generate synthetic user reactions from diverse perspectives, create explanations for proxy tasks (sentiment, framing, propaganda tactics), and merge predictions from task-specific experts. The approach outperforms state-of-the-art baselines by up to 16.8% in macro F1-score across seven datasets on three misinformation detection tasks.
Contributions¶
- Diverse reaction generation: Use LLMs to synthesize news reactions and comments from different demographic perspectives, creating user-news interaction networks that ground misinformation assessment in public discourse.
- Explainable proxy tasks: Design six LLM-generated explanation tasks (sentiment analysis, framing detection, propaganda tactics, knowledge retrieval, stance detection, response characterization) to refine feature embeddings in user-news networks.
- LLM-based expert ensemble: Propose three strategies to selectively merge predictions from task-specific experts with confidence scoring, improving calibration and predictions.
Method¶
DELL integrates LLMs at three stages:
1. Diverse Reaction Generation - Represent synthetic users as intersections of seven demographic attributes: gender, age, ethnicity, education, family income, political leaning, voter registration. - For each synthetic user and news article, use LLMs to generate comments via three iterative steps: (i) generate an initial comment on the news; (ii) generate a comment on a given comment in a chain; (iii) select which comment to engage with. - Construct user-news interaction networks G = (V, E) where V represents users and articles, E represents engagement.
2. Explainable Proxy Tasks - Six proxy tasks provide LLM-generated explanations to enrich news article and user-comment embeddings: - Sentiment analysis: Classify six basic emotions (anger, surprise, etc.) and provide explanations. - Framing detection: Identify up to five media frames (economic, morality, etc.) with explanations. - Propaganda tactics: Detect propaganda tactics from a taxonomy of 19 tactics. - Knowledge retrieval: Identify entities in articles and retrieve Wikipedia passages as external context. - Stance detection: Evaluate whether text nodes in the network are supportive, neutral, or opposed to one another. - Response characterization: Analyze propagation structure of news and comments. - Use graph neural networks (GNNs) on the user-news network with concatenated embeddings from articles and explanations.
3. LLM-Based Expert Ensemble - Develop three merging strategies to combine predictions from task-specific experts: - Vanilla: Provide news content and expert descriptions; LLM predicts label with probability of each expert. - Confidence: Add confidence scores from expert classifications; LLM weights expert predictions accordingly. - Selective: LLM determines which experts are most relevant for a given article, then selectively incorporates their predictions.
Results¶
Evaluated on three misinformation-related tasks across seven datasets:
Fake news detection: - Pheme: 810 macro F1 (DELL Single) vs. 779 baseline; LLM-mis: 810 vs. 800 - DELL outperforms strongest baseline by 1.46% to 16.8% macro F1
Framing detection: - MFC: 458 vs. 447 baseline; SemEval-23P: 432 vs. 417
Propaganda tactic detection: - Generated: 576 vs. 566 baseline; SemEval-20: 520 vs. 504; SemEval-23P: 386 vs. 362
Generated comments quality: - Human evaluation shows LLM-generated comments match user attributes (Fleiss' Kappa: 0.216) and are relevant to news articles (average Likert: 4.52/5). - Network metrics (edge betweenness, average shortest path, diameter) of generated networks align with real social media networks (Twitter-15, Twitter-16, Pheme).
Robustness: - DELL performance remains stable when gradually removing generated comments (Figure 3), showing benefits from 10% of comments. - Single expert can achieve substantial improvement (6.16% on Pheme) but ensemble merging adds further gains (up to 15.8% improvement).
Model calibration: - DELL achieves lower expected calibration error (ECE: 0.2357) compared to baselines on fake news detection, demonstrating better-calibrated predictions.
Connections¶
- Related to dEFEND: Explainable Fake News Detection via use of explanations for improved detection.
- Extends Rumor Detection on Twitter with Tree-structured Recursive Neural Networks and Hierarchical Propagation Networks for Fake News Detection: Investigation and Exploitation by using LLM-generated interaction networks instead of only real user data.
- Builds on Linguistic-style-aware Neural Networks for Fake News Detection in leveraging linguistic features from diverse perspectives.
- Complements A Survey on Natural Language Processing for Fake News Detection by demonstrating practical integration of LLMs in a multi-stage detection pipeline.
Notes¶
Strengths: - Novel integration of LLMs at multiple stages (synthetic data generation, explanations, expert merging) showing substantial improvements. - Comprehensive evaluation across three distinct misinformation detection tasks and seven datasets demonstrates generalizability. - Thoughtful synthetic user design with demographic diversity; generated networks match real social media statistics. - Human evaluation validates quality of LLM-generated comments; demonstrates model robustness to comment removal and calibration improvements.
Limitations: - Computational cost of iterative LLM inference acknowledged; scaling to real-world volumes of user reactions may be challenging. - Proxy tasks, while helpful, may not fully capture diverse interpretations of news; focus on six specific tasks may miss other useful explanations. - LLM biases in synthetic user generation and comment production not deeply analyzed; potential for bias amplification when diverse perspectives are simulated rather than observed. - Evaluation relies primarily on classification metrics; qualitative analysis of generated reactions limited.