Hierarchical Propagation Networks for Fake News Detection: Investigation and Exploitation¶
Authors: Kai Shu, Deepak Mahudeswaran, Suhang Wang, Huan Liu Venue: AAAI 2019, March 21, 2019 — arXiv:1903.09196
TL;DR¶
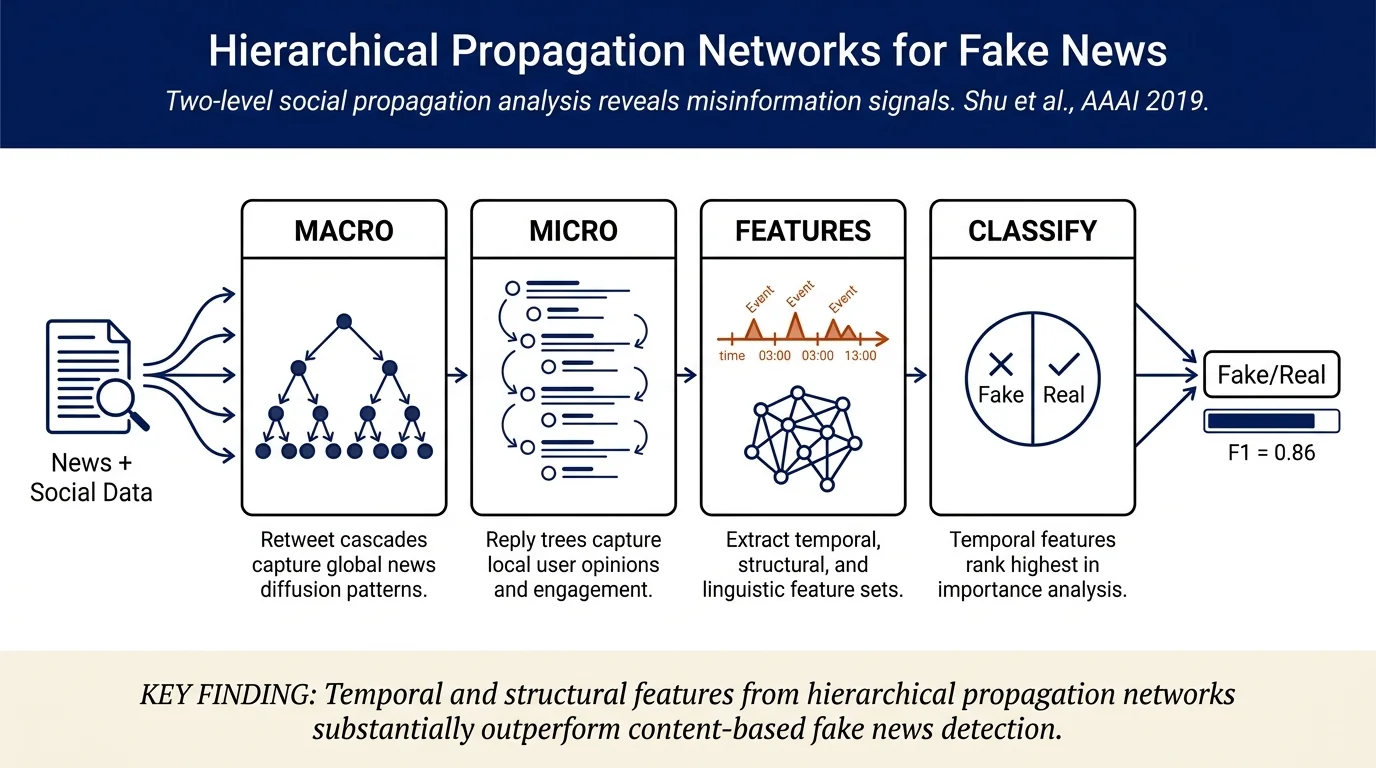
Content-only fake news detection has limited performance because fake news is deliberately crafted to mimic real news. This paper constructs hierarchical propagation networks from both macro-level (tweet/retweet cascade) and micro-level (reply conversation) granularity, extracts structural, temporal, and linguistic features from both levels, and demonstrates that these hierarchical propagation network features (HPNF) significantly outperform prior macro-level-only approaches for fake news detection. Temporal features prove most discriminative, achieving F1 > 0.80 on FakeNewsNet benchmarks.
Contributions¶
- Proposes constructing hierarchical propagation networks at two granularities: macro-level (retweet cascades) capturing global information diffusion, and micro-level (reply trees) capturing local user opinions and discussions.
- Performs the first principled comparative analysis of structural, temporal, and linguistic features of fake and real news propagation at both macro and micro levels across PolitiFact and GossipCop datasets.
- Demonstrates through statistical t-tests that macro-level features (tree depth S1, number of nodes S2, cascades with retweets S7) and temporal features (T2, T3, T4, T7, T8 from macro; T9, T10, T11 from micro) are statistically significantly different between fake and real news.
- Shows that hierarchical propagation network features achieve F1 0.843 on PolitiFact and F1 0.862 on GossipCop with Random Forest, outperforming content-based baselines (RST, LIWC) and prior propagation-based approaches (STFN).
- Validates feature robustness across multiple learning algorithms (GNB, DT, LR, RF); demonstrates that temporal and structural features substantially outperform linguistic features in importance.
Method¶
Hierarchical Propagation Network Construction.
Macro-level: Nodes represent tweets and retweets; edges represent retweet relationships. Since the official Twitter API does not explicitly indicate whether a retweet is of an original tweet or a retweet, the authors use social network inference: if the timestamp of a user's retweet is greater than the timestamp of a user friend's retweet, the retweet is likely from that friend. Otherwise, it is treated as a retweet of the original tweet.
Micro-level: Nodes represent replies to tweets; edges represent reply relationships. If a user replies to an original tweet, an edge connects the tweet to the reply. If a user replies to another user's reply, a conversation chain is formed.
Feature Extraction.
Macro-level structural features (S1–S9): Tree depth, number of nodes, maximum outdegree, number of cascades, depth of maximum-outdegree node, number/fraction of cascades with retweets, number/fraction of bot users retweeting.
Macro-level temporal features (T1–T8): Average time between adjacent retweets, lifespan of spread (first to last retweet), time to influential node, interval between cascade origins, lifespan of deepest cascade, retweet frequency in deepest cascade, posting interval of cascade origins, time to first retweet.
Micro-level structural features (S10–S14): Tree depth, number of nodes (replies), maximum outdegree, number of cascades with replies, fraction of cascades with replies.
Micro-level temporal features (T9–T13): Average time between adjacent replies, time to first reply, conversation lifespan, reply frequency in deepest cascade, lifespan of deepest conversation thread.
Micro-level linguistic features (L1–L5): Sentiment ratio (positive to negative replies), average sentiment, sentiment of first-level replies, average sentiment in deepest cascade, sentiment of first-level reply in deepest cascade. Sentiment is computed using VADER.
Results¶
Feature Effectiveness. HPNF (hierarchical propagation network features) consistently outperforms content-based methods (RST: F1 0.785 on PolitiFact, 0.594 on GossipCop; LIWC: F1 0.822, 0.698) and prior propagation-based method STFN (F1 0.702, 0.791). HPNF alone achieves F1 0.843 on PolitiFact and 0.862 on GossipCop. Combining HPNF with content features (RST+HPNF, LIWC+HPNF, STFN+HPNF) yields further improvements (0.875, 0.871, 0.864 on PolitiFact), showing orthogonal information.
Robustness Across Algorithms. Random Forest performs best, but performance differences across GNB, DT, LR, and RF are modest (e.g., PolitiFact F1 ranges 0.82–0.84; GossipCop 0.85–0.86), demonstrating that hierarchical features are sufficiently informative that classifier choice is not critical.
Feature Importance Analysis (Gini impurity, Random Forest): - PolitiFact: Temporal features dominate; T11 (micro-level conversation lifespan) is most important; T2 (macro-level lifespan) is second. Structural features rank lower; maximum outdegree S3 is highest among structural. - GossipCop: Macro-level structural features dominate; S7 (fraction of cascades with retweets) is most important; S4 (number of cascades) is second. Temporal features (T4: interval between origin tweets) rank lower than on PolitiFact.
Macro vs. Micro Comparison. On PolitiFact, micro-level features alone (F1 0.835) outperform macro-level alone (0.802); on GossipCop, macro-level features (0.854) slightly outperform micro-level (0.843). Combination of both (F1 0.843 and 0.862) consistently outperforms either alone, confirming complementarity.
Structural vs. Temporal vs. Linguistic. Temporal features substantially outperform structural (0.821 vs. 0.676 F1 on PolitiFact; 0.826 vs. 0.826 on GossipCop) and linguistic features (0.821 vs. 0.665 on PolitiFact; 0.826 vs. 0.538 on GossipCop). All three combined yield best performance.
Key Observations¶
- Fake news spreads differently: Fake news exhibits deeper retweet cascades (higher S1), more cascades with retweets (higher S7), and higher bot participation than real news.
- Temporal patterns are diagnostic: Fake news has shorter lifespans (lower T2), reaches influential amplifiers faster (lower T3), and originates in shorter time windows (lower T4), consistent with prior diffusion research.
- Conversation signals differ: Fake news generates deeper reply threads (higher S10) and higher fraction of cascades with replies (higher S14), suggesting controversial or polarizing nature drives engagement.
- Sentiment asymmetry: Fake news receives more negative sentiment on average (lower L2, L3) than real news, though linguistic features alone are weak discriminators.
Connections¶
- Builds directly on FakeNewsNet dataset and benchmark from Shu et al. (2018), which provides the social context, dynamic information, and fact-checking labels.
- Extends propagation-based detection by analyzing both macro and micro levels; prior work (Vosoughi, Roy, Aral 2018) focused primarily on macro-level temporal dynamics.
- Complements Shu et al. (2019) — User Profiles, which uses explicit demographic/behavioral user features; HPNF instead exploits implicit structural and temporal signals.
- Related to dEFEND (Shu et al. 2019), which uses neural hierarchical attention on news content and user comments; HPNF uses hand-crafted propagation features.
- Directly informs the design of social-context-based detection approaches.
Notes¶
The paper makes a strong case for temporal feature importance, but the findings are dataset-dependent: on PolitiFact, temporal features dominate (with T11 far ahead), while on GossipCop, macro-level structural features are more important (S7 most important). This suggests dataset-specific characteristics of fake news propagation; caution is warranted when applying learned feature weights to new domains.
Bot detection via Botometer is used to filter obvious automated accounts before extracting features, but the approach does not attempt to identify sophisticated or hard-to-detect bot accounts. The bot fraction itself (S8, S9) is treated as a feature, which is useful but underutilizes the richness of bot behavior analysis.
The linguistic analysis (sentiment) is simplistic: only sentiment polarity is used; stance toward the news claim, semantic content of comments, and sarcasm are not modeled. The paper acknowledges leaving stance analysis as future work due to limited tool availability in the datasets at the time.
Comparison with STFN (Vosoughi et al. 2018) shows HPNF's micro-level features add substantial value, but both use hand-crafted features. Deep learning approaches (RVNNs, GNNs on propagation graphs) emerged in parallel and represent an orthogonal direction for feature learning.