Linguistic-style-aware Neural Networks for Fake News Detection¶
Authors: Xinyi Zhou, Jiayu Li, Qinzhou Li, Reza Zafarani Venue: arXiv preprint, 2023 — arXiv:2301.02792
TL;DR¶
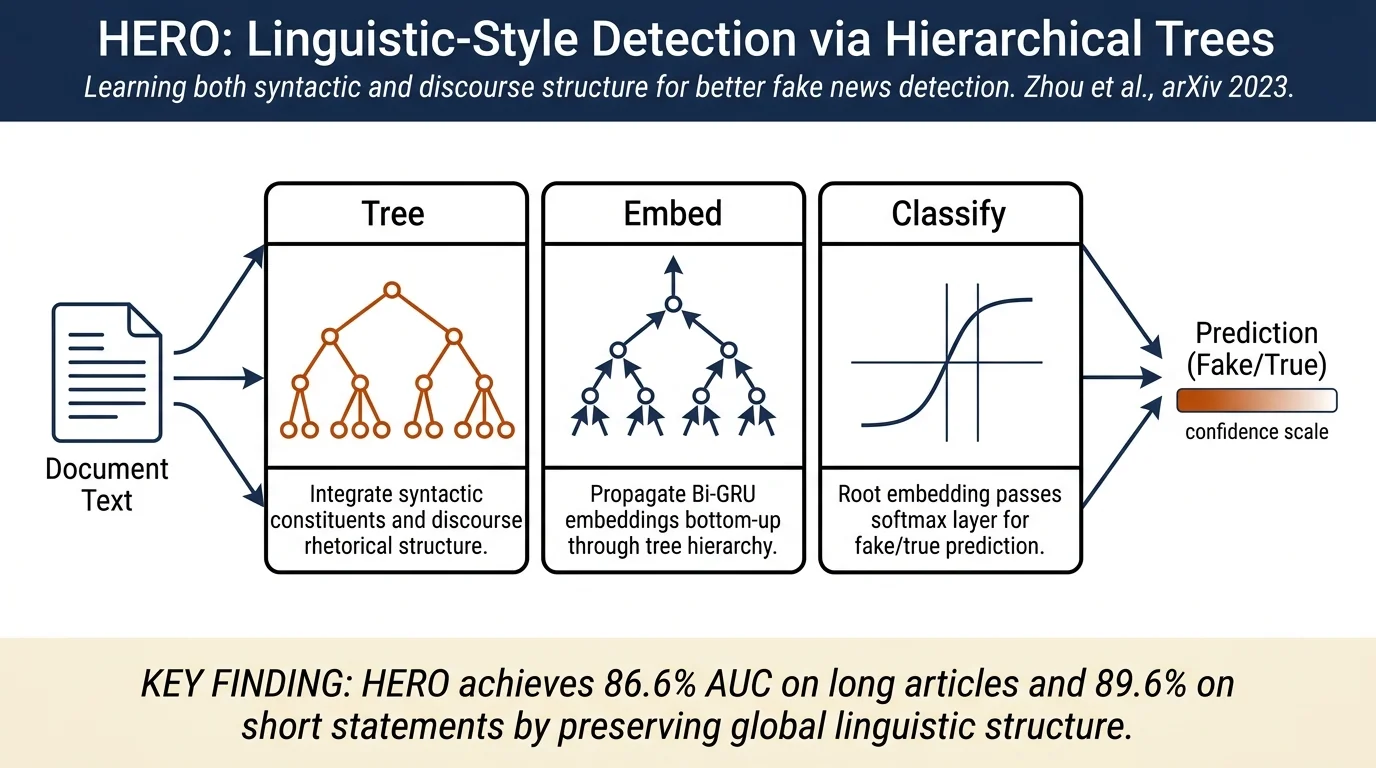
HERO (Hierarchical Recursive Neural Network) detects fake news by learning the linguistic style encoded in hierarchical linguistic trees — structures that jointly capture syntactic constituency and rhetorical discourse organization from word to document. Unlike prior handcrafted approaches that extract node-level statistics (word frequencies, POS counts, RST relation counts) independently, HERO propagates Bi-GRU embeddings bottom-up through the full tree, preserving the global structure that prior methods discarded. Attribute-specific HERO achieves 0.866 AUC on Recovery (long articles) and 0.896 AUC on MM-COVID (short statements), outperforming the best prior neural baseline (HAN) by 2–5% AUC.
Contributions¶
- First method to construct hierarchical linguistic trees that integrate constituency-level (syntactic, within-EDU) and discourse-level (RST, across-EDU) structure into a single unified tree per document.
- HERO: a hierarchical recursive neural network whose topology adapts to each document's tree, aggregating child embeddings with a Bi-GRU at every node from leaves to root.
- Three HERO variants — Unified (shared Bi-GRU parameters), Level-specific (separate syntax/discourse parameters), Attribute-specific (separate parameters per POS tag or RR type) — with attribute-specific performing best.
- Quantitative characterization of fake-vs-true linguistic differences: fake news shows more child nodes per parent, fewer plural nouns (NNS), more prepositions (IN) and determiners (DT), and syntactic trees that are larger, broader, and deeper.
Method¶
Tree construction (top-down): Stanford CoreNLP segments the document into elementary discourse units (EDUs). A modified transition-based system derives the discourse (rhetorical) structure over EDUs — first computing span and nuclearity to obtain a skeleton tree, then using level-specific SVM classifiers to predict the specific rhetorical relationship (elaboration, contrast, etc.) at each internal node. A self-attentive encoder + chart decoder constituency parser (Kitaev & Klein, 2018) then annotates each EDU's internal syntactic structure. The result is a tree where discourse-level internal nodes carry RR labels, syntactic-level internal nodes carry POS labels, and leaves are words.
Feature extraction (bottom-up): HERO processes the tree from leaves to root. At each parent node \(p\), a Bi-GRU runs over the (ordered) child embeddings; the mean of all hidden states becomes \(p\)'s embedding. This preserves local sequentiality within each parent–children unit while the recursive application up the tree captures global structure. Bi-GRU outperforms multi-head self-attention (tested with 10 heads) by at least 1% AUC — the authors attribute this to the short sequence lengths at each node (bounded by EDU length, not document length). In Attribute-specific HERO, each distinct POS tag and RR type has its own Bi-GRU weight matrix; in Level-specific, all syntactic nodes share one and all discourse nodes share another.
Classification: The root embedding is passed through a softmax layer. Word embeddings are GloVe 100d. Training uses Adam at lr = 0.0001, cross-entropy loss, up to 50 epochs, 70/10/20 train/val/test split.
Results¶
On Recovery (2,029 labeled COVID-19 articles; long-form, avg 841 words):
| Model | MAF1 | MIF1 | AUC |
|---|---|---|---|
| HCLF (best classifier) | 0.752 | 0.801 | 0.746 |
| DRNN | 0.711 | 0.778 | 0.698 |
| Transformer | 0.774 | 0.793 | 0.810 |
| EANN | 0.811 | 0.864 | 0.795 |
| HAN | 0.847 | 0.869 | 0.844 |
| Text-GCN | 0.841 | 0.869 | 0.835 |
| HERO (attr-specific) | 0.850 | 0.869 | 0.866 |
On MM-COVID (3,536 labeled short statements; avg 16 words):
| Model | MAF1 | MIF1 | AUC |
|---|---|---|---|
| HCLF | 0.566 | 0.624 | 0.577 |
| Transformer | 0.804 | 0.809 | 0.806 |
| Text-GCN | 0.826 | 0.836 | 0.817 |
| DRNN | 0.845 | 0.846 | 0.848 |
| HAN | 0.840 | 0.856 | 0.846 |
| EANN | 0.825 | 0.926 | 0.833 |
| HERO (attr-specific) | 0.894 | 0.896 | 0.896 |
Ablation: removing the discourse level drops AUC by 1–3% on Recovery and is near-zero on MM-COVID (short statements have avg 2 EDUs, so discourse trees are near-trivial). Removing the syntactic level drops AUC by 7–9% on Recovery and >10% on MM-COVID. Both levels matter; syntax dominates for short text.
Connections¶
- Uses ReCOVery as one of two evaluation datasets; see Zhou et al. (2020) — ReCOVery for dataset construction details and HCLF/RST baseline results on the same corpus.
- SAFE (Zhou et al., 2020) also evaluates on ReCOVery but uses image+text; HERO achieves higher AUC on the same task using text alone, highlighting the strength of hierarchical linguistic structure.
- Belongs to the content-based detection paradigm — requires only article text, no social context, applicable immediately at publication time.
- The HCLF baseline draws from feature engineering: bag-of-words, POS frequencies, RST structure counts, and production rules — exactly the node-level statistics that HERO replaces with global tree aggregation.
- The linguistic style detection topic collects all approaches exploiting writing style as a detection signal; HERO is the most structurally rich example in this wiki.
Notes¶
The novelty claim — "first work offering the hierarchical linguistic tree and the neural network preserving the tree information" — is specific and credible: while DRNN (Ji & Smith, 2017) traverses RST trees and Karimi & Tang (2019) use hierarchical discourse structure, neither integrates constituency parsing inside each EDU into a single recursive architecture. The attribute-specific variant's consistent superiority over level-specific implies that fine-grained POS/RR identity (e.g., distinguishing NNS from IN) carries more discriminative signal than the coarse syntactic-vs-discourse level grouping. The large HCLF margin (12–30% AUC) confirms that global structure, not just node statistics, drives HERO's gains. Code and data: https://github.com/Code4Graph/HERO.