Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks¶
Authors: Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela
Venue: ICLR 2021 — arXiv:2005.11401
TL;DR¶
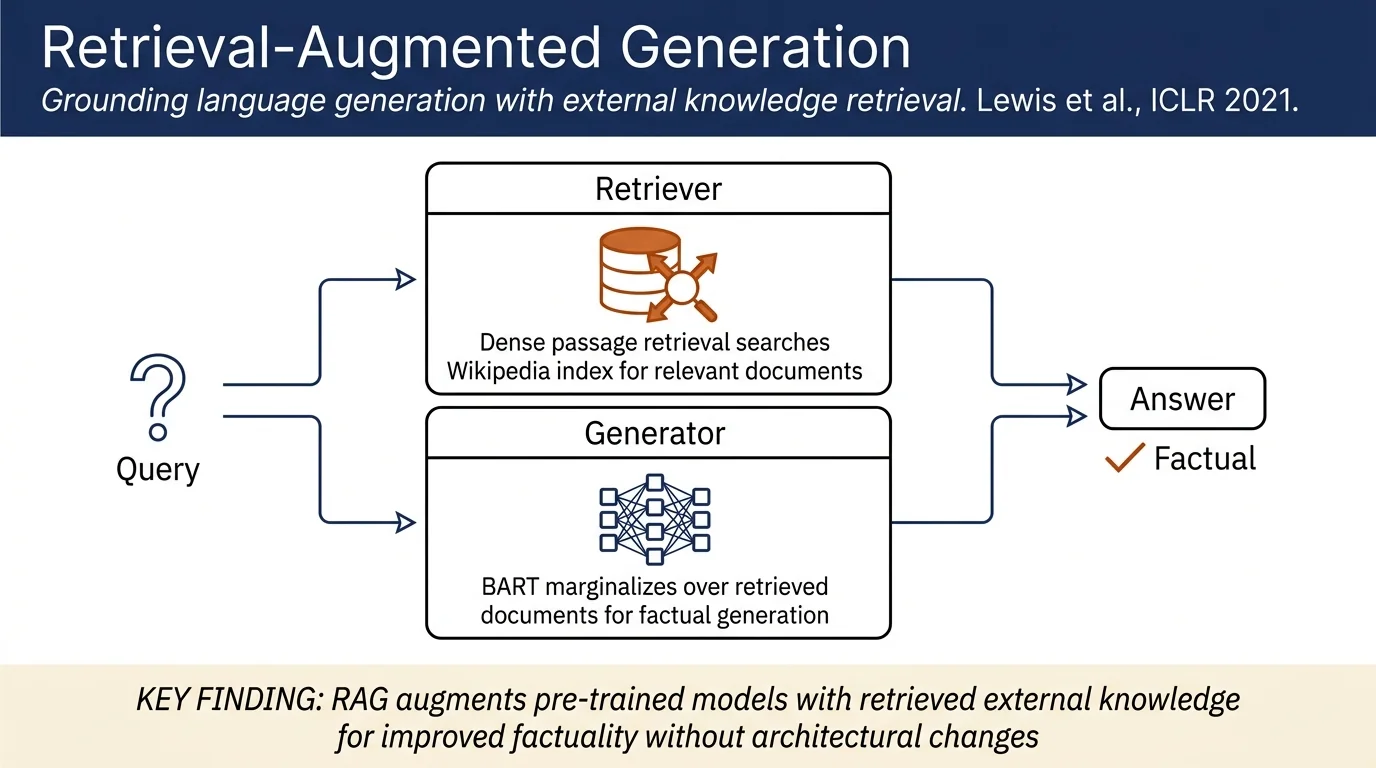
This work proposes RAG (Retrieval-Augmented Generation), a hybrid architecture that augments pre-trained language models with a non-parametric memory component. The model retrieves relevant documents from Wikipedia at generation time and uses them to ground the generation process, achieving state-of-the-art results on multiple knowledge-intensive NLP tasks without task-specific retraining or architecture changes.
Contributions¶
- Hybrid architecture combining parametric and non-parametric memory: parametric memory is a pre-trained seq2seq model (BART); non-parametric memory is a dense vector index of Wikipedia
- Two formulations: RAG-Sequence uses the same retrieved document for the entire sequence, while RAG-Token selects different documents for each output token
- Unified framework for knowledge-intensive tasks: evaluated on open-domain QA, abstractive QA, Jeopardy question generation, and fact verification
- Knowledge updatability: the retrieval index can be swapped at test time without retraining, enabling the model to adapt to new facts
- End-to-end training: both retriever and generator components are jointly fine-tuned on task-specific data
Method¶
RAG models use Maximum Inner Product Search (MIPS) to efficiently retrieve the top-K documents using a query encoder and document index. The retrieved documents are then treated as latent variables that condition the generation process.
RAG-Sequence: The top-K retrieved documents are scored jointly, and the model marginalizes over their probabilities to compute the generation likelihood:
The retriever uses Dense Passage Retrieval (DPR) with a BERT-based bi-encoder. The generator is initialized from BART.
RAG-Token: For each generated token, a different set of documents can be retrieved and marginalized:
This formulation allows the model to leverage different evidence for different output tokens.
Results¶
- Open-Domain QA: RAG-Token achieves 44.1% on Natural Questions, outperforming REALM (41.5%) and the retrieval-only DPR baseline (41.3%)
- Abstractive QA (MS-MARCO NLG): RAG-Sequence outperforms BART by 2.6 BLEU points
- Jeopardy Question Generation: RAG-Token surpasses BART in factuality (42.7% vs 7.1% of evaluators preferring it)
- Fact Verification (FEVER): RAG achieves 4.3% within state-of-the-art on 3-way classification
- Knowledge grounding: RAG can generate correct answers even when the answer is not in any retrieved document (11.8% accuracy for NQ), showing it leverages both parametric and non-parametric memory
Generation from RAG models is more specific, diverse, and factually accurate than parametric-only BART baselines. The model can also be updated at test time by replacing the retrieval index (e.g., switching from December 2016 to 2018 world leader data, achieving 70% accuracy with the newer index).
Connections¶
- Related to Claim Verification via the fact verification evaluation on FEVER
- Applied to Question Answering Systems tasks across multiple datasets
- Builds on Information Retrieval techniques for the retrieval component
- Contrasts with purely parametric approaches by incorporating external knowledge sources
- Similar spirit to Misinformation Has High Perplexity in using knowledge to ground NLP systems
Notes¶
This is a highly influential paper that introduced RAG and has spawned numerous follow-up works. The key insight—that pre-trained models can be augmented with retrieval at generation time without task-specific architectures—has become foundational in modern NLP. The factuality improvements are particularly relevant for applications like fact-checking and misinformation detection where grounding in evidence is critical. The work demonstrates that both parametric and non-parametric knowledge are useful, and that jointly training both components is effective.