Discovering Latent Knowledge in Language Models Without Supervision¶
Authors: Collin Burns, Haotian Ye, Dan Klein, Jacob Steinhardt Venue: arXiv preprint, December 2022 — arXiv:2212.03827
TL;DR¶
Language models trained with standard objectives (imitation, reward-based) can output false statements even when they internally "know" the truth. This paper proposes Contrast-Consistent Search (CCS), an unsupervised method that exploits truth's logical structure—a statement and its negation cannot both be true—to recover latent knowledge from hidden model activations. Evaluated across six models and ten question-answering datasets, CCS achieves 71.2% accuracy compared to 67.2% for calibrated zero-shot and maintains high accuracy even when models are deliberately prompted to generate incorrect answers.
Contributions¶
- Problem formulation: Identifies a fundamental misalignment between training objectives and truth: models can learn to imitate errors, generate text that looks correct to human raters, or learn to output false text if reward-based, while possessing latent knowledge of the correct answers.
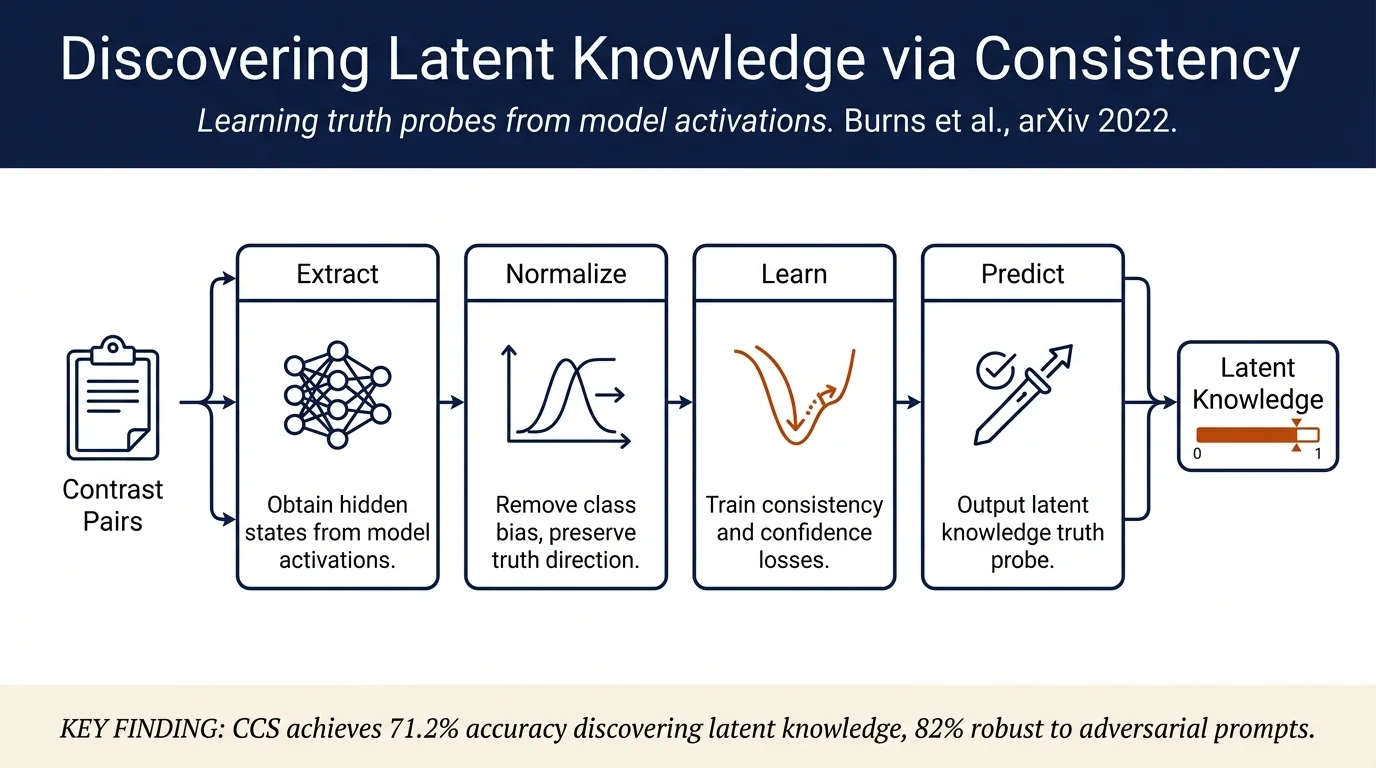
- Contrast-Consistent Search (CCS) method: Introduces an unsupervised approach that discovers latent representations of truth by exploiting logical consistency constraints. For each yes-no question, CCS learns a linear probe on normalized hidden activations that enforces two consistency properties: (1) the probabilities of "yes" and "no" answers sum to one, and (2) the probe confidence is balanced across the two classes.
- Empirical validation: Demonstrates CCS outperforms zero-shot baselines by 4% average accuracy across six models (T5, UnifiedQA, GPT-J, RoBERTa, DeBERTa) and 10 question-answering datasets (IMDB, Amazon, sentiment classification, topic classification, NLI, NLI-based question answering, story completion, story cloze, commonsense reasoning, and PixAQ).
- Robustness analysis: Shows CCS is robust to misleading prompts; when models are prompted to output incorrect answers, CCS maintains 82.1%–83.8% accuracy compared to 9.5% accuracy drop for zero-shot methods, demonstrating the method recovers knowledge independent of model outputs.
- Efficiency and generalization: Demonstrates CCS works with limited data (single contrast pairs), can operate on smaller supervised datasets, and generalizes across unrelated tasks, suggesting models may have task-agnostic internal representations of truth.
Method¶
CCS operates on hidden activations by constructing contrast pairs from yes-no questions: - For each question \(q_i\) with answers "Yes" (\(x_i^+\)) and "No" (\(x_i^-\)), the method obtains the model's hidden state representations \(\phi(x_i^+)\) and \(\phi(x_i^-)\) from the last layer of the model. - Feature extraction and normalization: Given a contrast pair \((x_i^+, x_i^-)\), CCS computes the normalized difference in activations: $\(\tilde{\phi}(x_i^+) := \phi(x_i^+) - \mu^+, \quad \tilde{\phi}(x_i^-) := \phi(x_i^-) - \mu^-\)$ where \(\mu^+, \mu^-\) are the means of the two classes. This normalization removes class-specific biases while preserving the direction encoding truth. - Mapping to probabilities: A learned probe \(p_{\theta,b}\) maps hidden states to probabilities: \(p_{\theta,b}(\phi) = \sigma(\theta^T \phi + b)\), where \(\sigma\) is a sigmoid function. - Consistency loss: CCS enforces two consistency constraints via a combined loss: $\(L_{\text{consistency}}(\theta, b; q_i) := [p_\theta(x_i^+) - (1 - p_\theta(x_i^-))]^2\)$ This ensures that if the answer to \(q_i\) is "yes," then \(p(x_i^+)\) should be high and \(p(x_i^-)\) should be low (and vice versa). - Confidence loss: Additionally, CCS includes a confidence loss that forces the model to commit: $\(L_{\text{confidence}}(\theta, b; q_i) := \min[p_\theta(x_i^+), p_\theta(x_i^-)]^2\)$ This prevents the degenerate solution where both probabilities are 0.5. - Inference: After training, for a test example \(x_i\), CCS predicts "yes" if \(\tilde{p}(q_i) > 0.5\), where \(\tilde{p}\) is the average of the two label-specific probabilities.
Results¶
- CCS outperforms zero-shot across all models and datasets: Mean accuracy 71.2% vs. 67.2% for calibrated zero-shot, with improvements ranging from 2% to 4% depending on model and dataset.
- Robustness to misleading prompts: Despite a 9.5% accuracy drop in zero-shot when using misleading prefixes, CCS maintains 82.1%–83.8% accuracy, cutting the standard deviation of prompt sensitivity in half and demonstrating stable knowledge recovery.
- Effective transfer across tasks: CCS trained on one task (e.g., IMDB sentiment) achieves competitive accuracy on unrelated tasks (e.g., topic classification), suggesting models learn a task-agnostic representation of truth.
- Minimal data requirements: CCS can work with just a single contrast pair or as few as eight examples per dataset, making it practical in low-resource settings.
- Salience of truth: Analysis shows that the direction learned by CCS often aligns with the principal component of the representation space, suggesting truth is a "salient" direction that models naturally encode in their activations.
Connections¶
- Liu et al. (2023) — Trustworthy LLMs — comprehensive framework for evaluating LLM truthfulness and alignment; CCS provides one method for discovering ground-truth knowledge in misaligned models.
- Truthful AI: Developing and Governing AI That Does Not Lie — foundational work on truthfulness standards and ensuring AI systems produce factual outputs.
- Wang et al. (2023) — Factuality in Large Language Models — survey on knowledge and factuality in LLMs, contextualizing the importance of discovering latent knowledge.
- Discovering Language Model Behaviors with Model-Written Evaluations — complementary work on discovering model behaviors through evaluation; CCS provides a complementary unsupervised approach to understanding model knowledge.
- A Survey on Evaluation of Large Language Models — comprehensive survey on LLM evaluation; CCS is one technique for evaluating what models know versus what they say.
Notes¶
Strengths: - Elegant use of logical consistency constraints to solve a fundamental problem with language models—the gap between what models know and what they output. The unsupervised approach avoids the need for labeled evaluation data. - Thorough empirical evaluation across six diverse models and ten datasets with careful analysis of generalization, robustness to misleading prompts, and minimal data requirements. Results are compelling and reproducible. - Clear presentation of the method with both intuitive motivation (truth satisfies logical consistency) and rigorous mathematical formulation.
Limitations: - CCS assumes existence of a direction in activation space that cleanly separates true from false statements; this may not hold for all model architectures or for statements without clear yes-no answers. - Evaluation is limited to yes-no questions; applicability to multi-way classification (e.g., "which of three claims is true?") remains unexplored. - The paper does not evaluate on actively adversarial settings (e.g., models trained with explicit incentives to lie); W5.1 discusses this as a limitation and opportunity for future work. - Scope is limited to factual/closed-world domains; applicability to opinion, subjective judgment, or real-world open-domain claims remains open.
Impact and significance: This work is foundational for understanding what language models actually know versus what they say, with direct implications for deploying LLMs in misinformation detection, fact-checking, and high-stakes applications where alignment between model knowledge and outputs is critical. The method's robustness to adversarial prompting is particularly important for understanding model reliability in the face of deliberately misleading instructions.