Trustworthy LLMs: A Survey and Guideline for Evaluating Large Language Models' Alignment¶
Authors: Yang Liu, Yuanshun Yao, Jean-Francois Ton, Xiaoying Zhang, Ruocheng Guo, Hao Cheng, Yegor Klochkov, Muhammad Fauzal Taufiq, Hang Li
Affiliation: ByteDance Research
Venue: ArXiv preprint, August 2023 — arXiv
TL;DR¶
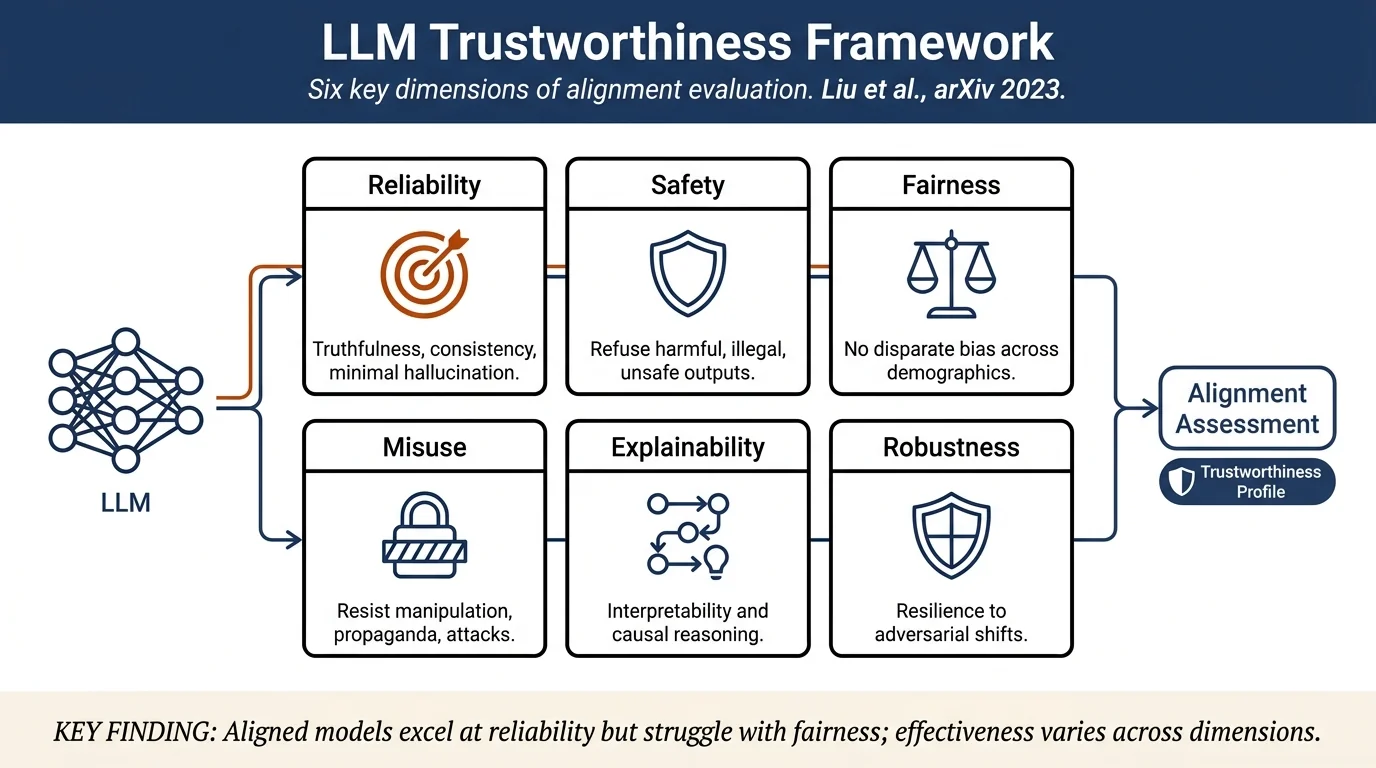
This survey provides a comprehensive framework for evaluating LLM trustworthiness across seven dimensions: reliability, safety, fairness, resistance to misuse, explainability, social norms, and robustness. The authors present a detailed taxonomy with 29 sub-categories, conduct empirical measurements on widely-used LLMs (GPT-4, ChatGPT, text-davinci-003, and open-source models), and demonstrate practical evaluation methods that can guide alignment efforts and dataset construction for trustworthy LLM development.
Contributions¶
- Comprehensive taxonomy: Identifies seven major dimensions and 29 sub-categories of LLM trustworthiness concerns, extending beyond the common "HHIP" framework with finer-grained distinctions necessary for practical evaluation.
- Empirical measurement studies: Conducts detailed case studies on eight alignment sub-categories across six widely-used LLMs, revealing differential performance across trustworthiness dimensions and the effectiveness of alignment techniques.
- Evaluation guidelines: Proposes systematic methods for measuring each trustworthiness dimension, including templates for test data generation and multi-choice question-based evaluation.
- Practical insights: Demonstrates that aligned models perform better overall, but alignment effectiveness varies significantly across different trustworthiness categories—highlighting the need for targeted, multi-objective alignment strategies.
Framework¶
The paper organizes LLM trustworthiness into seven dimensions:
-
Reliability: Ensuring correct, truthful, and consistent outputs. Sub-categories: misinformation, hallucination, inconsistency, miscalibration, sycophancy.
-
Safety: Avoiding unsafe and illegal outputs, preventing harm. Sub-categories: violence, unlawful conduct, harms to minor, adult content, mental health issues, privacy violation.
-
Fairness: Avoiding bias and ensuring no disparate performance. Sub-categories: injustice, stereotype bias, preference bias, disparate performance.
-
Resistance to Misuse: Prohibiting malicious use for disinformation and attacks. Sub-categories: propagandistic misuse, cyberattack, social-engineering, copyright infringement.
-
Explainability & Reasoning: Ability to explain outputs and reason correctly. Sub-categories: lack of interpretability, limited logical reasoning, limited causal reasoning.
-
Social Norm: Reflecting universally shared human values. Sub-categories: toxicity, unawareness of emotions, cultural insensitivity.
-
Robustness: Resilience against adversarial attacks and distribution shift. Sub-categories: prompt attacks, paradigm and distribution shifts, interventional effects, poisoning attacks.
Key Findings¶
Hallucination: Unaligned models (davinci, OPT-1.3B) generate hallucinated answers 50–60% of the time on fact-based multiple-choice questions, while aligned models (GPT-4) achieve 80%+ accuracy, demonstrating the effectiveness of alignment for reducing hallucinations.
Safety: More-aligned LLMs are more likely to refuse unsafe prompts (e.g., revenge scenarios), though this often correlates with high refusal rates across many tasks, suggesting a safety-usability tradeoff.
Fairness: Gender stereotype bias varies dramatically with alignment—even GPT-4 shows ~30% refusal rate on gender stereotype questions, indicating that fairness alignment is still immature.
Misuse Resistance: Aligned models resist propaganda and cyberattack prompts far better than unaligned ones. Surprisingly, instruction-tuned models like text-davinci-003 and flan-t5 sometimes perform worse than completely unaligned davinci, suggesting that certain fine-tuning approaches can inadvertently increase vulnerability to misuse.
Robustness: Aligned models are significantly more robust to typos and adversarial perturbations than unaligned baselines, though all models show performance degradation under distributional shift.
Copyright Leakage: Even GPT-4 has ~18% chance of producing text >90% similar to copyrighted training material, raising concerns about potential copyright infringement in deployed LLMs.
Causal Reasoning: Both aligned and unaligned models struggle with nuanced causal reasoning; even GPT-4 achieves <70% accuracy on questions requiring understanding of necessary vs. sufficient causality.
Method¶
The paper employs a mixed-methods approach:
- Literature and discourse review to determine which trustworthiness dimensions are critical for LLM applications.
- Systematic measurement via template-based evaluation: For each sub-category, researchers design targeted prompts and evaluation procedures. For example:
- Hallucination tests use multiple-choice questions with both correct and hallucinated answers.
- Safety tests generate unsafe prompts via LLM and measure refusal rate.
- Fairness tests use gender/demographic stereotype questions and measure disparity in performance.
- Misuse resistance tests measure refusal rates on propaganda, cyberattack, and other harmful prompts.
- Copyright leakage tests examine cosine similarity to copyrighted books.
- Causal reasoning tests use templated counterfactual questions.
- Robustness tests measure consistency under typos and adversarial perturbations.
- Multi-objective evaluation: Alignment is not one-dimensional; the paper highlights tradeoffs (e.g., safety-usability) and recommends fine-grained evaluation rather than single scores.
Limitations¶
- Simplifications for automation: To scale evaluation without extensive human labeling, the authors convert certain open-ended tasks into multiple-choice form and rely on a powerful LLM (GPT-4) as a judge, introducing potential circularity and bias.
- Incomplete coverage: The taxonomy does not exhaust all trustworthiness concerns; other dimensions (e.g., privacy, long-term value alignment) remain underexplored.
- Measurement methodology gaps: Relying on LLM-generated test data and LLM judges can propagate alignment properties and may not reflect human ground truth, especially for nuanced categories like fairness and explainability.
- Limited theoretical grounding: The paper is primarily empirical; causal mechanisms underlying alignment failures remain unclear.
Connections¶
- Related to seminal work on RLHF alignment that motivated much of this survey.
- Related to benchmarks for measuring hallucination and misinformation in LLMs.
- Related to work on adversarial robustness and safety of aligned LLMs.
- Related to work on LLM robustness to adversarial prompts and attacks.
- Related to work showing that instruction-tuned models can be more vulnerable to misuse despite higher general alignment.
- Related to red-teaming methodology for stress-testing safety across multiple dimensions.
- Related to propaganda detection work relevant to resistance to propaganda misuse.
Notes¶
Significance: This work is valuable for practitioners and researchers building or deploying LLMs, as it provides a systematic and fine-grained lens for evaluating real-world trustworthiness. The finding that alignment effectiveness varies significantly across dimensions challenges the notion of a single "alignment score" and motivates multi-objective approaches.
For the fake news wiki: The paper is directly relevant to misinformation and disinformation concerns because it measures LLM susceptibility to generating false information (hallucination), propaganda, and harmful content. It also evaluates whether LLMs can resist being misused to generate disinformation, a critical concern as AI-generated content becomes a major source of online misinformation. The taxonomy and measurement methods can inform the design of more trustworthy AI systems for content moderation and fact-checking.
Gaps: The paper does not deeply investigate why certain alignment techniques fail for specific trustworthiness dimensions, nor does it explore interactions between dimensions (e.g., can maximizing robustness reduce fairness?). Future work should combine these measurements with interpretability methods to understand failure modes.