SAFE: Similarity-Aware Multi-Modal Fake News Detection¶
Authors: Xinyi Zhou, Jindi Wu, Reza Zafarani (Zhou and Wu contributed equally) Venue: arXiv:2003.04981 [cs.CL], February 2020
TL;DR¶
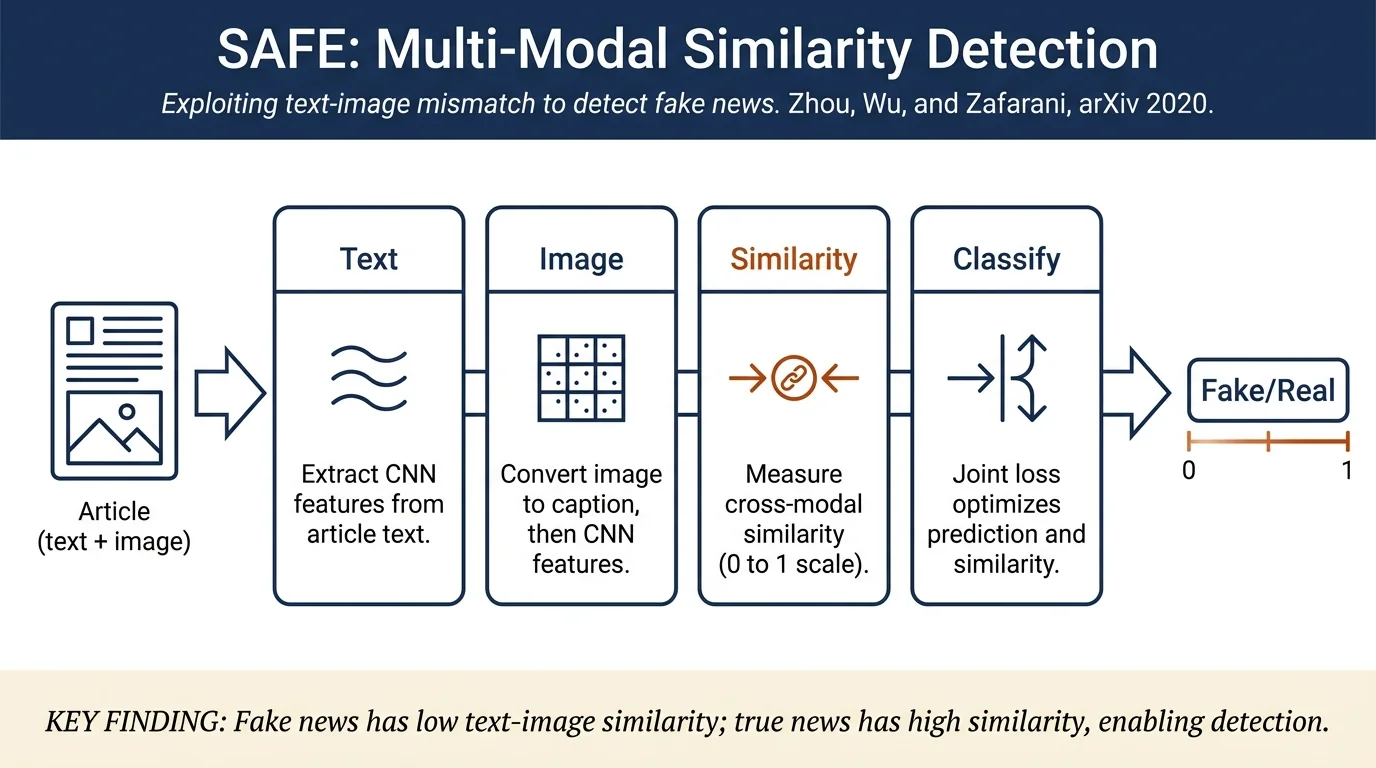
Fake news articles frequently pair misleading textual claims with irrelevant or manipulative images, creating a detectable gap between the two modalities. SAFE addresses this by extracting separate neural representations of a news article's text and images — using the same Text-CNN architecture applied to an image2sentence embedding for visual content — then measuring their cross-modal similarity with a modified cosine metric; the final classifier jointly optimizes a modal-independent prediction loss and a similarity-based loss, outperforming text-only, image-only, and prior multi-modal baselines on both PolitiFact (F₁ 0.896) and GossipCop (F₁ 0.895) partitions of FakeNewsNet.
Contributions¶
- First method to explicitly model the relationship (similarity) between news textual and visual information as a signal for fake news detection, distinct from simply concatenating multi-modal features.
- SAFE framework with three modules: (1) multi-modal feature extraction via Text-CNN on text and image2sentence embeddings, (2) modal-independent fake news prediction, and (3) cross-modal similarity extraction, jointly optimized with loss ℒ = αℒ_p + βℒ_s.
- Empirical ablation showing that cross-modal similarity (SAFE\S → SAFE) consistently improves over concatenated multi-modal features alone, and that textual information contributes more than visual (SAFE\V > SAFE\T).
- Case studies demonstrating fake news articles receive low similarity scores (s ≈ 0.001–0.044) while true news articles receive high scores (s ≈ 0.966–0.983).
Method¶
Problem formulation. A news article A = {T, V} consists of textual content T and visual content V. The goal is to predict ŷ ∈ {0, 1} (real vs. fake) by learning d-dimensional representations t = ℳ_t(T, θ_t) and v = ℳ_v(V, θ_v) and their similarity s = ℳ_s(t, v) ∈ [0, 1].
Textual feature extraction. Text-CNN (Kim, 2014) is extended with an additional fully connected layer. Words are embedded via word2vec; a convolutional layer with window sizes H = {3, 4} produces feature maps over n-gram windows, followed by max-over-time pooling and a linear projection to t ∈ ℝᵈ.
Visual feature extraction. Rather than applying a pre-trained vision model (e.g., VGG-19) directly to pixel data, images are first processed by the image2sentence model (Vinyals et al., 2016) to produce a sentence-like embedding of the visual content. The same Text-CNN architecture is then applied to produce v ∈ ℝᵈ. This ensures t and v inhabit a comparable representation space, making cross-modal similarity computationally well-defined.
Modal-independent prediction. The concatenation t ⊕ v is passed to a softmax classifier ℳ_p with cross-entropy loss:
Cross-modal similarity extraction. Similarity is a modified cosine that maps to [0, 1]:
The similarity loss ℒ_s minimizes cross-entropy under the assumption that low-similarity (mismatched) articles are more likely to be fake. Joint loss: ℒ = αℒ_p + βℒ_s. Parameters are updated in closed-form gradient steps for θ_p, θ_t, and θ_v until convergence.
Results¶
Datasets: PolitiFact (1,056 articles: 432 fake, 624 true) and GossipCop (22,140: 5,323 fake, 16,817 true) from FakeNewsNet. Split: 80/20 by publication date; 5-fold cross-validation. Learning rate 10⁻⁴, 100 iterations, strides H = {3, 4}.
| Dataset | Method | Acc. | Pre. | Rec. | F₁ |
|---|---|---|---|---|---|
| PolitiFact | LIWC | 0.822 | 0.785 | 0.846 | 0.815 |
| VGG-19 | 0.649 | 0.668 | 0.787 | 0.720 | |
| att-RNN | 0.769 | 0.735 | 0.942 | 0.826 | |
| SAFE | 0.874 | 0.889 | 0.903 | 0.896 | |
| GossipCop | LIWC | 0.836 | 0.878 | 0.317 | 0.466 |
| VGG-19 | 0.775 | 0.775 | 0.970 | 0.862 | |
| att-RNN | 0.743 | 0.788 | 0.913 | 0.846 | |
| SAFE | 0.838 | 0.857 | 0.937 | 0.895 |
Ablation (F₁ on PolitiFact / GossipCop): SAFE\T 0.761/0.837 < SAFE\V 0.782/0.868 < SAFE\S 0.813/0.868 < SAFE\W 0.795/0.876 < SAFE 0.896/0.895. Best weighting: α:β = 0.4:0.6 on PolitiFact, 0.6:0.4 on GossipCop.
Connections¶
- Uses FakeNewsNet (PolitiFact + GossipCop); for social-context approaches on the same data, see Shu et al. (2019).
- Extends the content-based detection paradigm to the multi-modal regime; feature engineering baselines (LIWC, RST) are the comparison regime that SAFE surpasses.
- See multimodal detection for the broader landscape of text+image approaches.
- Sitaula et al. (2019) demonstrates that source-credibility features outperform 23 text-content features — a complementary finding that SAFE's content-based neural approach also reflects by outperforming LIWC text baselines.
- SAFE is used as a multimodal baseline in ReCOVery (Zhou et al., 2020), achieving F₁ 0.833/0.672 (reliable/unreliable) on COVID-19 data — the best-performing baseline in that benchmark.
Notes¶
The image2sentence step converts images to a text-like embedding via a captioning model, making the cross-modal similarity essentially a text-vs-generated-caption comparison. This is architecturally elegant and ensures commensurability, but sacrifices low-level visual signals (color, composition, copy-paste artifacts) that might independently indicate image manipulation.
SAFE is content-only by design, explicitly targeting the pre-diffusion stage where no social context exists. This makes it complementary to social-context methods like UPF but also limits it: well-curated fake news stories with deliberately matching images will not be caught by the similarity signal.
GossipCop is heavily class-imbalanced (5,323 fake vs. 16,817 true); LIWC collapses to near-random fake recall (0.317), illustrating how accuracy alone is misleading under imbalance. SAFE achieves strong recall (0.937) on the minority fake class without sacrificing overall F₁.