DEAP-FAKED: Knowledge Graph based Approach for Fake News Detection¶
Authors: Mohit Mayank, Shakshi Sharma, Rajesh Sharma
Venue: IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), 2022 — arXiv:2107.10648
TL;DR¶
DEAP-FAKED combines a biLSTM news encoder with knowledge graph embeddings to detect fake news using only article titles. The approach extracts named entities from titles, maps them to Wikidata using named entity disambiguation, and embeds them via ComplEx. Achieves 88% F1 on Kaggle Fake News dataset and 78% F1 on CoAID by addressing dataset bias through removal of biased terms.
Contributions¶
- Minimal-information framework using only news titles for fake news detection, applicable to early detection on social media where metadata is unavailable
- Incorporation of knowledge graph entity embeddings to complement NLP-based title encoding
- Systematic handling of dataset bias by identifying and removing biased terms (e.g., publication house names) that artificially inflate model performance
- Empirical validation showing entity-aware models achieve ~13% F1 improvement on Kaggle dataset over content-only baselines
Method¶
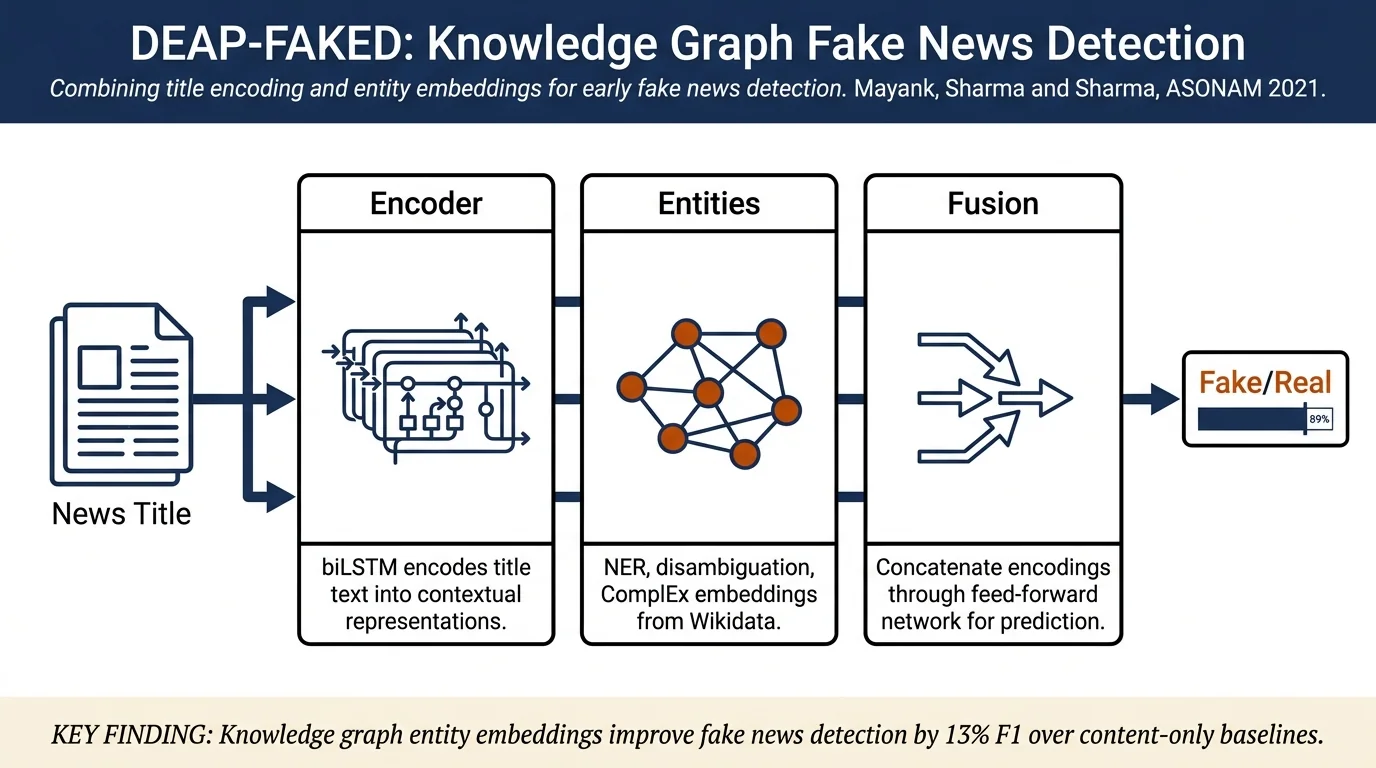
DEAP-FAKED has three components:
News encoder: A 2-layer stacked biLSTM encodes news titles into contextual representations. Token input limited to 256 tokens. Chosen for efficiency on short sequences typical of social media propagation.
Entity encoder: Pipeline performing named entity recognition (NER) using SpaCy-based RoBERTa model, named entity disambiguation (NED) via Wikidata's disambiguation services, and ComplEx-based knowledge graph embedding. ComplEx chosen for its ability to capture anti-symmetric relations in complex space. Embeddings are aggregated via mean pooling across all entities in the title.
Classification layer: Concatenates news and entity representations, passes through a feed-forward network with sigmoid activation for binary classification.
Results¶
Evaluated on two datasets after bias removal and entity-mappable filtering:
Kaggle Fake News dataset (KFN-UB): ~14k items (60% true, 40% fake). DEAP-FAKED achieves 0.89 F1-score and 0.90 accuracy, outperforming StackedBiLSTM (0.79 F1), SentRoBERTa (0.65 F1), and text-based entity encoding (EntWiki-StackedBiLSTM, 0.88 F1).
CoAID COVID-19 dataset (CoAID-UB): 632 items after filtering. DEAP-FAKED achieves 0.78 F1 and 0.78 accuracy, with ~1.5% improvement over content-only models (0.747 F1). Entity-aware models show ~1.5% F1 improvement over models without the entity encoder.
Knowledge graph entity encoding substantially outperforms Wikipedia text-based entity encoding, attributable to concentrated information from multi-hop aggregation in KG embeddings versus single source summaries.
Connections¶
- Related to Propagation-based fake news detection and Content-based fake news detection as a hybrid approach combining textual and structural signals
- Complements FakeNewsNet: A Data Repository with News Content, Social Context and Spatiotemporal Information for Studying Fake News on Social Media and CoAID: COVID-19 Healthcare Misinformation Dataset as a detection method for their benchmark datasets
- Shares knowledge graph methodology with Computational fact checking from knowledge networks though applied to classification rather than verification
- Influenced by EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection in combining multiple feature families for improved detection
Notes¶
The paper's focus on title-only detection is practical for early detection scenarios on Twitter and WhatsApp where comments/metadata are unavailable or difficult to extract. The systematic bias removal (publication house names, politician mentions) is often overlooked in prior work but meaningfully improves results; authors show bias handling is orthogonal to method choice—applicable to any detector. ComplEx embedding choice is well-motivated for the knowledge graph domain. However, entity mapping filtering reduces KFN-UB from 14k to ~14k items and CoAID from 4,251 to 632, significantly limiting dataset size; this suggests either lower entity coverage in health misinformation or stricter NED accuracy requirements. Cross-domain transfer and robustness to entity mapping failures not addressed.