A Survey on Multimodal Disinformation Detection¶
Authors: Firoj Alam, Stefano Cresci, Tanmoy Chakraborty, Fabrizio Silvestri, Dimitar Dimitrov, Giovanni Da San Martino, Shaden Shaar, Hamed Firooz, Preslav Nakov
Venue: arXiv preprint, 2021 — arXiv:2103.12541
TL;DR¶
Comprehensive survey of multimodal disinformation detection covering text, images, speech, video, network structure, and temporal information. Distinguishes factuality (whether content is false) from harmfulness (whether false content intends to harm), systematically reviews ~140 papers across different modalities and detection approaches, and identifies key challenges in combining multiple modalities while achieving both factuality and harmfulness detection simultaneously.
Contributions¶
- Unified framework distinguishing two critical aspects of disinformation: factuality (content falsity) and harmfulness (intent and impact to deceive/harm)
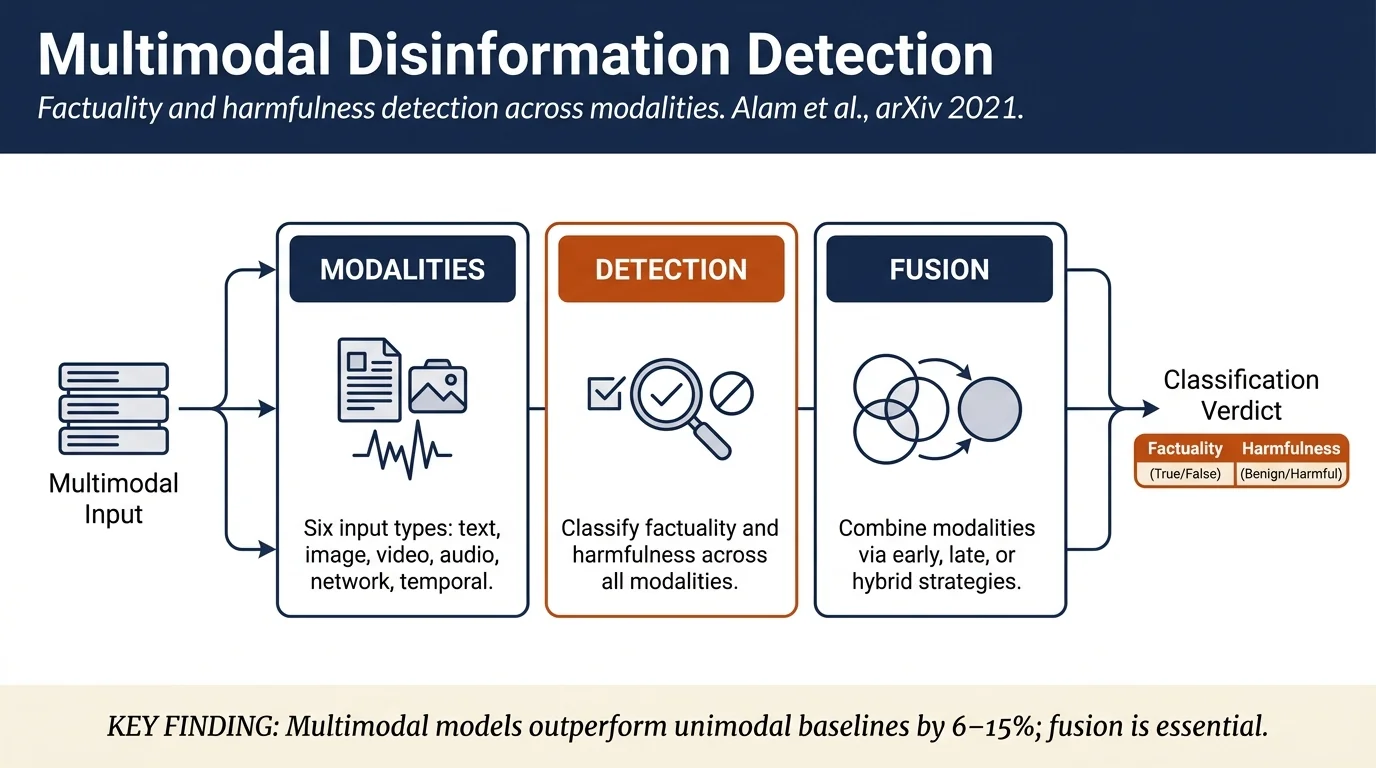
- Systematic survey covering six modalities: text, images, speech/audio, video, network structure, and temporal information
- Comprehensive literature review (~140 papers) organized by modality and task type with detailed analysis of datasets, methods, and results
- Identification of major research challenges: dataset scarcity, cross-modal inconsistency, explainability, knowledge-based approaches, and evaluation methodology
- Discussion of fusion strategies for combining multiple modalities: early fusion, late fusion, and hybrid approaches
Method¶
The survey is organized by modality and detection approach:
Factuality Prediction (Section 2): Review of work on detecting false claims in text (fact-checking, linguistic analysis), images (fauxography, manipulated images), speech (acoustic cues for political bias detection), video (visual manipulations, deepfakes), and network/temporal signals (propagation patterns, diffusion dynamics).
Harmful Content Detection (Section 3): Coverage of hate speech, cyberbullying, propaganda, violence detection, and toxic content across modalities. Documents differences in harmful content types (targeted harassment, misinformation, extremism) and modality-specific characteristics.
Multimodal Fusion Strategies (Section 4): Analysis of three fusion paradigms for combining text, image, and other modalities: (i) early fusion (combining raw features), (ii) late fusion (combining unimodal decisions), and (iii) hybrid fusion (learning shared representations with subset-based fusion). Reviews datasets and models including BERT variants, ViLBERT, Multimodal BERT (MMBT), and VisualBERT.
Results¶
Key empirical findings: - Multimodal models consistently outperform unimodal (text-only) baselines by 6–15% across multiple datasets (Twitter, Weibo, Reddit) - False news spreads 6× faster than true news with higher reach and velocity (Vosoughi et al. 2017) - Humans struggle to detect AI-generated text when generated via nucleus sampling (~54% accuracy), but transformer-based detectors achieve >80% accuracy - Cross-modal inconsistency: content and images often diverge in fake news, requiring joint reasoning to detect - Bot-driven amplification: social bots disproportionately amplify harmful content despite comprising only 6% of misinformation-spreading accounts - Early detection possible within 24 hours using temporal and network features with 75% accuracy
Connections¶
- Related to SAFE: Similarity-Aware Multi-Modal Fake News Detection via cross-modal detection framework
- Extends Fakeddit dataset work on multimodal benchmarks
- Synthesizes work by Suhang Wang and colleagues on multimodal fusion (EANN, MVAE)
- Related to Vosoughi et al. (2017) on differential diffusion of true vs. false news
- Discusses FakeNewsNet as key multimodal benchmark
Notes¶
Strengths: - First comprehensive survey bridging factuality and harmfulness detection in multimodal setting - Systematic taxonomy of modalities and fusion strategies with clear comparison of approaches - Detailed discussion of dataset availability and limitations across modalities - Pragmatic identification of open challenges relevant to practitioners
Weaknesses: - Focus on English-dominant datasets; limited coverage of non-English or multilingual multimodal work - Limited discussion of user-generated content on private platforms (WhatsApp, Telegram) - Explainability of multimodal models remains underdeveloped; survey notes few works focus on interpretability
Follow-ups: - Development of unified benchmarks covering multiple modalities, languages, and domains simultaneously - Scaling of multimodal detection to handle heterogeneous signals (text ≠ speech ≠ visual) without alignment assumptions - Incorporation of commonsense reasoning and knowledge bases into purely data-driven multimodal approaches - Study of adversarial attacks on multimodal systems, particularly cross-modal perturbations