Network-based Fake News Detection: A Pattern-driven Approach¶
Authors: Xinyi Zhou, Reza Zafarani Venue: arXiv preprint, 2019 — arXiv:1906.04210
TL;DR¶
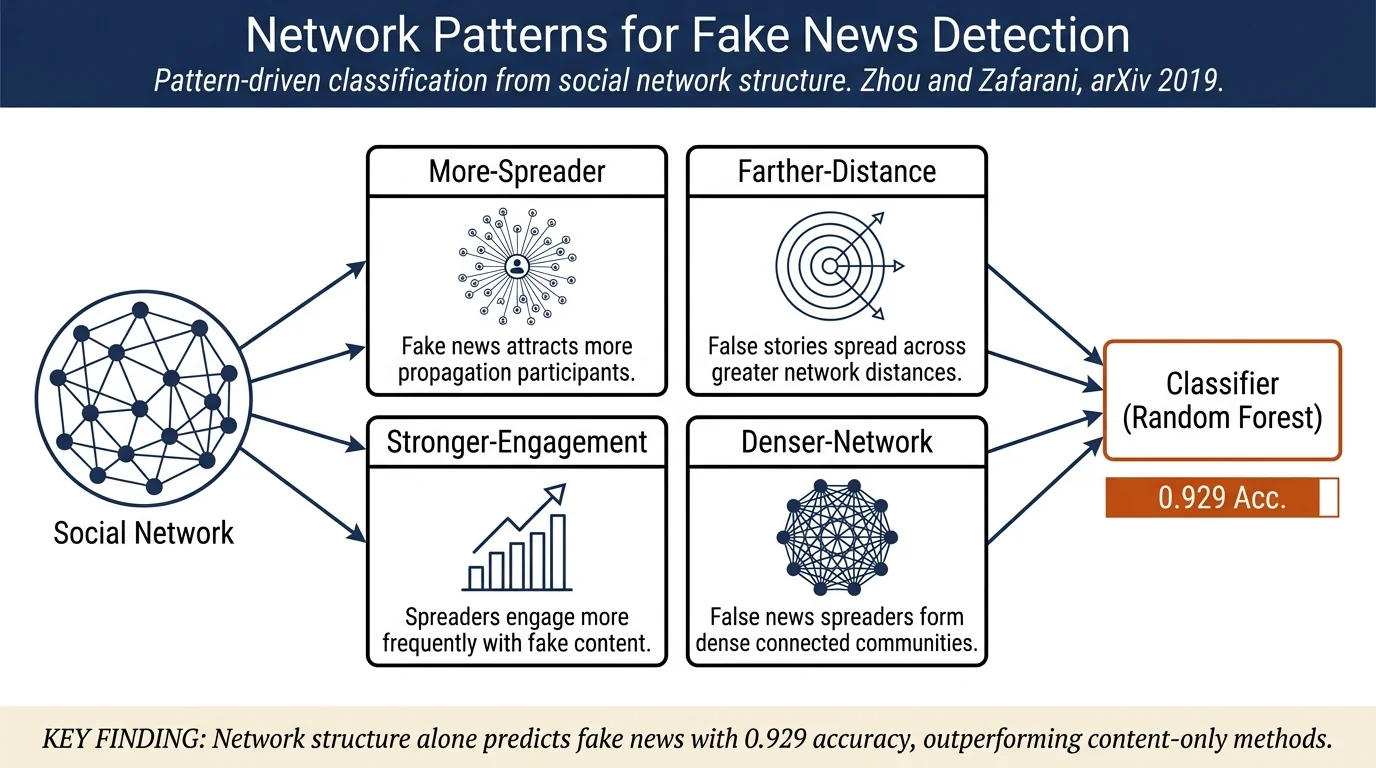
This paper proposes a pattern-driven, network-based fake news detection model that identifies and quantifies four empirically grounded behavioral patterns in social networks: fake news attracts more spreaders, spreads farther, elicits stronger engagement, and is spread by denser networks than true news. These patterns are operationalized as 138 interpretable features extracted from the friendship network (Twitter) at node, ego, triad, community, and network levels, and fed to classical supervised classifiers. A Random Forest achieves 0.929 accuracy and 0.932 F₁ on PolitiFact, matching or exceeding hybrid (content + network) baselines while relying solely on network structure.
Contributions¶
- Four empirically motivated and theoretically grounded fake news patterns in social networks: More-Spreader, Farther-Distance, Stronger-Engagement, and Denser-Network — each supported by evidence from social psychology (homophily, social validation) and information gap theory.
- A 138-feature representation of these patterns across five network levels (node, ego, triad, community, overall network), including user susceptibility scores, centrality measures, geodesic and effective distances, 12 triad types, and community density estimates.
- A definition of Fake News Network (FNN) as the friendship-network subgraph of users who spread a given fake story, enabling direct structural comparison with True News Networks (TNNs).
- Experiments demonstrating that the pattern-driven approach matches or outperforms content-based and network-based baselines, and can detect fake news from limited (early-stage) network information.
Method¶
The paper defines a Fake News Network (FNN) \(G_{\mathcal{F}} = (V_{\mathcal{F}}, E_{\mathcal{F}})\) as the subgraph of the overall Twitter friendship graph induced by users who spread a fake news story \(\mathcal{F}\). A True News Network (TNN) \(G_{\mathcal{T}}\) is defined symmetrically. Detection is then a binary classification problem: given an FNN or TNN, predict the label.
Four patterns are formalized and feature-engineered:
1. More-Spreader Pattern. Fake news attracts more users. Measured by spreader counts and proportions, with users labeled as susceptible (spreads fake news disproportionately) or normal via susceptibility score \(S(v_i)\) — either the proportion of a user's past shares that were fake, or a frequency-weighted variant. Centrality measures (degree, closeness, betweenness, PageRank, hub/authority) provide user influence features. Features 1–29.
2. Farther-Distance Pattern. Fake news spreads farther. Measured as the diameter of each FNN/TNN using (i) geodesic distance (shortest path length between the two most distant spreaders) and (ii) effective distance, defined via the information-flow matrix \(F_{ij}\) as \(d_{\text{eff}}(i,j) = 1 - \log(F_{ij}/\sum_l F_{lj})\), where the diameter is the minimum sum of effective distances between the two most distant nodes. Features 30–38.
3. Stronger-Engagement Pattern. Spreaders engage more frequently with fake news. Group-level engagement is the total spreading frequency across the FNN; individual-level engagement is the mean/proportion frequency for susceptible vs. normal users. Features 39–52.
4. Denser-Network Pattern. Fake news spreaders form more densely connected networks. At the ego level: total and typed ego relationships (N→N, N→S, S→N, S→S), ego density \(|E_X|/\binom{|V_X|}{2}\), and edge susceptibility difference classes (\(E_{\triangle>0}\), \(E_{\triangle=0}\), \(E_{\triangle<0}\)). At the triad level: counts and proportions of all 12 distinct directed triad types among susceptible/normal users. At the community level: community count \(|M_X|\) and community density \(|M_X|/|V_X|\) from both global (Louvain modularity) and local perspectives. Features 53–138.
Classification: 5-fold cross-validation with SVM, kNN, Naïve Bayes, Decision Tree, and Random Forest. RF performs best on both datasets.
Results¶
Evaluated on the PolitiFact (240 stories: 120 fake, 120 real) and BuzzFeed (182 stories: 91 fake, 91 real) partitions of FakeNewsNet. Each story provides the full FNN/TNN for feature computation.
Overall performance (RF):
| Method | PolitiFact Acc | PolitiFact F₁ | BuzzFeed Acc | BuzzFeed F₁ |
|---|---|---|---|---|
| Pérez-Rosas et al. — content-based | .811 | .811 | .755 | .757 |
| Zhou et al. (2020) — content-based | .865 | .865 | .855 | .856 |
| Castillo et al. — propagation | .794 | .822 | .789 | .794 |
| Shu et al. — hybrid | .878 | .880 | .864 | .870 |
| This work (network-based) | .929 | .932 | .835 | .842 |
| This work + Zhou et al. (2020) features | .933 | .939 | .865 | .884 |
Pattern ablation (Table 5): More-Spreader and Stronger-Engagement are the two strongest individual patterns (≈89% and ≈90% accuracy on PolitiFact, ≈81% and ≈81% on BuzzFeed). Farther-Distance is weakest (0.639/0.678). Combining all four patterns matches the full 138-feature RF, confirming that each pattern contributes complementary signal.
Feature importance (Table 6): Top features are mean and median spreader susceptibility scores (More-Spreader Pattern), community density (Denser-Network Pattern), and susceptible/normal user engagement proportions (Stronger-Engagement Pattern). Network diameter features (Farther-Distance Pattern) do not appear in the top-20 on either dataset.
Early detection (Section 4.2.6): When only a fraction of nodes or edges of each FNN/TNN is observed (simulating early propagation), accuracy and F₁ remain in the 0.80–0.90 (0.70–0.82) range on PolitiFact (BuzzFeed), demonstrating robustness to limited propagation data.
Connections¶
- Directly complements Zhou et al. (2020), which detects fake news from content-only features at publication time; this paper covers the network side. Combining both achieves the best reported results in the comparison (0.933/0.939 on PolitiFact).
- Evaluated on the same PolitiFact and BuzzFeed partitions as Sitaula et al. (2019) and Shu et al. (2019), enabling direct comparison with source-credibility and user-profile approaches.
- The susceptibility score formulation (Equations 1 and 2) is a generalization of the user-profile features in Shu et al. (2019), which also uses spreading history as a user feature.
- The FNN construction relies on FakeNewsNet, which provides both news content and the Twitter social network (user-user and news-user relationships).
- The Denser-Network pattern operationalizes homophily and social validation theory: susceptible users who spread fake news tend to cluster together in ego- and community-level structures.
Notes¶
The paper's central claim — that network-structural patterns reliably distinguish fake from real news without reading the content — is well supported by the Random Forest numbers, which exceed content-only baselines by a substantial margin. The feature set is interpretable and grounded in social psychology theory, making this one of the more principled approaches in the explainability direction. A limitation is that the datasets are small (240 and 182 stories), which raises generalization questions. Additionally, the friendship network requires pre-existing propagation data: detection is only possible after a story has circulated, creating a latency cost that the content-based early-detection approach avoids. The effective-distance metric (borrowed from network epidemiology) is novel in this context but the Farther-Distance features underperform in practice, suggesting that how far news spreads matters less than who spreads it and how densely they are connected.