Fake News Early Detection: An Interdisciplinary Study¶
Authors: Xinyi Zhou, Atishay Jain, Vir V. Phoha, Reza Zafarani Venue: ACM, 2020 — arXiv:1904.11679
TL;DR¶
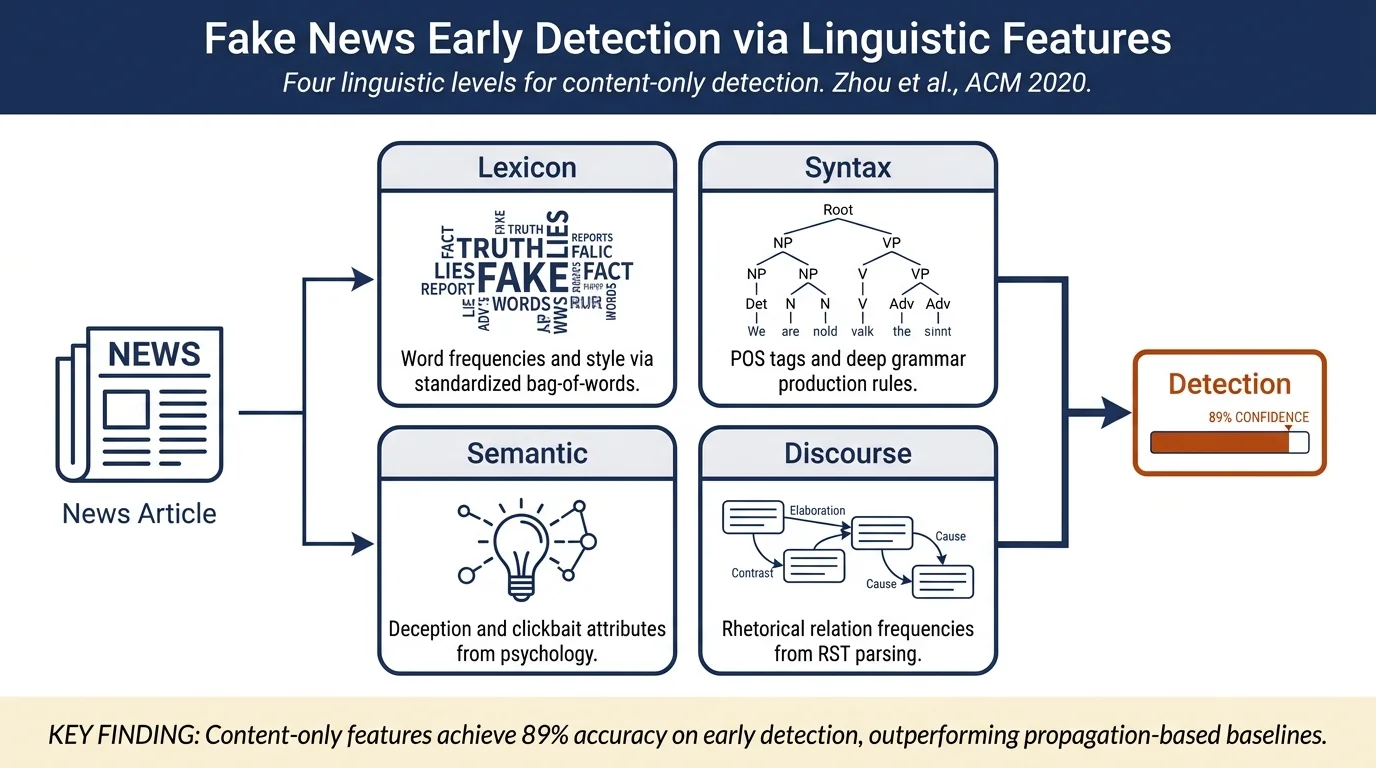
This paper proposes a theory-driven, content-only model for fake news detection at publication time — before social-media propagation data exists. News articles are represented at four linguistic levels (lexicon, syntax, semantic, and discourse) using features grounded in social and forensic psychology; classical supervised classifiers (SVM, RF, XGBoost) are applied on top. On PolitiFact and BuzzFeed benchmarks, the model achieves ≈89% accuracy and F₁ = 0.892/0.879, outperforming propagation-based and hybrid baselines while also revealing interpretable patterns linking fake news to deception and clickbait.
Contributions¶
- A content-based early detection model that requires no social-propagation data, achieving ~88% accuracy across two datasets when limited content information is available.
- A systematic, theory-grounded feature engineering framework for news articles, spanning lexicon-, syntax-, semantic- (DIA and CBA), and discourse-level representations.
- Empirical analysis of the relationships among fake news, deception/disinformation, and clickbait — revealing shared and distinct linguistic patterns.
- Evidence that fake news headlines share characteristics with clickbaits (greater sensationalism, lower news-worthiness, more words) and that fake news body-text patterns mirror those of deceptive writing (higher informality, higher subjectivity, more emotional language, shorter words, longer sentences).
Method¶
The method frames fake news detection as binary supervised classification on hand-crafted features, with the news article as sole input.
News representation operates at four linguistic levels:
- Lexicon-level: Standardized Bag-of-Words (sBOW) — relative (length-normalized) word frequencies across the article vocabulary. The standardization removes the confound of article length so that style, not verbosity, is measured.
- Syntax-level (shallow): POS tag frequencies; captures coarse grammatical patterns (noun-heavy vs. verb-heavy prose, use of adjectives, adverbs, etc.).
- Syntax-level (deep): Context-Free Grammar (CFG) production-rule frequencies from PCFG parse trees. Represents deep syntactic templates (e.g., S→NP PP, NP→DT NNP VBN) rather than individual POS categories.
- Semantic-level: Two groups grounded in psychological theories:
- Disinformation-related Attributes (DIAs, 72 features): Inspired by the Undeutsch hypothesis, reality monitoring, four-factor theory, and information manipulation theory. Cover content quality (informality, diversity, subjectivity via LIWC and biased-lexicon corpora), sentiment (positive/negative/anxiety/anger/sadness word proportions), quantity (character/word/sentence/paragraph counts and averages), and specificity (cognitive and perceptual process word frequencies via LIWC).
- Clickbait-related Attributes (CBAs, 44 features): Target news headlines specifically. Cover general clickbait phrase patterns (Downworthy dictionary), readability (Flesch, Kincaid, ARI, Gunning Fog, Coleman-Liau, and raw character/syllable/word/long-word counts), sensationalism (LIWC sentiment + punctuation frequencies + headline–body-text cosine similarity via Word2Vec and Sentence2Vec), and news-worthiness (content/function/stop-word ratios + LIWC informality dimensions).
- Discourse-level: RST rhetorical relation frequencies extracted via an RST parser; standardized to remove length effects.
Classification: SVM (linear kernel), Random Forest, and XGBoost. XGBoost performs best on all-RR features on PolitiFact; RF dominates on BuzzFeed. The no-free-lunch heuristic motivates reporting best-across-classifiers for each feature group.
Results¶
Evaluated on PolitiFact (240 articles: 120 fake, 120 real) and BuzzFeed (180 articles: 90 fake, 90 real), using 80/20 train/test splits with 5-fold cross-validation.
| Method | PolitiFact Acc | PolitiFact F₁ | BuzzFeed Acc | BuzzFeed F₁ |
|---|---|---|---|---|
| Pérez-Rosas et al. (content) | .811 | .811 | .755 | .757 |
| Castillo et al. (propagation) | .794 | .822 | .789 | .794 |
| Shu et al. (hybrid) | .864 | .880 | .864 | .870 |
| This work | .892 | .892 | .879 | .879 |
Feature-level breakdown (Table 3): - BOW (lexicon) and CFG (deep syntax) individually achieve >80% accuracy and F₁ on both datasets. - Semantic-level features (DIA + CBA) reach 70–80% accuracy. - Discourse-level (RR) alone is the weakest single group (62–66% accuracy). - Combining all features achieves ≈88% accuracy; all-RR combination is the individual best on PolitiFact at 89.2%. - Model performance is robust to class-imbalance perturbations: accuracy stays in the 0.75–0.90 range as fake/true proportions vary. - With only headline text (zero body paragraphs), the model remains competitive with the Pérez-Rosas baseline, validating its utility in extreme early-detection conditions.
Fake news patterns revealed: - Similar to deception: lower diversity of unique words/verbs, fewer report verbs, more swear words and emotional words, lower quality (subjectivity) signal. - Distinct from deception: shorter average word length, longer sentences. - Similar to clickbaits: headlines less similar to body-text, more negative sentiment, more words.
Connections¶
- Preceded by Zhou et al. (2023) — HERO, which replaces these handcrafted multi-level features with a hierarchical recursive neural network; the HCLF baseline in HERO directly corresponds to the feature-engineering pipeline developed here.
- Uses the same PolitiFact and BuzzFeed partitions as Sitaula et al. (2019), enabling direct comparison: source-credibility features (3 features, F₁ 0.77–0.83) vs. this paper's linguistic features (116+ features, F₁ 0.879–0.892).
- Shares first and last authors with Zhou et al. (2020) — SAFE, which extends to multimodal (text + image) content rather than text-only features.
- The psychological theory grounding (Undeutsch hypothesis, reality monitoring, four-factor theory, information manipulation theory) is the same theoretical foundation used in feature engineering for fake news broadly.
- Evaluates on the old-version of FakeNewsNet, footnoted as
KaiDMML/FakeNewsNet/tree/old-version.
Notes¶
The paper's core claim — that carefully designed theory-grounded features can outperform propagation-based and hybrid models for early detection — is well supported on the small benchmark sets used (240 and 180 articles). The datasets are notably small; replication on larger corpora is not shown. The discourse-level features (RST) are weak individually, which anticipates the HERO finding that preserving tree structure rather than extracting marginal relation frequencies is what matters for discourse-based detection. The interdisciplinary framing (forensic psychology + NLP + social science) is a strength for interpretability, though the feature set is large (116+ features) and not all features survive importance analysis.