Combating Fake News: A Survey on Identification and Mitigation Techniques¶
Authors: Karishma Sharma, Feng Qian, He Jiang, Natali Ruchansky, Ming Zhang, Yan Liu
Venue: ACM Transactions on Intelligent Systems and Technology, Vol. 37, No. 4, Article 111, August 2018 — DOI
TL;DR¶
This comprehensive survey of fake news detection and mitigation organizes existing methods into two broad categories: content-based approaches (linguistic and deep learning methods) and feedback-based approaches (exploiting propagation patterns, user responses, and temporal dynamics). The authors consolidate 23+ publicly available datasets with detailed characteristics and propose future research directions including dynamic knowledge bases, intervention strategies, and intent-driven classification schemes.
Contributions¶
- Formal definition of fake news encompassing intent-based distinctions (fabricated, misleading, imposter content, manipulated information, false connection/context)
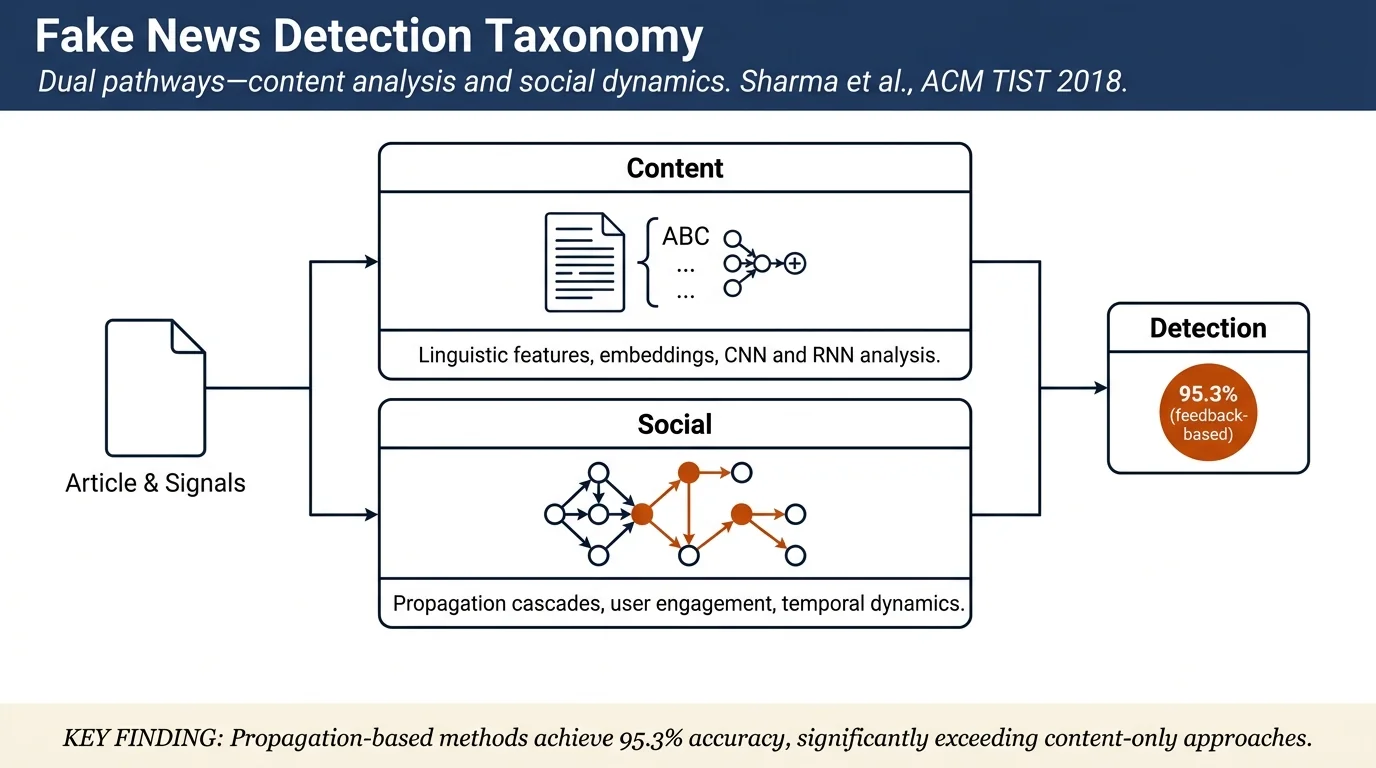
- Comprehensive taxonomy of detection methods: content-based (Part of Speech tags, syntactic features, CNNs, RNNs) and feedback-based (propagation kernels, temporal patterns, user/group analysis, response generation)
- Systematic enumeration of 23+ fake news datasets with task/application context, annotation scheme, and collected user engagement features
- Identification of key challenges: individual cognitive biases, social media echo chambers, intentionality detection, and evaluation of intervention strategies
Method¶
The survey reviews methods across two complementary dimensions:
Content-based identification exploits linguistic and stylistic features of articles themselves. Shallow methods include Part-of-Speech (POS) tagging and Probabilistic Context Free Grammar (PCFG) features capturing deceptive writing patterns (more nouns, adjectives, prepositions in fake texts). Deep learning approaches use Convolutional Neural Networks (CNNs) on word embeddings to capture semantic patterns, and Recurrent Neural Networks (RNNs) with LSTM variants to model sequential dependencies and longer-range contextual information. Recent work adds attention mechanisms and multi-task learning to jointly predict stance, veracity, and rumor type.
Feedback-based identification leverages social dynamics on social media. Propagation tree kernel methods compute similarity between diffusion cascades of articles, exploiting differences in how true and false stories spread (false news typically spreads faster and wider in initial hours). Propagation process modeling (e.g., the SEIZ model) characterizes user transitions between susceptible, exposed, infected (sharing), and skeptical states. Temporal analysis tracks how engagement patterns (reshares, comments, timestamps) differ between true and false articles. User response analysis examines both individual user engagement features and group behaviors—polarized users and users in echo chambers show higher susceptibility to misinformation. Response generation methods use CNNs and generative models (URG) to infer community sentiment toward articles even without direct access to full article content.
Results¶
Content-based methods (Tables 5–6): Ott et al.'s n-gram classifier achieves 84.76% on Weibo and 80.69% on Twitter; Wang 2017 reaches 86.23% (Weibo) and 83.24% (Twitter); Qian et al. 2018 (with LSTM on both text and metadata) achieves 89.84% and 88.83% respectively. Deep learning consistently outperforms linguistic features alone, but remains challenging on articles with sophisticated, well-crafted deception.
Feedback-based methods (Table 6): Ruchansky et al. 2017 (temporal + user group features) achieves 95.3% on Twitter and 91.1% on Weibo—notably higher than content-only methods. Ma et al. variants (2015–2018) using propagation structure and RNNs achieve 73.2–91.1% accuracy depending on dataset and feature set. Propagation-based methods trade off computational cost (expensive pairwise kernel computation over cascades) against detection latency; early detection (hours after posting) is significantly harder than post-hoc analysis.
Connections¶
- Related to Fake News Detection on Social Media: A Data Mining Perspective via complementary organization: Shu et al. ground methods in psychological/social theory; Sharma et al. emphasize technical landscape of identification vs. mitigation.
- Extends A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities in mitigation direction: Zhou & Zafarani focus on detection methods; Sharma et al. dedicate Section 6 to intervention strategies, inoculation, and active learning for labeling.
- Shares dataset focus with FakeNewsNet: both provide structured comparison of multiple corpora; Sharma et al.'s Tables 2–4 are particularly valuable for dataset selection by task (early detection, multimodal, stance classification).
- Complements Fake news game confers psychological resistance against online misinformation on intervention: Roozenbeek et al. evaluate psychological inoculation empirically; Sharma et al. survey computational intervention approaches.
Notes¶
This survey is exceptionally well-structured for practitioners. The dataset tables (Tables 2–4) are a resource in themselves—the annotation schemes, task definitions, and platform breakdowns are invaluable for selecting appropriate evaluation data. The distinction between identification challenges (early detection, cross-domain generalization) and mitigation challenges (designing interventions, measuring counterfactual impact) is often blurred in the literature; Sharma et al. are explicit about the difference.
The paper's framing of fake news intent (fabricated vs. misleading vs. imposter vs. manipulated) is comprehensive but not universally adopted in later work. Subsequent literature tends to conflate these or focus only on binary fake/real classification.
The discussion of individual vs. social factors (Section 2.2) usefully situates computational methods within psychological theory—cognitive biases, confirmation bias, echo chambers—making clear that methods exploiting propagation dynamics are indirect proxies for underlying social phenomena. This grounding anticipates later work on psychological drivers (Ecker et al.).
Limitations: The mitigation section (Section 6) is literature survey rather than novel contribution; empirical evaluation of interventions is sparse. The paper does not discuss multimodal detection (text + images + video), which becomes increasingly important in 2019–2020. Some datasets listed (e.g., WikipediaHoax for hoax detection) are tangential to news specifically.