A large-scale COVID-19 Twitter chatter dataset for open scientific research¶
Authors: Juan M Banda, Ramya Tekumalla, Guanyu Wang, Jingyuan Yu, Tuo Liu, Yuning Ding, Katya Artemova, Elena Tutubalina, Gerardo Chowell
Posted: arXiv 2004.03688, April 2020
TL;DR¶
Banda et al. release a massive curated corpus of 800+ million COVID-19–related tweets collected from January through November 2020, with deduplication and language diversity. The dataset adheres to FAIR principles and provides both raw tweets and metadata (terms, bigrams, trigrams, hashtags, emojis, mentions) to support research on misinformation identification, sentiment tracking, and public responses to the pandemic. Code and processing pipelines are shared on GitHub.
Contributions¶
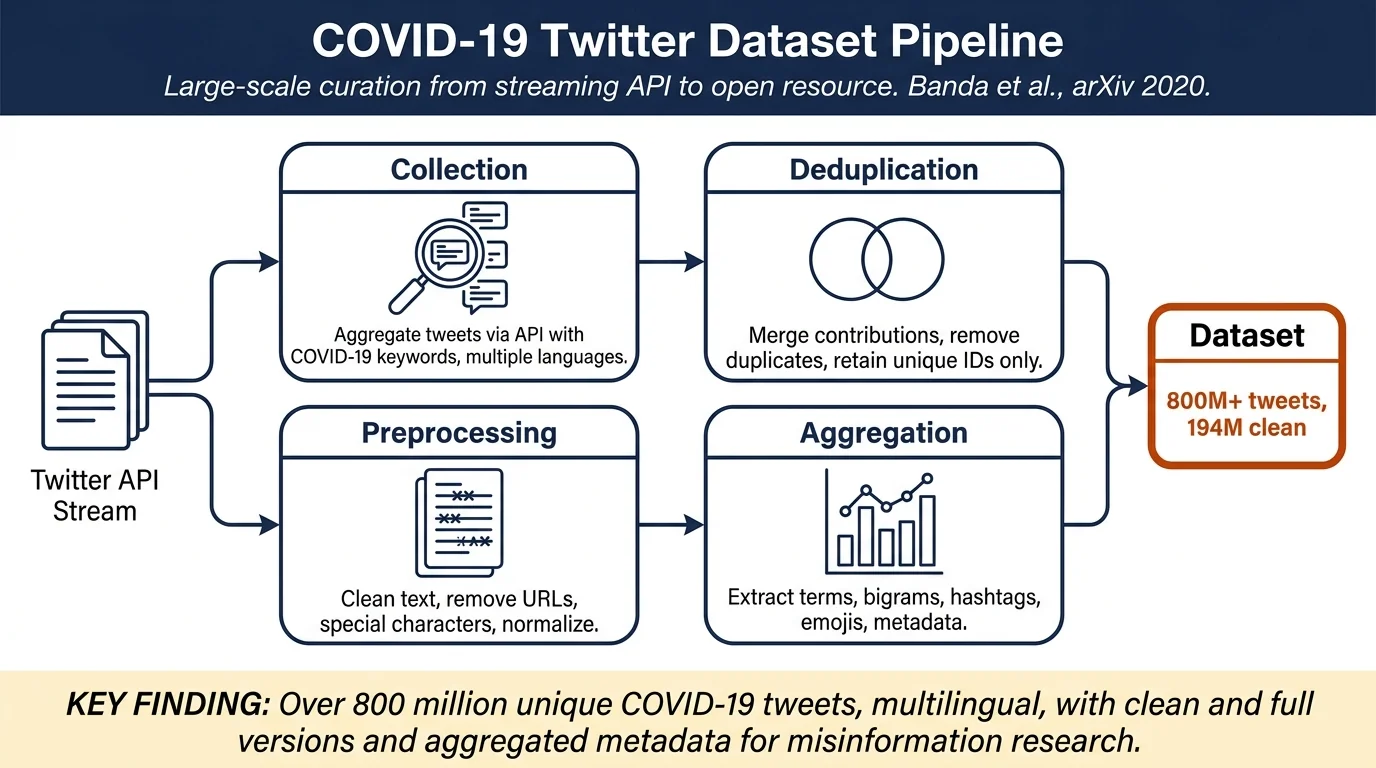
- Dataset curation and release: Over 800 million unique tweets collected via Twitter API, including contributions from international collaborators and data in multiple languages (English, Spanish, French, German, Russian).
- Clean and full versions: Separate datasets with and without retweets to serve different research needs (sentiment/NLP vs. cascade analysis).
- Preprocessing and reuse infrastructure: Open-source tools for hydrating tweet IDs, extracting metadata, computing frequent terms/bigrams/trigrams, and aggregating results.
- International collaboration: Coordinated collection across institutions to expand coverage and add multilingual tweets.
- Public availability: Dataset released via Zenodo under FAIR principles, with automated bi-weekly updates maintained through the pandemic period.
Method¶
Collection began January 1, 2020 with three keywords ("coronavirus", "2019ncov", "corona virus"). On March 12, 2020, the team shifted to exclusive COVID-19 focused keywords: "COVID19", "CoronavirusPandemic", "COVID-19", "2019nCoV", "CoronaOutbreak", "coronavirus", "WuhanVirus". Collection used the Twitter Stream API (1% sample) via Python and Tweepy. International collaborators contributed tweets collected independently with keywords in English, French, Spanish, and German ("coronavirus", "wuhan", "pneumonia", etc.). All contributions were deduplicated and merged, retaining only unique tweet identifiers. Preprocessing removes URLs, special characters, and carriage returns; a clean version also removes retweets for NLP tasks. Frequent term/bigram/trigram extraction uses spaCy stop-word removal.
Results¶
Dataset composition (as of November 8, 2020): - Full dataset: 800,064,296 tweets (with retweets) - Clean dataset: 194,272,176 unique tweets (retweets removed) - Monthly volume peaked in April–May 2020 (120–128 million tweets) and gradually declined through October - Top frequent term: "covid19" (1,767,060 occurrences) - Top bigram: "covid 19" (1,467,434 occurrences) - Data includes date, time, language, country code, frequent terms, bigrams, trigrams, emojis, hashtags, and mentions - Provided as tab-delimited gzip files via Zenodo; tweet text inaccessible (Twitter ToS) but IDs shareable and hydrable
Connections¶
- Related to Vosoughi et al. on how false news spreads differently than truth — applies to COVID misinformation cascades.
- Builds on Twitter-as-research-platform work by Castillo et al. for crisis communication.
- Enables sentiment and stance analysis methods like those in Zubiaga et al. applied to pandemic discourse.
- Complements FakeNewsNet as a crowd-sourced dataset for misinformation research, but focused on a single event stream.
Notes¶
This is a pure resource paper — no novel detection or modeling contributions. Its value lies in the scale, curation, and multilingual breadth of the corpus, plus the shared infrastructure for reuse. The dataset is especially useful for tracking real-time sentiment, cascade dynamics, and rumor spread during the initial pandemic shock. The emphasis on "identification of sources of misinformation" in the abstract positions this for misinformation researchers, though the paper does not itself conduct detection work. The open-science ethos and rapid public release (40M tweets on March 23, ongoing biweekly updates) set a strong precedent for crisis informatics research. One limitation: relies on 1% Twitter API sample, so coverage is not exhaustive, and removed tweets (user deletions) reduce reproducibility over time.