Information Credibility on Twitter¶
Authors: Carlos Castillo, Marcelo Mendoza, Barbara Poblete Venue: Proceedings of the World Wide Web Conference (WWW), 2011
TL;DR¶
This paper proposes supervised learning classifiers to automatically assess the credibility of news discussed on Twitter. Using human-labeled topics from trending discussions, the authors extract message-level, user-level, topic-level, and propagation-level features to build classifiers that distinguish newsworthy from conversational content (89% accuracy) and credible from non-credible news (86% accuracy). Results show that user reputation, sentiment patterns, and propagation structure—not text alone—are the strongest credibility signals.
Contributions¶
-
First dataset for Twitter credibility assessment — 2,500+ trending topics automatically detected from Twitter; manually labeled by crowd workers for newsworthiness and credibility level; 747 topics classified as news.
-
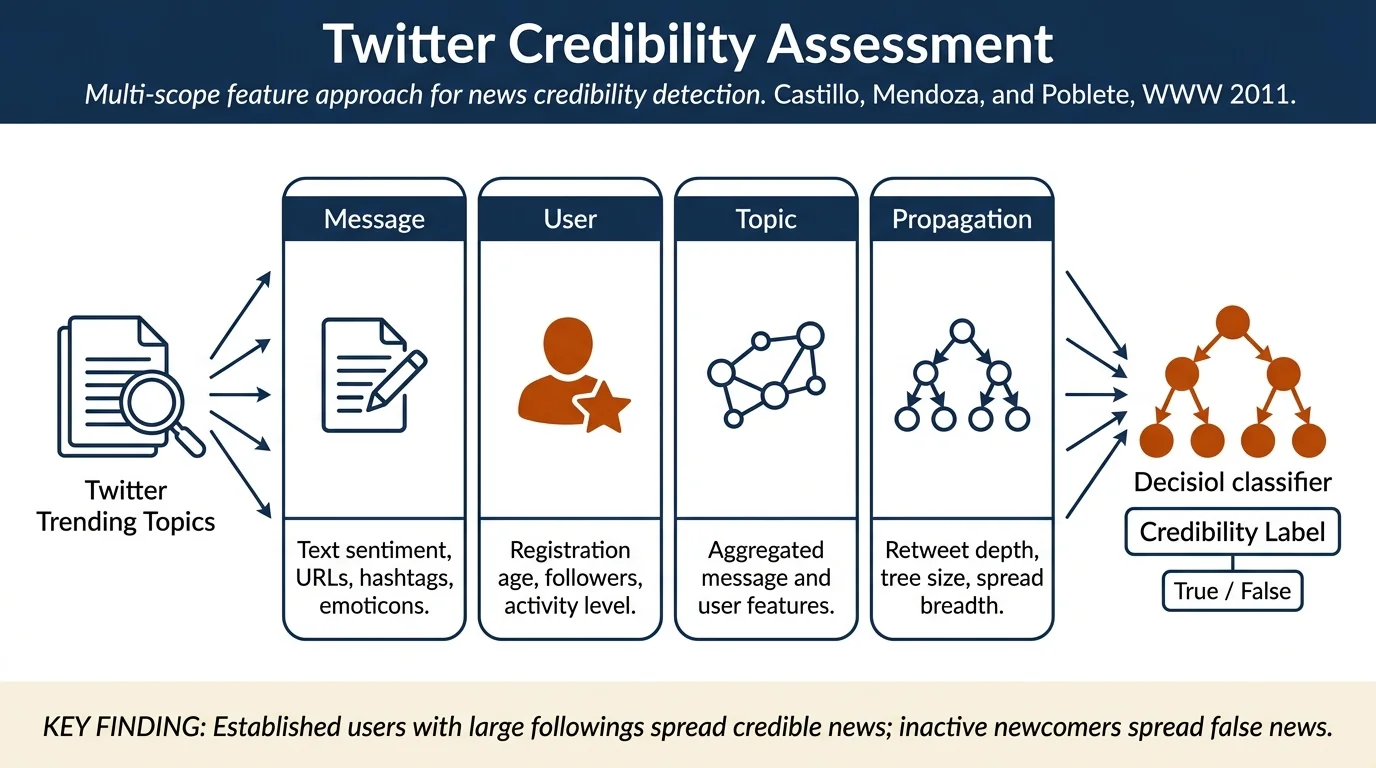
Comprehensive feature engineering — 51 features across four scopes: message-based (text properties, URLs, hashtags, sentiment), user-based (registration age, followers, activity), topic-based (aggregates), and propagation-based (retweet tree structure).
-
Two-stage classification framework — first identifies newsworthy topics (precision 92%, recall 93% via J48 decision tree with cost-sensitive learning); second predicts credibility of newsworthy topics (precision 87%, recall 83%).
-
Feature analysis — identifies top 15 discriminative features and demonstrates that propagation patterns and user reputation are more predictive than textual features alone; sentiment features also highly relevant.
Method¶
Data Collection (Section 3): - Used Twitter Monitor to detect keyword bursts (sharp increases in tweet frequency) over 2 months in 2010 - Collected tweets matching detected trends during 2-day windows centered on peak; >2,500 topics collected - Balanced two manual labeling rounds: (1) newsworthy topic identification via Mechanical Turk (383 sampled topics, 7 assessors per topic, majority voting); (2) credibility assessment (4-level scale: almost certainly true, likely false, almost certainly false, ambiguous)
Feature Extraction (Section 4.1): Grouped into four types: - Message features (20): text length, question/exclamation marks, sentiment words, URLs, hashtags, retweet status, emoticons, user mentions - User features (7): registration age, tweet count, followers, followees, verified status, profile description, homepage URL - Topic features (31): aggregates of message features (fractions, counts of URLs, hashtags, sentiment, etc.) - Propagation features (6): retweet tree depth, subtree size, degree, propagation breadth
Supervised Learning (Sections 4.2 & 4.4): - Trained J48 decision tree classifiers with cost-sensitive learning (NEWS class weighted 1.0, others 0.5) - Applied bootstrapping (300% sample size) and 3-fold cross-validation - Compared multiple algorithms (SVM, decision trees, rules, Bayes nets); decision trees performed best
Results¶
Newsworthy Topic Detection: - Accuracy: 89.1% (Kappa=0.837) - Per-class F1 scores: NEWS 0.924, CHAT 0.883, UNSURE 0.866 - Best predictors: propagation depth, URL presence, sentiment; newsworthy topics have deeper retweet trees
Credibility Assessment: - Accuracy: 86.0% (Kappa=0.719) on binary classification (truly credible vs. all others, excluding ambiguous) - Per-class F1: class A ("almost certainly true") 0.849, class B ("false") 0.87 - Top 15 features (GINI importance): - User reputation (avg. registration age, followers, friendees, activity) - Topic sentiment (fraction negative > positive sentiment strongly predicts credibility) - URL presence (messages without URLs trend non-credible) - Propagation structure (retweet tree size, maximum level size)
Feature Subset Analysis (Table 8): - Text features alone: 74.2% weighted average F1 - Network (user) features alone: 72.7% - Propagation features alone: 75.8% (best for detecting false news) - Top-element subset (most-frequent URL/hashtag/author): 78.7% (best for detecting credible news) - Combined: 86.0%
Key Finding: Credible news propagates through established, active users with large followings; false news predominantly shared by inactive newcomers. Sentiment is inverse predictor—negative sentiment correlates with credible news; positive and question marks with false news.
Connections¶
- Related to Vosoughi et al. (2017) on diffusion patterns; both show false news propagates differently, though Vosoughi shows false info spreads faster, this work shows it spreads among less-credible users.
- Foundational for Shu et al. (2019) on user profiles — this paper first systematically uses user-level features for credibility.
- Cited in Zhou et al. (2020) on early detection frameworks; shows propagation patterns available early in dissemination.
- Related methodology to Grinberg et al. (2019) on echo chambers; both study Twitter user reputation and information flows.
Notes¶
Strengths: - Large-scale systematic study with rigorous human annotation (crowd-sourced, majority voting, multiple assessors) - Comprehensive feature engineering across multiple information scopes; transparent methodology facilitates reproducibility - Feature importance analysis clearly identifies which signals matter most - Practical: runs on platform-available signals without external knowledge bases
Limitations: - 2010 data only; Twitter ecosystem, user behavior, and bot prevalence changed dramatically since then - Binary/ternary credibility labels (true/false/ambiguous) coarse; no claim-level verification, only topic-level - Limited to English-language, trend-driven events; unclear generalization to low-volume or non-English content - No comparison to competing credibility-assessment systems; proprietary baseline unavailable - Doesn't address intentional disinformation vs. honest error; treats all false claims identically
Future directions: Authors identify opportunity to extend to partial-time observations (early detection), explore impact of linked external sources, and investigate additional contextual factors (avatar, follower prestige, temporal dynamics).