Stance Classification in Rumours as a Sequential Task Exploiting the Tree Structure of Social Media Conversations¶
Authors: Arkaitz Zubiaga, Elena Kochkina, Maria Liakata, Rob Procter, Michal Lukasik
Venue: arXiv preprint, 2016 — arXiv:1609.09028
TL;DR¶
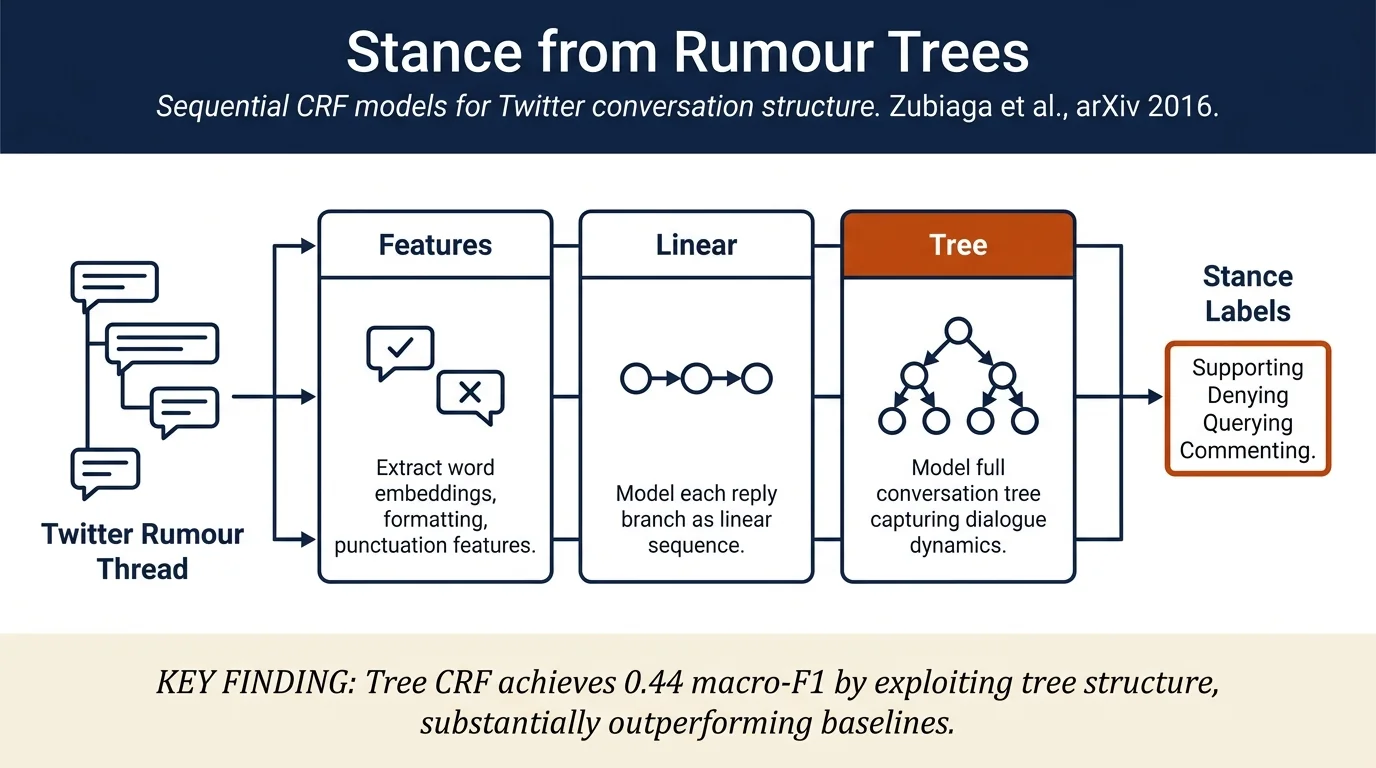
Proposes that modelling Twitter conversations as tree-structured sequences improves rumour stance classification. Introduces Linear and Tree Conditional Random Fields (CRF) to exploit the sequential structure of replies within rumour threads, showing that Tree CRF significantly outperforms non-sequential baselines on 4,519 annotated tweets across eight breaking-news events.
Contributions¶
- First to model Twitter conversational structure for stance classification at the tweet level
- Proposes two sequential classifiers: Linear CRF (models branches as sequences) and Tree CRF (models whole conversation as tree)
- Evaluates on 4-way classification task (supporting, denying, querying, commenting) using PHEME dataset with 4,519 tweets
- Demonstrates that exploiting conversational tree structure significantly improves macro-averaged F1 scores over non-sequential methods
- Shows Tree CRF performs best on source tweets and outperforms state-of-the-art approaches by capturing dialogue dynamics
Method¶
The paper frames rumour stance classification as a sequential learning task. Each rumour generates a tree-structured conversation of tweets, where replies nest under preceding tweets, forming branches. Key design choices:
Conditional Random Fields (CRF): Two variants to capture sequential dependencies: - Linear CRF: Models each branch independently as a linear sequence, useful for understanding how stances evolve within a single reply chain - Tree CRF: Models the entire conversation tree as a graph where vertices are tweets and edges represent reply relations, capturing global conversational dynamics
Features: Four feature types extracted locally from tweets: - Lexicon: 300-dim Word2Vec embeddings, POS tags, negation words, swear words - Content formatting: tweet length, capital ratio, word count - Punctuation: question marks, exclamation marks, periods - Tweet formatting: URL presence, image attachment, source-tweet indicator
Dataset: PHEME corpus with 8 breaking-news events (Ottawa shooting, Ebola, Ferguson, etc.), yielding 4,519 annotated tweets. The annotation scheme adapts labels to supporting/denying (for source tweets) and supporting/denying/querying/commenting (for replies), converting crowdsourced data accordingly. Class distribution heavily skewed toward commenting (63% of tweets).
Results¶
Macro-averaged performance (primary metric for imbalanced data): - Tree CRF: 0.440 macro-F1 - Linear CRF: 0.433 macro-F1 - Maximum Entropy: 0.400 macro-F1 - Naïve Bayes, SVM, Random Forest: 0.203–0.357 macro-F1
Tree CRF achieves statistically significant improvements over Linear CRF and substantially outperforms all non-sequential baselines. Particularly strong on supporting (0.462) and querying (0.435) classes; struggles with denials (0.088 F1), a minority class (7.6% of tweets). Macro-averaged F1 by event ranges 0.384–0.518.
Performance by tweet depth: Tree CRF consistently outperforms Linear CRF and baselines across most conversation depths (source tweet to 9+ levels deep), suggesting sequential structure helps at all levels.
Connections¶
- Related to SemEval-2017 Task 8: RumourEval: Determining rumour veracity and support for rumours (shared PHEME dataset; RumourEval introduces the benchmark task)
- Builds on Kochkina et al. (same group; extends this with LSTM for fine-grained stance)
- Compared to concurrent work on stance using Hawkes processes for temporal sequences
- Foundational for RumourEval shared tasks incorporating stance sub-tasks
Notes¶
Strengths: - First to rigorously exploit conversational structure for tweet-level stance; novel architecture choice validated empirically - Clear feature design and reproducible 8-fold cross-validation on realistic, imbalanced data - Tree CRF vs Linear CRF ablation cleanly shows the benefit of modelling the full tree over linear branches
Weaknesses: - Strong imbalance toward commenting class (63%) limits practical utility for minority classes (denials perform poorly) - Uses only local tweet features; conversational context features might help further - Limited to 8 English-language events; generalization to other languages/event types unclear - Does not compare to contemporary sequential methods (e.g., RNNs/LSTMs) and relies on hand-crafted features
Future directions: Authors suggest LSTM architectures and contextual features as promising extensions; multi-event cross-domain transfer remains open.