Recurrent Convolutional Strategies for Face Manipulation Detection in Videos¶
Authors: Ekraam Sabir, Jiaxin Cheng, Ayush Jaiswal, Wael AbdAlmageed, Iacopo Masi, Prem Natarajan Affiliation: USC Information Sciences Institute Venue: arXiv:1905.00582, May 2019
TL;DR¶
This paper proposes using recurrent convolutional networks to detect face manipulations (Deepfake, Face2Face, FaceSwap) in videos by exploiting temporal discrepancies across frames. Face preprocessing with alignment and bidirectional recurrent networks achieve state-of-the-art on FaceForensics++ with up to 4.55% improvement over prior work.
Contributions¶
- A two-stage pipeline for face manipulation detection: face detection/cropping/alignment followed by recurrent-convolutional analysis
- Exploration of face alignment techniques (landmark-based and spatial transformer networks) for removing confounding factors
- Analysis of backbone architectures (ResNet, DenseNet) combined with bidirectional recurrent networks for temporal anomaly detection
- Comprehensive evaluation on three manipulation types (Deepfake, Face2Face, FaceSwap) on the FaceForensics++ benchmark
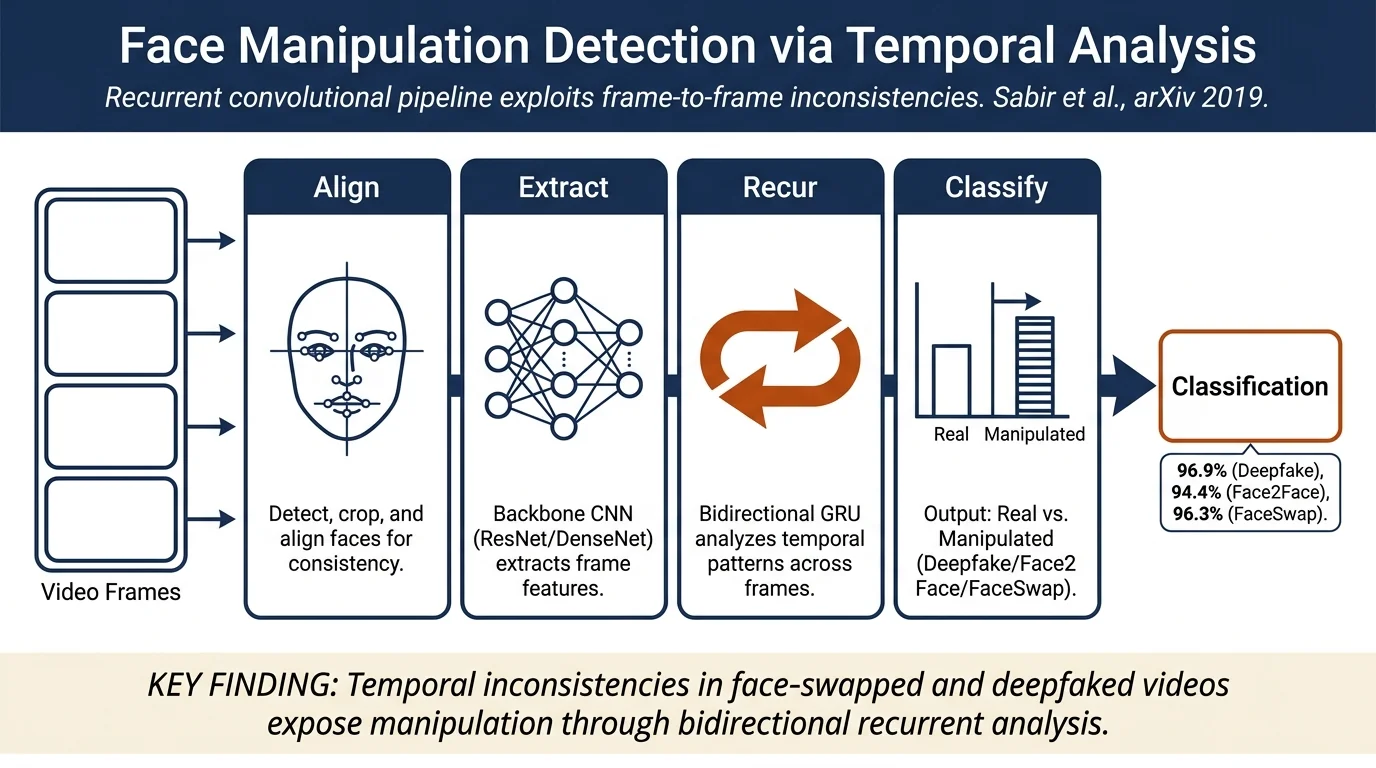
Method¶
The approach has two stages: preprocessing and manipulation detection.
Face preprocessing: Faces are detected, cropped, and aligned to create face "tubelets" (aligned sequences across frames). Two alignment strategies are explored: (1) explicit landmark-based alignment using sparse facial landmarks to compensate for rigid motion, and (2) implicit alignment via Spatial Transformer Networks (STN) that learn affine transformation parameters.
Manipulation detection: A recurrent-convolutional model exploits temporal discrepancies. The backbone CNN (ResNet or DenseNet) extracts frame-level features, which are then processed through GRU (Gated Recurrent Unit) cells in a bidirectional configuration. The key intuition is that frame-by-frame manipulation artifacts manifest as temporal inconsistencies—face-swapping and reenactment tools do not enforce temporal coherence in the synthesis process, producing flickering artifacts detectable through temporal analysis.
The paper experiments with two recurrence strategies: single recurrent network on top of backbone features, and multi-level recurrence extracting features at different CNN hierarchy levels (mesoscopic approach). End-to-end training optimizes the combined system.
Results¶
Evaluation on FaceForensics++ (1,000 videos, 720 train, 140 validation, 140 test) shows:
- Deepfake: 96.9% accuracy (DenseNet + alignment + bidirectional RNN on 5 frames)
- Face2Face: 94.35% accuracy (same configuration)
- FaceSwap: 96.3% accuracy (same configuration)
The ablation studies demonstrate: - DenseNet consistently outperforms ResNet for this task - Face alignment provides consistent improvement (up to 2% for some tasks) - Using multiple frames (5-frame sequences) substantially improves over single-frame input - Bidirectional recurrence outperforms unidirectional recurrence - Multi-level recurrence and STN-based alignment, contrary to intuition, hurt performance (likely due to increased parameter count and limited training data)
Connections¶
- Builds on MesoNet mesoscopic approach for feature hierarchy
- Cited by and contemporaneous with DFDC dataset work on deepfake detection
- Related to Korshunov & Marcel deepfake threat analysis
- Complements Video Forensics and Deepfake Detection research domains
Notes¶
This work makes a strong case for temporal analysis in video manipulation detection, moving beyond frame-by-frame approaches. The finding that bidirectional recurrence is essential (and that multi-level recurrence surprisingly hurts performance) is noteworthy—the authors attribute the latter to overfitting on the relatively small FaceForensics++ dataset (1,000 videos). The emphasis on face alignment as a preprocessing step is practical and well-motivated. The method is evaluated only on compressed video quality, so generalization to high-quality deepfakes remains an open question.