MesoNet: A Compact Facial Video Forgery Detection Network¶
Authors: Darius Afchar, Vincent Nozick, Junichi Yamagishi, Isao Echizen Venue: arXiv, 2018 — arXiv:1809.00888
TL;DR¶
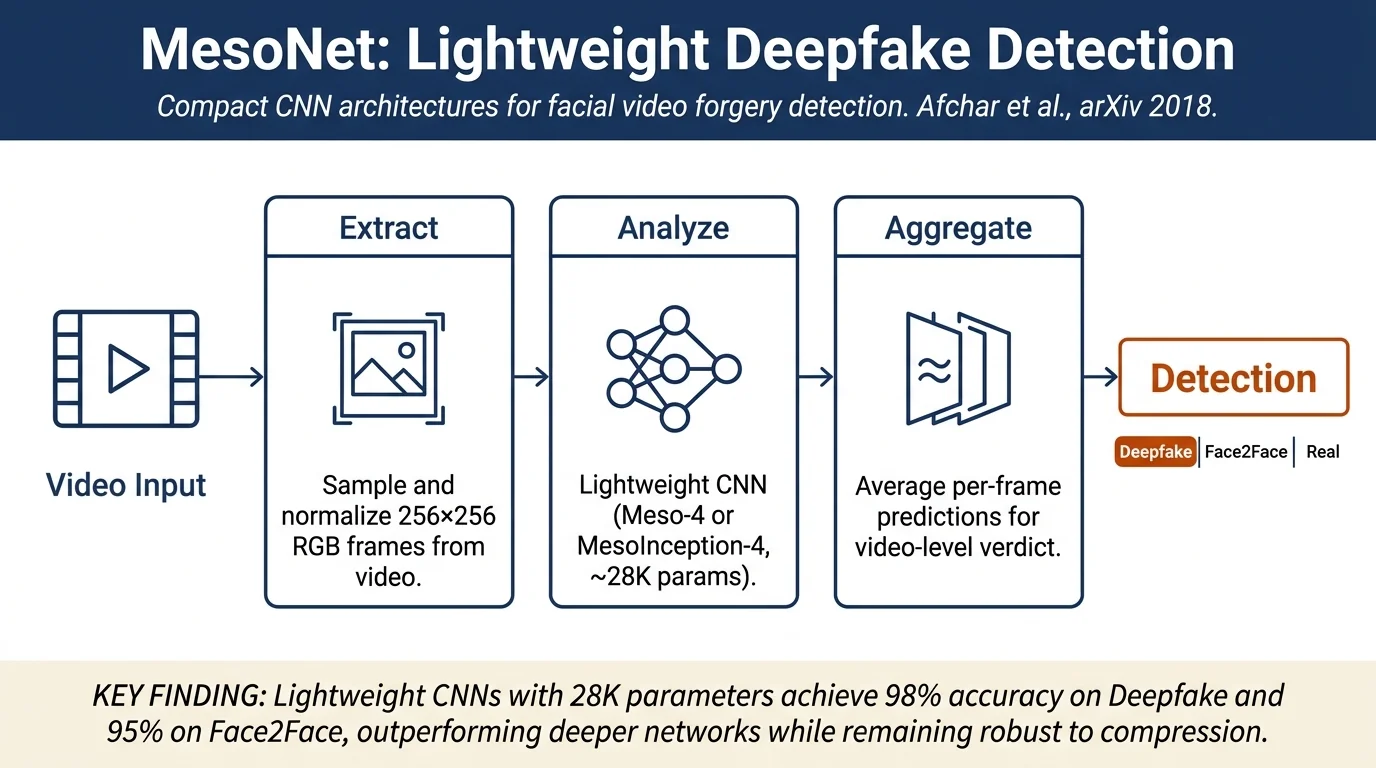
This paper proposes two lightweight CNN architectures (Meso-4 and MesoInception-4) to detect facial video forgeries created by Deepfake and Face2Face techniques. Operating at the mesoscopic level of image analysis, the networks achieve 98% detection accuracy for Deepfake and 95% for Face2Face videos under realistic compression conditions. The authors also introduce the first publicly available Deepfake detection dataset.
Contributions¶
- Two efficient CNN architectures specifically designed for deepfake and Face2Face video detection at the mesoscopic level
- First publicly available dataset of videos generated with the Deepfake technique
- Demonstration that lightweight networks with few parameters (~28K) outperform more complex architectures for this task
- Analysis of network robustness to video compression at different levels
- Interpretability analysis showing that eyes and mouth features are critical for detecting Deepfake forgeries
Method¶
Detection Strategy: The authors position their method at the mesoscopic level of analysis—intermediate between microscopic signal-based analysis (which degrades with video compression) and semantic-level analysis (where humans struggle to distinguish forged faces). This avoids the compression artifacts that destroy traditional forensic signals while remaining below the semantic complexity where human perception fails.
Meso-4 Architecture: A simple four-layer convolutional network followed by a dense layer with one hidden unit. Uses ReLU activations and batch normalization for regularization. Total of 27,977 trainable parameters. Input size 256×256×3, outputs binary classification (forged/real).
MesoInception-4 Architecture: Replaces the first two convolutional layers of Meso-4 with modified inception modules using 3×3 dilated convolutions (rather than 5×5) to avoid high semantic information. Includes 1×1 convolutions for dimension reduction and skip connections. Total of 28,615 trainable parameters.
Training: Both networks trained with Adam optimizer (learning rate 10^-3 decaying to 10^-6 over 1000 iterations). Batch size 75, input images 256×256×3. Data augmentation via random zoom, rotation, horizontal flips, brightness and hue changes. Training completes in hours on consumer-grade hardware.
Results¶
Deepfake Detection: On their collected dataset of 175 forged videos and real faces: - Meso-4: 89.1% accuracy (per-frame), 96.9% with video aggregation - MesoInception-4: 91.7% accuracy (per-frame), 98.4% with video aggregation
Face2Face Detection: On the FaceForensics dataset with H.264 compression: - Compression level 0 (lossless): 96.8% (MesoInception-4) - Compression level 23 (light): 93.4% (MesoInception-4) - Compression level 40 (strong): 81.3% (MesoInception-4)
Video-level aggregation (averaging predictions across frames) significantly improves performance, achieving 95.3% on Face2Face at moderate compression.
Connections¶
- Related to FaceForensics++ as a baseline detection method on their standardized dataset
- Cited by Deepfake Detection Survey as foundational work in CNN-based deepfake detection
- Relevant to Deepfake Detection techniques and Facial manipulation detection methods
- Builds on Face Reenactment understanding by detecting Face2Face forgeries
Notes¶
Strengths: - Demonstrates that lightweight networks can match or exceed complex architectures for this task, making detection practical - First systematic analysis of Deepfake detection; the Deepfake tool had not been published academically at this time - Good interpretation of what networks learn: eyes and facial details are preserved in real faces but blurred in Deepfakes due to autoencoder compression - Addresses practical video compression effects, showing robustness even at strong compression levels
Limitations: - Deepfake dataset is relatively small (175 videos) compared to modern benchmarks - Performance degrades significantly at high compression levels (81% for Face2Face at level 40) - No comparison with other deepfake detection methods (as none existed at publication time) - Limited to detecting two specific forgery techniques; generalization to other deepfake tools unclear
Follow-ups: - Later work would explore ensemble methods and cross-compression generalization - The dataset approach influenced subsequent work on FaceForensics and other large-scale forgery benchmarks - MesoNet architectures became baseline detectors for many subsequent deepfake papers